







 本文介绍了如何使用Python实现CART决策树算法,并探讨了剪枝操作,包括预剪枝和后剪枝。通过具体实例展示了不同剪枝策略对决策树模型泛化能力的影响,强调了后剪枝在提升模型性能方面的优势。
本文介绍了如何使用Python实现CART决策树算法,并探讨了剪枝操作,包括预剪枝和后剪枝。通过具体实例展示了不同剪枝策略对决策树模型泛化能力的影响,强调了后剪枝在提升模型性能方面的优势。
这里主要基于Python实现,许多地方采用了sklearn库,环境搭建可参考 数据挖掘入门:Python开发环境搭建(eclipse-pydev模式).
相关答案和源代码托管在我的Github上:PY131/Machine-Learning_ZhouZhihua.
4.4 编程实现CART算法与剪枝操作

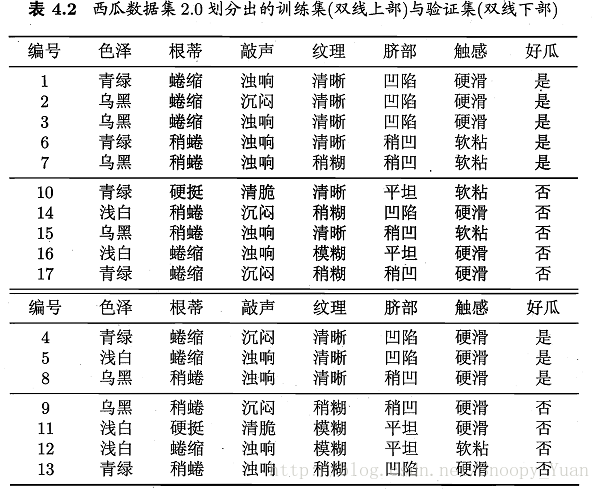
决策树基于训练集完全构建易陷入过拟合。为提升泛化能力。通常需要对决策树进行剪枝。
原始的CART算法采用基尼指数作为最优属性划分选择标准。
编码基于Python实现,详细解答和编码过程如下:(查看完整代码和数据集):
1.最优划分属性选择 - 基尼指数
同信息熵类似,基尼指数(Gini index)也常用以度量数据纯度,一般基尼值越小,数据纯度越高,相关内容可参考书p79,最典型的相关决策树生成算法是CART算法。
下面是某属性下数据的基尼指数计算代码样例(连续和离散的不同操作):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2820
2820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









