







一、定义函数
定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return相当于返回 None。
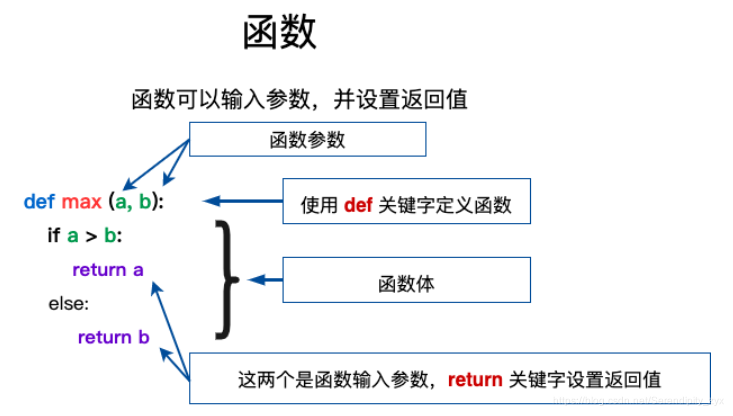
一个简单的函数:
def hello():
print("Hello World!")
hello()
## 结果为Hello World!
一个简单的传参函数:
# 比较两个数,选择一个最大的
def max(a, b):
if a > b:
return a
else:
return b
a = 4
b = 5
print(max(a, b))
## 结果为5
【补充】函数式编程和面向过程编程的区别:
函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
面向对象:对函数进行分类和封装,让开发“更快更好更强…”
二、函数参数
1. 普通参数
1.形参变量只有在被调用时才分配内存单元,在调用结束后,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
2.实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此,应预先使用赋值、输入等办法使用参数获得确定值。
3.实参与形参位置一一对应。

2. 默认参数
def func(name, age=18):
print("%s:%s" % (name, age))
# 指定参数
func('wupeiqi', 19)
# 使用默认参数
func('alex')
## 结果为wupeiqi:19
## alex:18
def func(*args):
print(args)
# 执行方式一
func(11, 33, 4, 4454, 5)
# 执行方式二
li = [11, 2, 2, 3, 3, 4, 54]
func(*li) # 遍历列表中的元素
## 结果为(11, 33, 4, 4454, 5)
## (11, 2, 2, 3, 3, 4, 54)
3. 动态参数:
# 参数组:**字典 *列表
def test(x, *args):
print(x)
print(args)
test(1, ['z', 'y', 'z']) # 将列表当成一个整体传给args
## 结果为1
## (['z', 'y', 'z'],)
test(1, *['z', 'y', 'z']) # 加*可以遍历取到其值
## 结果为1
## ('z', 'y', 'z')
一个简单的例子:
def test(* params):
print('参数的长度是:', len(params))
print('第二个参数是:', params[1])
test(1, 'zhai', 2000, [2, 5, 0]) # 打包成元组传给* params
## 结果为 参数的长度是: 4
## 第二个参数是: zhai
位置参数和关键字:
def test(x, *args, **kwargs):
print(x)
print(args)
print(kwargs)
test(1, 2, 3, 1, 1, y=2, z=6) # 位置参数和关键字
## 结果为1 位置参数一一对应
## (2, 3, 1, 1)
## {'y': 2, 'z': 6} 关键字传值
三、函数返回值
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,以下实例演示了 return 语句的用法:
# 定义求和函数
def sum(arg1, arg2):
# 返回2个参数的和."
total = arg1 + arg2
print("函数内 : ", total)
return total
# 调用sum函数
total = sum(10, 20)
print("函数外 : ", total)
四、局部变量与全局变量
局部变量的作用域在函数内。
count = 0 # 定义全局变量count
def MyCount():
count = 100000 # 函数内部定义的变量作用域在函数内
print(count)
print(count) # 在函数外值仍未改变 #结果为0
MyCount() ## 100000
若想在函数内部使用全局变量,必须在前面加上global。
count = 0 # 定义全局变量count
def MyCount():
global count # 使用全局变量count
print(count)
print(count) ## 结果为0
MyCount() ## 0
五、嵌套函数和闭包
1. 嵌套函数
python支持在函数内定义另一个函数。
def func1():
print("func1 is running!")
def func2():
print("func2 is running!")
func2()
func1() # 调用func1方法
## 结果为func1 is running!
## func2 is running!
如果直接调用func2方法会出现如下所示的情况,编译器无法找到对应的func2方法,于是它认为该方法没有被定义。

2. 闭包
简单来说就是一个函数定义中引用了函数外定义的变量,并且该函数可以在其定义环境外被执行。这样的一个函数我们称之为闭包。
一个简单的例子:
def fun_x(x):
def fun_y(y):
return x * y
return fun_y # 此处不加括号是为了返回函数值
# 第一种赋值方式
res = fun_x(2)
print(type(res)) # 这里的res是一个函数类型,所以我们还需要对它进行调用
print(res(5))
# 第二种赋值方式
print(fun_x(2)(5))
运行结果为:
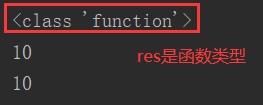
在嵌套函数的情况下,内部函数引用外部函数的局部变量。该例中,fun_y函数中引用了fun_x的局部变量x,所以fun_y函数就是闭包。fun_y是内部函数,fun_x是内部函数的外部作用域但不是全局作用域。
为了加深理解,引入了下一个例子:
def Fun1():
x = 5
def Fun2():
x *= x
return x
return Fun2()
Fun1()
上述的代码运行时会报错:UnboundLocalError: local variable ‘x’ referenced before assignment。赋值前引用了局部变量“x”,解释器不明白x是全局变量还是局部变量,也可能是局部变量同全局变量同名了。
【解决方案1】将变量改为列表类型。
因为函数变量的存储是放在栈里面的,而列表是不存在栈中的,所以列表元素可以被内置函数所引用。
def Fun1():
x = [5]
def Fun2():
x[0] *= x[0]
return x[0]
return Fun2()
print(Fun1())
## 结果为25
【解决方案2】使用nonlocal关键字。
nonlocal声明的变量不是局部变量,也不是全局变量,而是外部嵌套函数内的变量。
nonlocal关键字修饰变量后标识该变量是上一级函数中的局部变量,如果上一级函数中不存在该局部变量,nonlocal位置会发生错误(最上层的函数使用nonlocal修饰变量必定会报错)。
def Fun1():
x = 5
def Fun2():
nonlocal x # 只能用于嵌套函数中,并且外层函数中定义了相应的局部变量
x *= x
return x
return Fun2()
print(Fun1())
## 结果为25
六、匿名函数
python 使用 lambda 来创建匿名函数。所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。
函数只有一个参数的情况:
####################### 普通函数 ######################
# 定义函数(普通方式)
def ds(x):
return 2 * x + 1
print(ds(5))
## 结果为11
# 用lambda简化函数
g = lambda x : 2 * x + 1
print(g) # lambda返回的是函数类型
print(g(5))
## 结果为<function <lambda> at 0x000001C21921A280>
## 11
函数中有两个参数的情况:
def add(x, y):
return x + y
print(add(5, 7))
g = lambda x, y : x + y
print(g(5, 7))
## 结果为12
lambda表达式的作用:
- python写一些执行脚本时,使用lambda就可以省下定义函数过程,比如说我们只是需要写个简单的脚本来管理服务器时间,就不需要专门定义一个函数然后再写调用,使用lambda就可以使得代码更加精简。
- 简化代码的可读性,省去def步骤。
- 对于一些比较抽象并且整个程序执行下来只需要调用一两次的函数,有时候给函数起个名字也是比较头疼的问题,使用lambda就不需要考虑命名的东西。
七、递归
【例1】利用函数编写斐波那契数列(如下图所示)。

# 递归实现算出第n次的结果
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n - 2) + fibonacci(n - 1)
res = fibonacci(5)
print(res)
【例2】分别用递归方式和非递归方式实现求一个数的阶乘。
递归方法:
def factorial_recur(x):
if x == 1: # 记得写递归出口
return 1
else:
return x * factorial_recur(x - 1)
number = input("请输入一个正整数用来求其阶乘:")
res = factorial_recur(int(number))
print("%s的阶乘为%s" % (number, res))
## 输入5结果为120
非递归方法:
def factorial(x):
res = 1
for i in range(1, x+1):
res = i * res
print(res)
n = input("请输入一个正整数用来求其阶乘:")
factorial(int(n))
## 输入5结果为120
【例3】递归实现汉诺塔。
def Hanoi(n, a, b, c): # n代表盘子数,借助B从A移动到C
if n == 1: # 递归出口
print(a, '-->', c)
else:
Hanoi(n - 1, a, c, b) # 将前n-1个借助C从A移动到B
print(a, '-->', c) # 将最底下的一个盘子从A移动到C上
Hanoi(n - 1, b, a, c) # 将暂时存放在B上的前n-1个借助A放到C上
num = int(input("请输入汉诺塔的层数:"))
Hanoi(num, 'A', 'B', 'C') # 注意字符串实需加''符号
运行结果为:

八、内置函数

注:查看详细,点击官方说明文档
1. open( )函数
open函数用于文件处理。
操作文件时,一般需要经历如下步骤:①打开文件;② 操作文件
open打开文件
文件句柄 = open('文件路径', '模式')
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读;不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件:
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作:
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型。
下图很好的总结了这几种模式:

class file(object)
def close(self): # real signature unknown; restored from __doc__
关闭文件
def fileno(self): # real signature unknown; restored from __doc__
文件描述符
return 0
def flush(self): # real signature unknown; restored from __doc__
刷新文件内部缓冲区
pass
def isatty(self): # real signature unknown; restored from __doc__
return False
def next(self): # real signature unknown; restored from __doc__
获取下一行数据,不存在,则报错
pass
def read(self, size=None): # real signature unknown; restored from __doc__
读取指定字节数据
pass
def readinto(self): # real signature unknown; restored from __doc__
读取到缓冲区,不要用,将被遗弃
pass
def readline(self, size=None): # real signature unknown; restored from __doc__
仅读取一行数据
pass
def readlines(self, size=None): # real signature unknown; restored from __doc__
读取所有数据,并根据换行保存值列表
return []
def seek(self, offset, whence=None): # real signature unknown; restored from __doc__
指定文件中指针位置
pass
def tell(self): # real signature unknown; restored from __doc__
获取当前指针位置
pass
def truncate(self, size=None): # real signature unknown; restored from __doc__
截断数据,仅保留指定之前数据
pass
def write(self, p_str): # real signature unknown; restored from __doc__
写内容
pass
def writelines(self, sequence_of_strings): # real signature unknown; restored from __doc__
将一个字符串列表写入文件
pass
def xreadlines(self): # real signature unknown; restored from __doc__
可用于逐行读取文件,非全部
pass
2. filter( )函数
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将下划线返回 True 的元素放到新列表中。
语法格式为:
filter(function, iterable)
# function -- 判断函数
# iterable -- 可迭代对象
# 返回值为一个迭代器对象
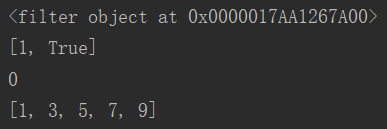
一个简单的例子:
v1 = filter(None, [1, 0, False, True])
print(v1) # 返回了一个过滤器对象
v2 = list(filter(None, [1, 0, False, True])) # 转换成list类型
print(v2) # 过滤掉为0和False的值
def odd(x):
return x % 2 # 如果是偶数的话,返回的就是0;有返回值1的都是奇数
v3 = print(odd(10)) # 10是偶数,所以返回0
v4 = list(filter(lambda x : x % 2, range(10)))
print(v4)
运行结果为:
3. map( )函数
map() 函数会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
一个简单的例子:
def square(x): # 计算平方数
return x ** 2
v1 = list(map(square, [1, 2, 3, 4, 5])) # 计算列表各个元素的平方
print(v1)
## 结果为[1, 4, 9, 16, 25]
v2 = list(map(lambda x: x ** 2, [1, 2, 3, 4, 5]))
print(v2) # 输出的结果是把range(10)中每个对象放入前面的函数中做处理,再输出
## 结果为[1, 4, 9, 16, 25]















 1056
1056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









