






浅谈广告归因
|0x00 什么是广告归因
广告归因是一个比较特定的业务场景,其定义为“用户旅程中所经历的不同营销渠道的不同接触点对达成转化目标的贡献价值评估。”听起来比较绕,但如果结合一个具体的例子,理解起来就比较明确。
某天,你在刷抖音,刷出了一条淘宝的广告(1),卖的是三只松鼠的零食。你点了一下,跳转到了淘宝的购买详情页(2),但感觉这款零食并不符合你的口味,于是点了一下店铺链接,进入了三只松鼠的旗舰店(3)。在首页上,发现了有一款核桃的广告比较不错(4),价格很便宜,你点了进去(5),点击了购买(6)。
在刚才的过程描述里,1、4、5直接涉及到广告,被称为“广告事件”;而2、3、6虽然也跟广告有关,但并不是具体的广告动作或结果,因此被称为“转化事件”。在上述的例子中,你访问了两个不同的平台,看过了两次不同的广告,最终完成了购买。如果我们要分析这次购买是因为哪次广告或者哪个平台引流过来的,就需要在数据上完整的复现刚才的过程。而广告归因统计,就是针对这个过程进行统计,例如首次点击归因(转化效果归因为第一次产生点击的渠道,也就是抖音)、最终点击归因(转化效果归因给最后一次点击的渠道,也就是淘宝旗舰店首页广告),等等。
因此,广告归因看的就是“什么事情归属于谁的状态或者关系”。
|0x01 广告归因统计流程是怎样的
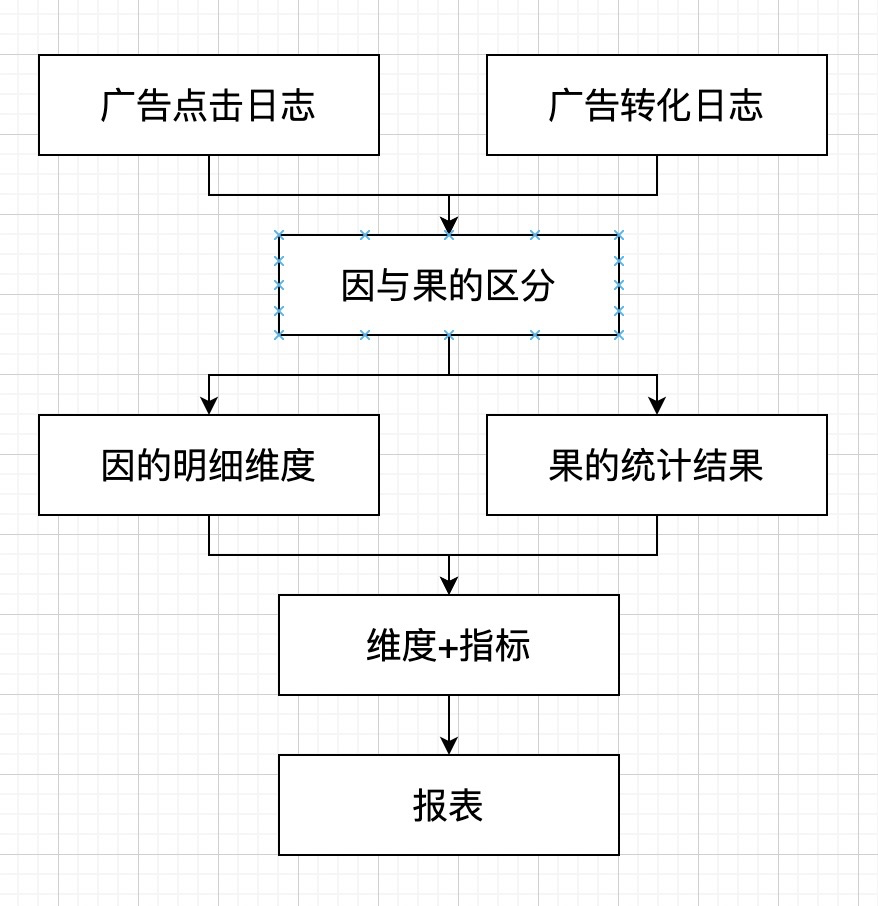
归因归因,离不开“因”和“果”。“因”一般指的是广告点击行为,比如点击了抖音的广告;“果”一般指的是广告投放活动所产出事件,比如你最终购买了商品。由于广告日志的量通常比较大,每天增量以TB计,因此在归因之前,需要我们首先通过限定条件来对行为进行分类。例如type = '购买',就意味着只有购买动作算作是“果”,而进入店铺动作就不算是“果”。
有了“因”和“果”的区分,后续的统计就比较易于理解,就是基于“因”的各种维度明细,和基于“果”的各种统计指标。
简化的流程图如下:
|0x02 归因计算需要关注哪些信息
广告归因通常需要关注如下几个方面的问题:
目标:归因的目标是判断产生用户产生目标行为的原因是什么,是因为展示了广告,还是因为点击了广告;
周期:用户产生行为的周期是怎样的,是立刻产生影响,还是间隔了几分钟;
原则:当用户发生目标行为后,这次行为之前伴随了几次广告展现,每次展现的贡献是怎样的。
总的来说,通过目标、周期和原则,就能够判断每个广告渠道对于最终结果的贡献。
因此在报表统计上,我们需要体现如下几个方面的因素:
周期:分钟、小时、日等粒度的数据统计;
原则:包括首次触达归因、末次触达归因、线性归因等;
指标:点击、展现、计费等情况;
粒度:计算结果时需要额外关联的维度。
|0xFF ROI解读
ROI的定义是通过投资而应返回的价值,即企业从一项投资活动中得到的经济回报。在广告行业中,我们需要考察广告投入了多少钱,能够回报多少,以此来衡量我们投放广告的价值如何。
但广告投放往往不是一次生效的,而是多种策略和时间影响组合的结果。因此如何判断归因的权重,能够帮助ROI更加准确的计算。通常而言,我们会通过多触点(也称多渠道)归因,来更准确地衡量营销策略的整体影响力。
多触点通常由两种原则:规则和算法。规则就是根据预先与业务方约定好的规则,根据频率、时间和广告主观价值,来分配每次触点的价值。算法是根据客户过往的历史行为,对各种互动分配权重数值,并持续优化权重分配方法。
如果仅仅衡量最后一次触点,来判断广告的价值,从逻辑上讲当然更简单,但只有将归因拆的更细,我们才能做出更有效的广告洞察。

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









