







在前面的 字符集编码系列 中, 已经探讨了几大主要的字符集编码. 在此基础之上, 这里将进一步探讨编码的应用及乱码的根源, 我们先从基本的文件说起.
文件
文件(内容)就是字节序列. 文本文件也是文件, 所以它也是字节序列.
文件名与文件内容
通常说到文件时, 指的是 文件内容, 但文件还有 文件名, 文件名与文件内容是分开存储的. 你可以在硬盘上新建一个文件, 它的大小为 0. 如下:

但它是有文件名的, 比如上述的"新建文本文档.txt", 保存这些名字自然也要占用空间, 只不过它与文件内容是分离的.
这些由操作系统的文件系统模块负责.
文件名是一段文本, 因此它会涉及字符集编码. 文件内容则视情况而定:
-
文本文件, 肯定会涉及字符集编码.
常见的比如 txt, html, xml 以及各种源代码文件等等.
-
非文本文件, 比如图片文件 jpg, gif 之类, 自然跟字符集编码无关了.
有些文件, 比如 Word 的 doc 之类的, 混合了图片跟文本在里面, 可以想像, 其中的文本部分自然也会牵涉到字符集编码的问题, 只不过这些编码不由我们去控制, 我们通常也无须去关心.
文件名编码
文件名是一串文本, 因此它必然涉及某种字符集编码, 只不过这种编码是由操作系统决定的, 我们无权干预. 那么, 它用的是什么编码呢? 在 Windows 下, 可以简单做些实验. 我们可以弄些奇怪的文件名如"★★★★.txt", 如下:

结果也能保存. 这些字符只在 Unicode 中才有, 所以它肯定不是用的 GBK 之类的.
Windows NTFS 架构下文件名使用 UTF-16 编码.
但对于 FAT 之类的, 则是所谓的 “OEM character set”.
MSDN 上的原文如下: “NTFS stores file names in Unicode. In contrast, the older FAT12, FAT16, and FAT32 file systems use the OEM character set”(NTFS 使用 Unicode 存储文件名. 与此相对, 老的 FAT12, FAT16 和 FAT32 文件系统使用 OEM 字符集).
参见: http://msdn.microsoft.com/en-us/library/windows/desktop/dd317748%28v=vs.85%29.aspx
注: 在 Windows 语境中, UTF-16 通常叫成 Unicode.
结合实验的结果, 可以确定, Windows 使用 UTF-16 对文件名进行编码.
测试当时我的系统是 Win 7, 文件系统为 NTFS.
不过, 不同的系统平台可能使用了不同的编码. 比如最新的 Linux 平台对文件名采用了 UTF-8 编码, 但早期的则不好说, 甚至没有一个标准.
如果你不是 Windows 平台, 你也可以简单做些实验来大致猜测一下文件系统使用的编码.
文件的上传下载与文件名乱码
由于对文件名没有一个统一的编码, 不同系统平台间交换文件时, 中文文件名极易发生乱码现象.
比如 FTP 上传, 网页文件上传及下载等情况下经常能遇到文件名乱码.
不过, 需要注意的是, 交换过程中, 文件内容 不会发生任何改变. 即便是文本文件, 也完全是字节传送, 不会涉及任何的编解码.
你可能碰到过这样的事, 把一个文本文件从 Windows 平台上传到 Linux 平台, 并在 Linux 平台下打开时发现乱码了, 但这不意味着文件内容有了什么变化, 通常的原因是你的文件是用 GBK 编码的, 但 Linux 平台下打开时它缺省可能用的是 UTF-8 编码去读取, 因此, 你只要调整成正确的编码去读取即可.
在这里, 我们讨论了文件名的编码, 之后, 如无特别说明, 谈到编码时均指对文件内容的编码. 通常, 这是我们更为关心的内容.
非文本文件中的字符集编码
通常, 说到字符集编码都是对文本文件而言的, 但非文本文件也是可能用到字符集编码的.
比如, Word 用什么编码? Word 生成的 doc 或者 docx 虽然不是文本文件, 但我们可以想像, 它里面可能有图像, 又有文字. 其中的文字自然也会用到某种编码. 只不过, 这些都不需要我们去操心.
下面是一个实验, 新建一个空白的 doc 文档, 录入几个简单字符"Hello你好"

保存成 doc 文件, 再用 notepad++ 打开, 以十六进制形式查看:

如上图, 搜索到 hello 几个关键字, 我们知道, “H” 的码点是 U+0048, 而"你"的码点则是 U+4F60, 所以, 很显然, 用的是 UTF-16 LE(Little Endian, 小端序)编码.
关于端序及 BOM 的相关话题, 可参见 字符集与编码(七)–BOM
注意, 这只是我个人在本机测试的结果, 不代表普遍的结论, 不同平台不同版本下的可能会有差异, 谁知道呢? 我没有去研究过 doc 文件格式的规范, 这个 doc 我还是用 WPS 生成的!
又比如, Java 中的 class 文件, 它也不是文本文件, 通常称为字节码文件. 但它里面也会保存 String 的常量, 这自然又要牵涉到编码. 实际用的是所谓的 modified UTF-8 编码.
对于 char 常量则是用 UTF-16 编码.
简单建立一个 java 文件, 定义一个 string 常量 “Hello你好”:
public class Foo {
static final String HI = "Hello你好";
}
保存并用 javac 命令编译得到 class 文件, 再次用 notepad++ 打开并以十六进制形式查看:
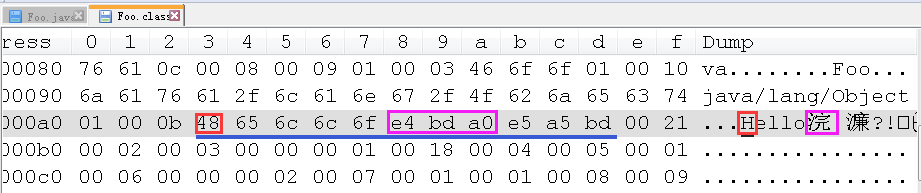
搜索到 Hello 几个关键字, 紧接在它们后面的 “e4 bd a0” 就是"你"的 UTF-8 编码了.
在前面的 字符集与编码(四)–Unicode 中, 曾提到过, 汉字的 UTF-8 编码通常都是以 e 打头, 形如 “ex xx xx ex xx xx…” 这样, 这是常用汉字 UTF-8 编码的一个重要特征.
这个 “modified UTF-8” 编码与 UTF-8 类似, 但有一些差别, 它的名字也暗示了这一点.
比如对于 U+0000 它用了两字节来编码;
还有对 U+FFFF 以上的字符它采用了 6 字节编码而非正常 UTF-8 的四字节编码, 实质是对代理对(surrogate pairs)的值进行编码.
详情可参见http://docs.oracle.com/javase/7/docs/api/java/io/DataInput.html#modified-utf-8
文本文件中的字符集编码
文本文件也是文件, 所以它也是字节序列. 当读取一个文本文件时, 最重要的是确定它所使用的编码, 只有这样才能正确的解码.
由于牵涉的情况较多, 我们将在下一篇讨论这一问题.














 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









