







动手学深度学习-李沐:04 数据操作 + 数据预处理【动手学深度学习v2】_哔哩哔哩_bilibili
动手学深度学习-李沐(pdf):2. 预备知识 — 动手学深度学习 2.0.0 documentation (d2l.ai)
更像是对迷惑知识点的补充,比较单看李沐的书有些python知识还是有点费解
⭐这是jupyter与torch结合的笔记!!!
目录
1. 数据操作
1.1. 数组
(1)N维数组样例
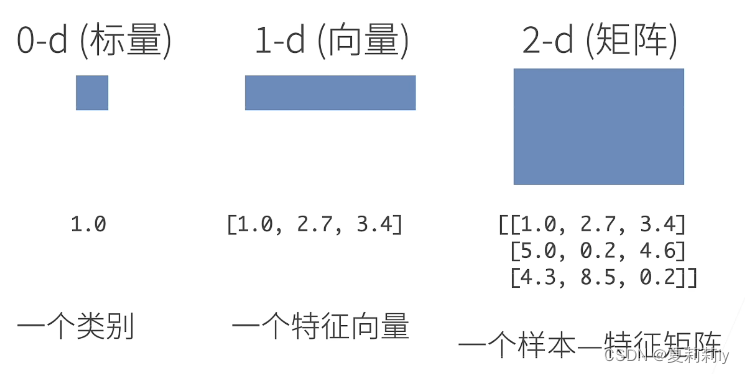
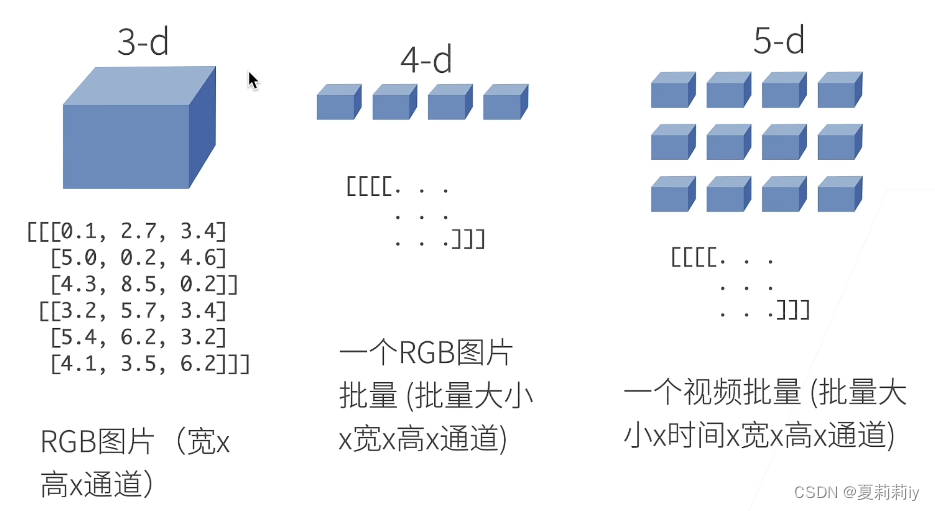
(2)访问元素
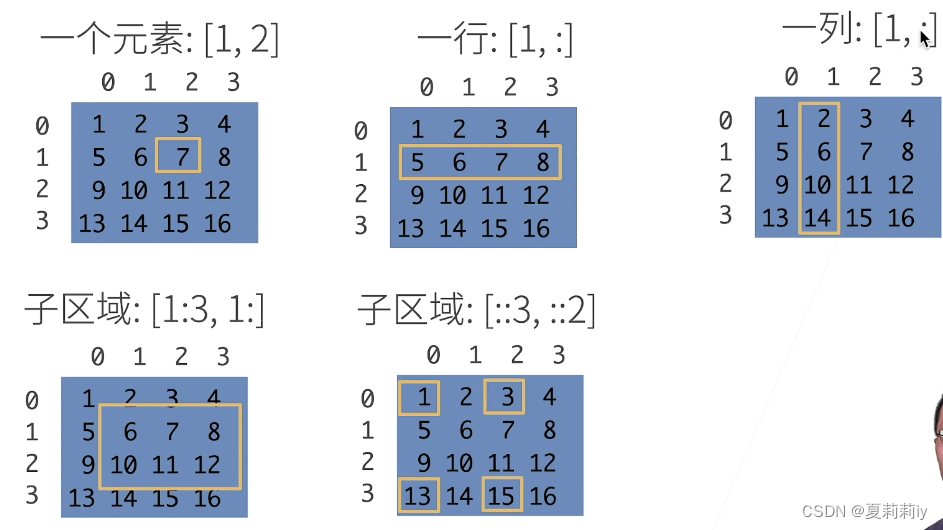
①这个一列感觉是写错了,应该是[:,1]
②python的区间是左闭右开
③子区域例子意思是每三行一跳,每两列一跳,左边可以带两个参数,即限定行列范围
(3)创建数组(???)
①注意在jupyter里,torch.tensor会有最外层一个小括号,内层一个中括号,在表示行的时候再增添中括号
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])②而二维创建时有如下例子
torch.randn(3, 4)③三维会多一个括号
torch.ones((2, 3, 4))④表示Z和Y的形状一样,但是Z里面全是0
Z = torch.zeros_like(Y)⑤Z里面所有的元素都是X与Y的点加
Z[:] = X + Y1.2. 运算符
(1)若x和y为同维度张量,则x与y的运算都为点加/点减/点乘/点除(即其中每个元素的运算,而不是两个矩阵相乘)
(2)x**y为以x内每个元素为底,做幂次分别为y每个元素的求幂运算
(3)张量连结
torch.cat((X, Y), dim=0)
torch.cat((X, Y), dim=1)
①dim=0为x与y以行为维度连结
②dim=1为x与y以列为维度连结
(4)张量广播机制:形状不同的张量可以复制自己并相加
①应该只能针对张量,做如下测试,知矩阵的广播失败了
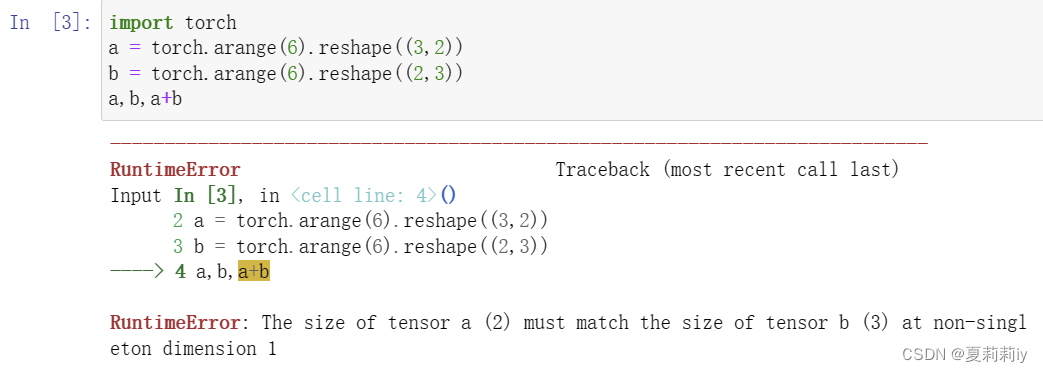

(5)矩阵的索引和切片
①对于二维数组来说,X[-1], X[1:3]分别是取最后一行和第一行到第二行
②对于二维数组来说,X[0:2, :] = 12可以多个元素赋值,也可以单个索引赋值
(6)节省内存
①id()有点像指针类型,可以用变量把它原来的地址存起来
before = id(Y)
②矩阵在进行运算的时候会改变位置,如下代码,Y会地址变更
Y = Y + X③如果是Y[:]=X+Y或X+=Y则不会变更地址
④⭐reshape并不会更改地址

⑤python会自动释放内存,不用像c语言要担心malloc()和free()
(7)转换对象
①torch与NumPy张量互转

②将大小为1的张量转换为Python标量

2. 数据预处理
2.1. 读取数据集
(1)import os的os实际上为operation system,且不能使用from os import *。os的方法为:(11条消息) python——操作系统(os)_from os.path import join as ojoin_Treasured _的博客-CSDN博客
(2)pandas库:Pandas库(一) - 木田心 - 博客园 (cnblogs.com)
(3)写文件的各种细节有点麻烦惹,现在记不住,要记忆可以就看李沐pdf
(4)Python一般默认64位浮点数,但对于深度学习来说64位计算有点慢,因此在后期深度学习多用32位
3.线性代数
3.1. 标量
(1)没什么好标的,单个数字罢了
3.2. 向量
(1)向量的长度

3.3. 矩阵
(1)范数
L0范数是指向量中非0的元素的个数。(L0范数很难优化求解)。
L1范数是指向量中各个元素绝对值之和。
L2范数是指向量各元素的平方和然后求平方根。F范数是指矩阵各项元素的绝对值平方的总和开根
L1范数可以进行特征选择,即让特征的系数变为0。
L2范数可以防止过拟合,提升模型的泛化能力,有助于处理 condition number不好下的矩阵(数据变化很小矩阵求解后结果变化很大)。
————————————————
原文链接:https://blog.csdn.net/vincent_duan/article/details/117305250
①L1范数代码
torch.abs(u).sum()②L2范数代码
torch.norm(a)③佛罗贝尼乌斯范数(F范数,Frobenius norm)代码
torch.norm(a)(2)哈达玛积(Hadamard product):数学符号为⊙,矩阵中每个元素单独相乘,类似matlab矩阵点乘,cij=aij×bij,在这里为A*B
(3)axis
①axis=0表示从纵轴从上到下
②axis=1表示从横轴从左到右
③有个很简单的做法,如原本是shape[2,5,4]的,然后按照axis=1求sum,可以直接把中间那个5去掉,后面的shape会变成shape[2,4]。甚至对它的axis=0和axis=2(代码为axis=[1,2])求和之后形状会变成shape[2](李沐在视频里面很奇怪的是二维axis是0和1,但三维的axis他给的是1,2,3,这应该是他的笔误。三维也应该是0,1,2)
④keepdims=True意思是不像③那样直接剔除一个维度,而是把那个维度变成1
(4)矩阵的降维
①A

②取列和
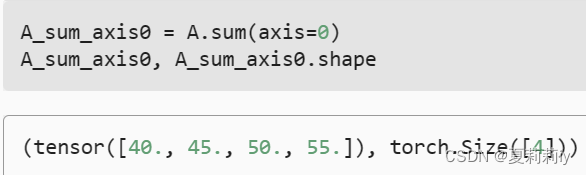
③取行和
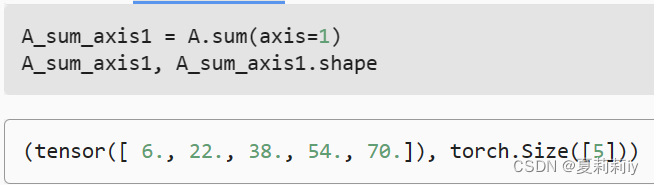
(5)矩阵的累加求和 A.cumsum(axis=0)或A.cumsum(axis=1),有点像一层一层叠加下去
(6)非降维求和
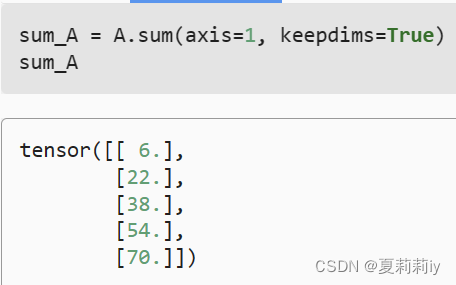
4. 微积分
4.1. 导数
(1)亚导数
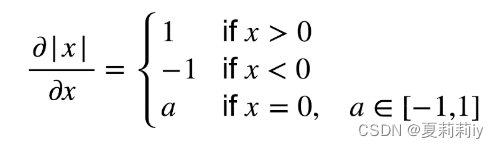
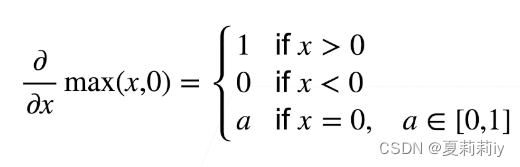
(2)导数与向量∂y/∂x
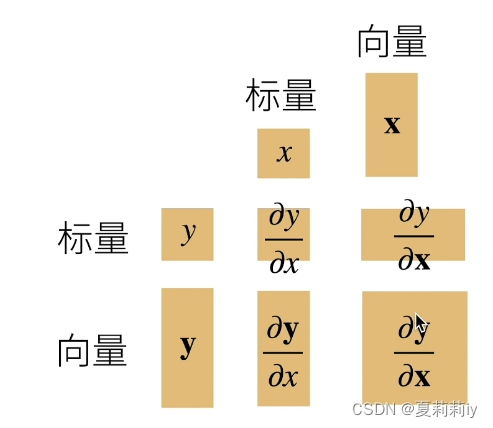
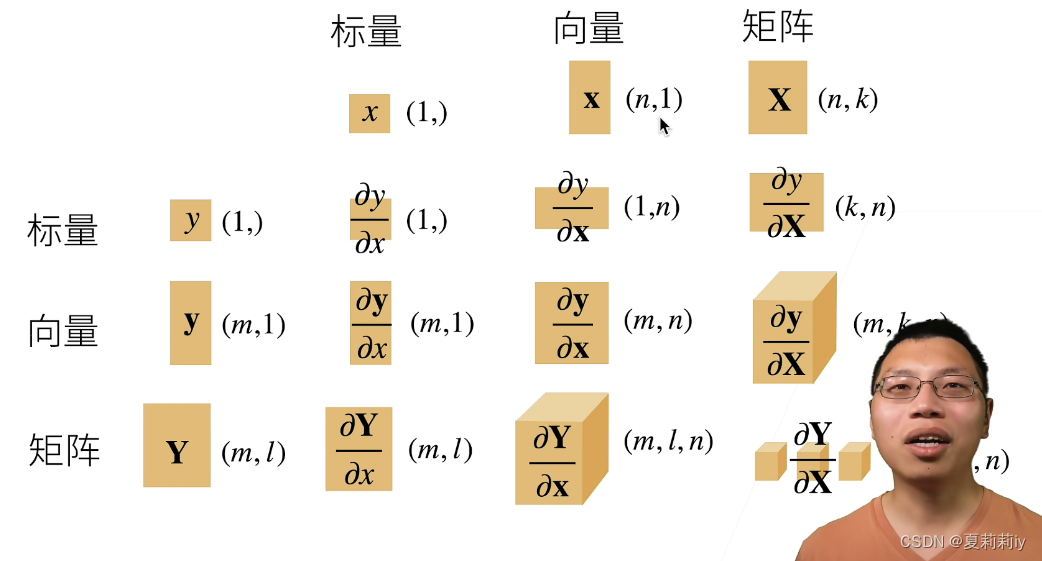
如果向量是在下面的话求导会导致最后的形状转置
4.2. 绘图代码
(1)使用svg格式在Jupyter中显示绘图,以获得更清晰的图片
def use_svg_display():
backend_inline.set_matplotlib_formats('svg')(2)print中含有f意为格式化字符串,使其中的{}可以使用,如
print(f'h={h:.5f}, numerical limit={numerical_lim(f, 1, h):.5f}')(3)设置图表大小(这个d2l包我还没有学习,不知道是不是李沐老师自己定义的)
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display() #调用上面那个函数
d2l.plt.rcParams['figure.figsize'] = figsize5.自动微分
5.1. 自动求导
(1)有别于符号求导和数值求导

(2)计算图
①将代码分解成操作子
②将计算表示成一个无环图
③显示构造:Tensorflow/Theano/MXNet
④隐式构造:PyTorch/MXNet
(3)自动求导的两种模式
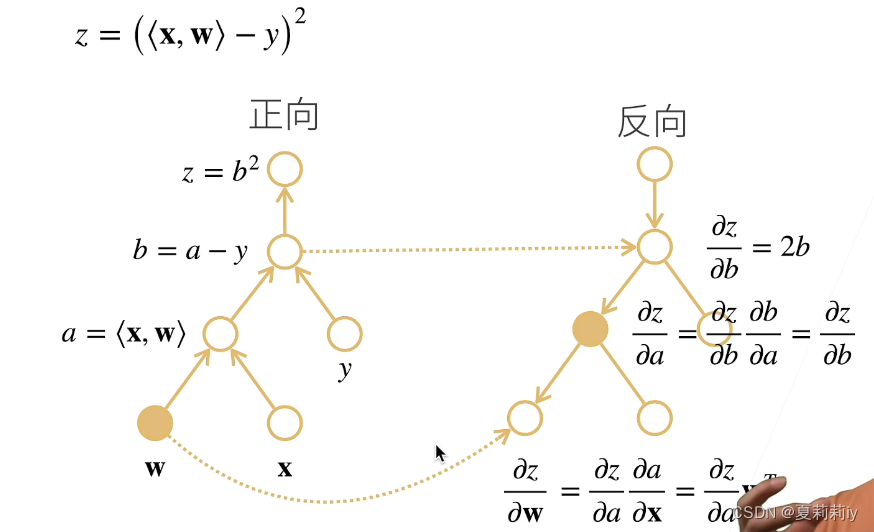
①正向累积
②反向累积/反向传递
③它们的计算复杂度都是O(n)
④正向累积的内存复杂度为O(n),因为需要存储正向的所有中间结果;反向累积的内存复杂度仅为O(1)
5.2. 自动求导实现
(1)需要一个地方来存梯度
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None(2)计算梯度
y.backward()
x.grad(3)梯度清零
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_()(4)将某些计算移动到记录的计算图之外(相当于detach()的意思是常数化)
u = y.detach()6. 概率
6.1. 基本概率论
(1)%matplotlib inline:是python中内嵌的魔法函数,这样在后面绘图可以直接plot()
(2)所以sample()是啥啊?百度只有sample(sequence,k),即从sequence中随机抽取k个并返回list
7. 查阅文档
7.1. 查找模块中的所有函数和类
(1)查找代码
print(dir())(2)类和函数的区别
①类就是class,是引用数据类型,是面向对象程序设计实现信息封装的基础
②函数是def的,只是一段连在一起执行的子程序
7.2. 查找特定函数和类的用法
(1)查找代码,其中括号里输入具体函数名,如torch.ones
help()














 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









