







一、什么是剪枝?
顾名思义,剪枝就是指将决策树的某些内部节点下面的节点都删掉,留下来的内部决策节点作为叶子节点。
二、为什么要剪枝?
决策树是充分考虑了所有的数据点而生成的复杂树,它在学习的过程中为了尽可能的正确的分类训练样本,不停地对结点进行划分,因此这会导致整棵树的分支过多,造成决策树很庞大。决策树过于庞大,有可能出现过拟合的情况,决策树越复杂,过拟合的程度会越高。
所以,为了避免过拟合,咱们需要对决策树进行剪枝。
一般情况下,有两种剪枝策略,分别是预剪枝和后剪枝。
下面还是通过西瓜这个例子来讲解。
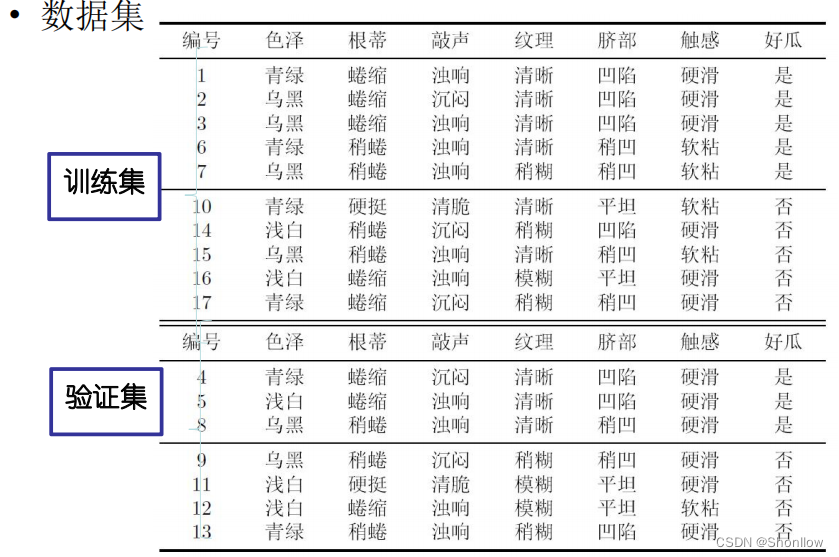
首先,先按照信息增益对这10个训练样本构造决策树,方法还是和上面的ID3算法提到的一样。
先计算最开始的训练样本的熵。好瓜有5个,坏瓜有5个,则信息熵为
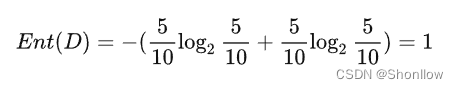
再计算按照各个属性划分后的信息熵:
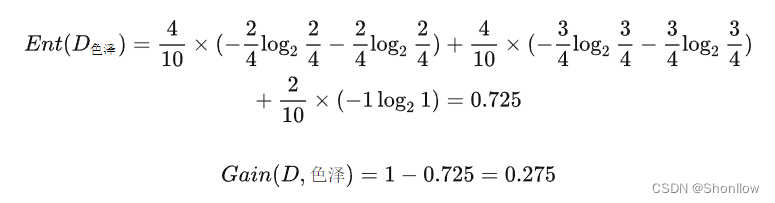
同理可得,

所以,选择脐部作为根节点。按照同样的思路,可以得到一颗为未剪枝前的决策树。
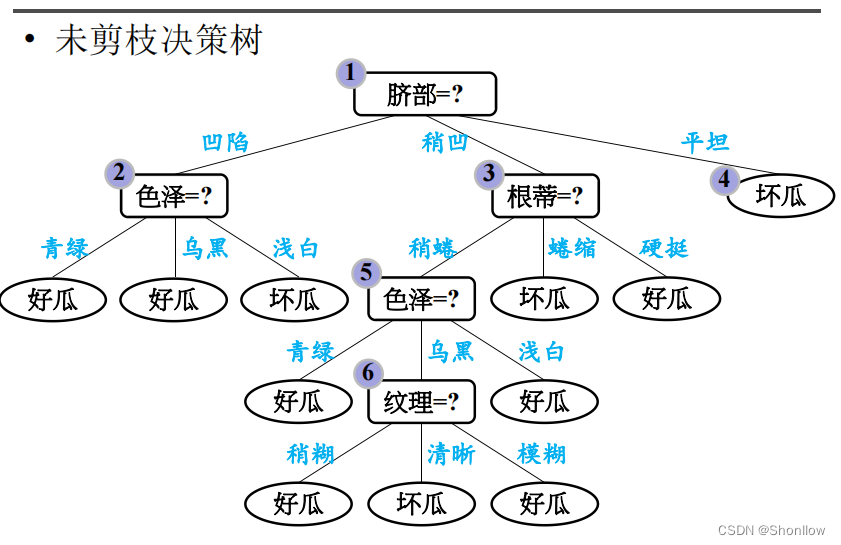
三、预剪枝
预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,如果当前结点的划分不能带来决策树模型泛化性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
如下图所示,在构造的时候就考虑到剪枝操作。
1) 首先,是否要按照“脐部”划分。在划分前,只有一个根节点,也是叶子节点,标记为“好瓜”。精度提高,所以按照“脐部”进行划分。
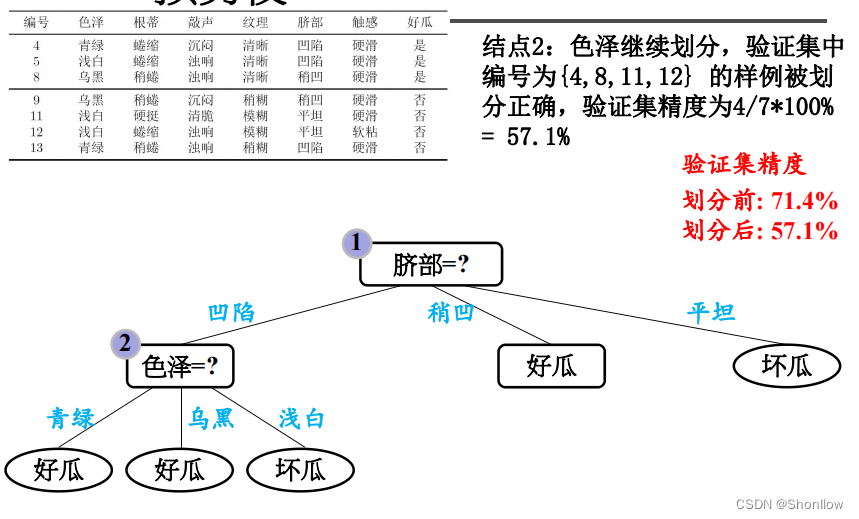
2) 当按照脐部进行划分后,会对结点 (2) 进行划分,再次使用信息增益挑选出值最大的那个特征,信息增益值最大的那个特征是“色泽”,则使用“色泽”划分后决策树为。但是,使用“色泽”划分后,编号为{5}的样本会从“好瓜”被分类为“坏瓜”,只有{4,8,11,12}被正确分类,精确度为47×100%=57.1%。所以,预剪枝操作会不再被这个节点进行划分。
3) 对于节点(3),最优属性为“根蒂”。但是,这么划分后精确度仍然是 71.4% ,所以也不会对这个节点进行操作。
预剪枝得到的决策树如下图所示。
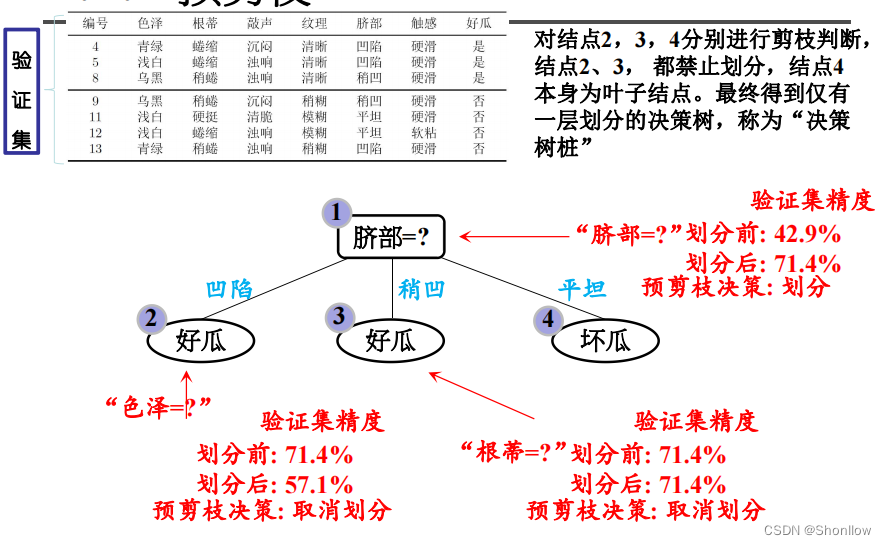
优点:
降低过拟合风险
显著减少训练时间和测试时间开销
缺点:
欠拟合风险:有些分支的当前划分虽然不能提升泛化性能,但在其基础上进行的后续划分却有可能显著提高性能。预剪枝基于“贪心”本质禁止这些分支展开,带来了欠拟合风险。
四、后剪枝
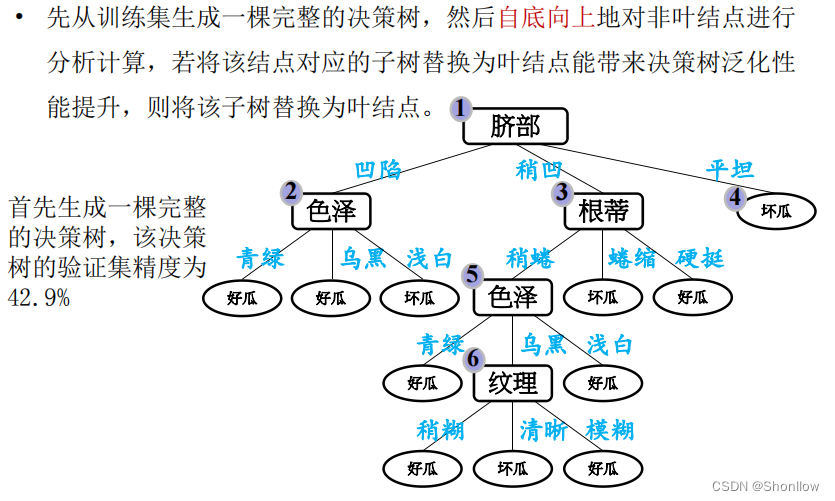
后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛化性能的提升,则把该子树替换为叶结点。
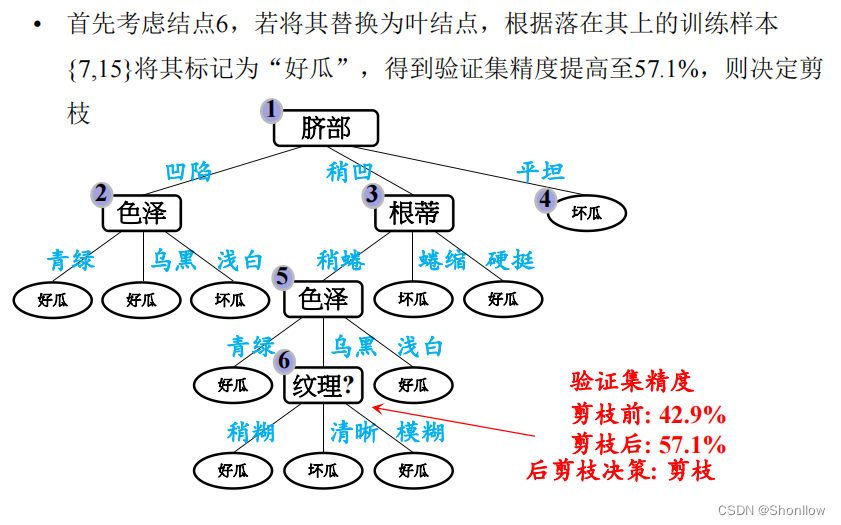
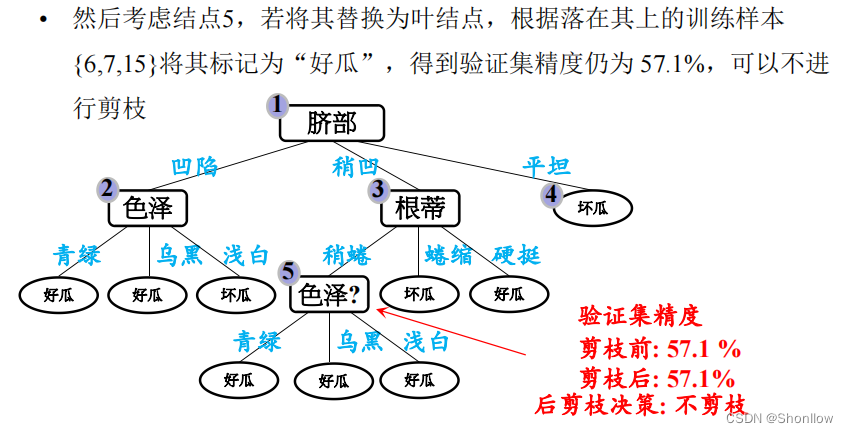
基于后剪枝策略得到的最终决策树如图所示

优点:
后剪枝比预剪枝保留了更多的分支, 欠拟合风险小 , 泛化性能往往优于预剪枝决策树
缺点:
训练时间开销大 :后剪枝过程是在生成完全决策树之后进行的,需要自底向上对所有非叶结点逐一计算
五、代码实现
1.创建数据集
import math
import numpy as np
# 创建西瓜书数据集2.0
def createDataXG20():
data = np.array([['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑']
, ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑']
, ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘']
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









