







torch生成Triton 内核代码
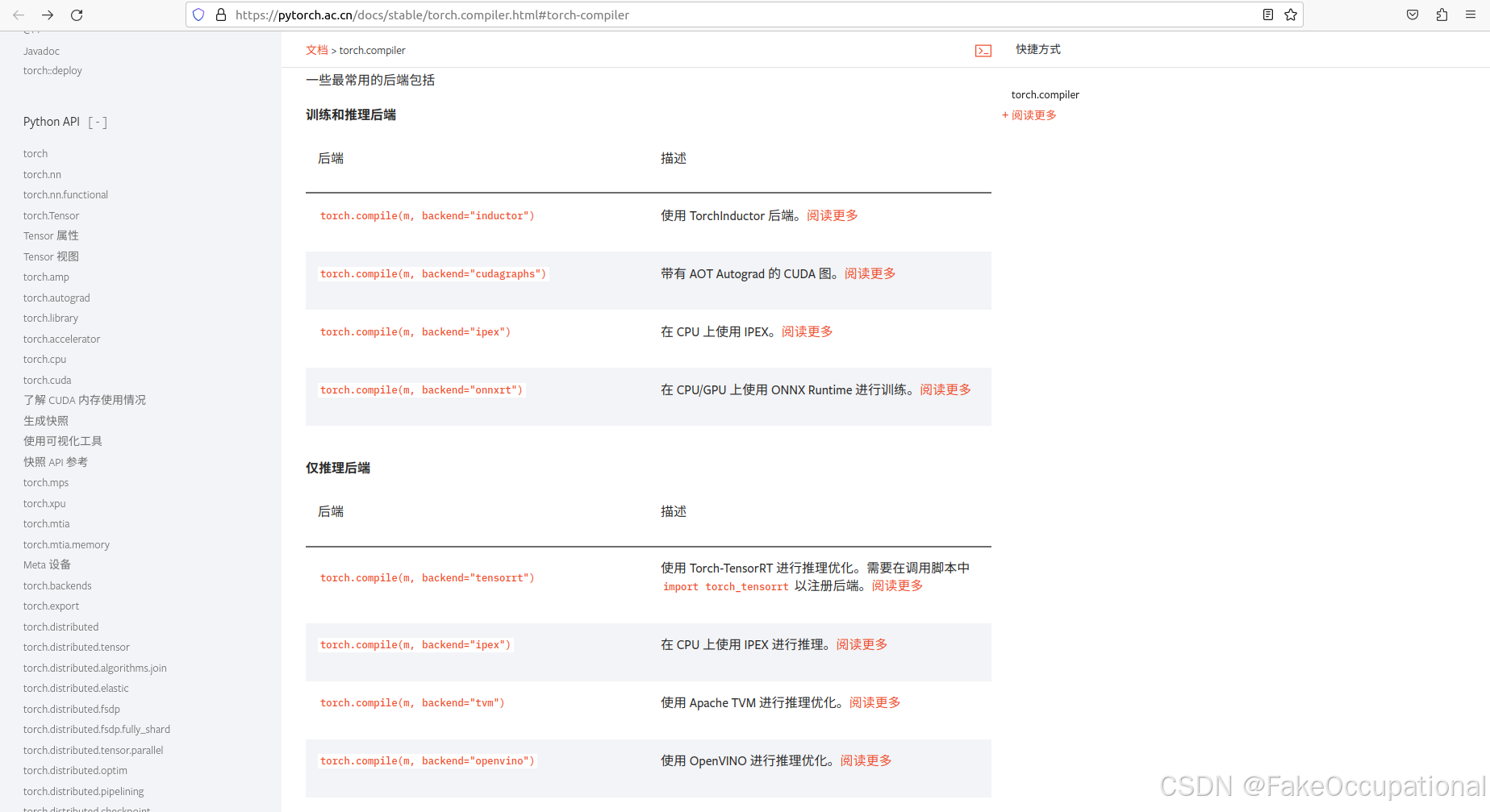
torch.compile()是 PyTorch 2.0 中引入的一个新功能,用于将 PyTorch 代码编译为更高效的机器代码,以加速模型的训练和推理过程。backend="inductor"是torch.compile()的一个选项,指示使用 Inductor 后端来进行代码优化和编译。Inductor 是 PyTorch 内部的一个编译器,旨在对 PyTorch 代码进行低级别的硬件优化,尤其是在 NVIDIA GPU 上。
使用 torch.compile()和 Inductor 后端优化简单加法
https://pytorch.ac.cn/docs/stable/torch.compiler.html#torch-compiler
 - 下面是如何使用
- 下面是如何使用 torch.compile()与backend="inductor"来加速一个简单函数(例如加法运算)的一些示例。
import torch
# 定义一个简单的加法函数
def add(x, y):
return x + y
# 使用 torch.compile 来优化加法操作
compiled_add = torch.compile(add, backend="inductor")
# 创建两个张量
x = torch.randn(1000, 1000, device='cuda')
y = torch.randn(1000, 1000, device='cuda')
# 使用优化后的函数进行计算
result = compiled_add(x, y)
print(result)
TORCH_COMPILE_DEBUG
-
TORCH_COMPILE_DEBUG是一个环境变量,在使用torch.compile()进行编译时,可以启用调试模式,以便分析torch.compile()的行为、查看中间代码、诊断错误或性能问题。 -
-
启用
TORCH_COMPILE_DEBUG=1来开启调试模式。可使用TORCH_COMPILE_DEBUG=1 python add.py或在代码中添加os.environ["TORCH_COMPILE_DEBUG"] = "1":
import os
os.environ["TORCH_COMPILE_DEBUG"] = "1"
import torch
# 一个简单的编译函数
def add(x, y):
return x + y
compiled_add = torch.compile(add, backend="inductor")
x = torch.randn(1000, 1000, device='cuda')
y = torch.randn(1000, 1000, device='cuda')
result = compiled_add(x, y)
print(result)
生成的代码
# AOT ID: ['0_inference']
from ctypes import c_void_p, c_long
import torch
import math
import random
import os
import tempfile
from math import inf, nan
from torch._inductor.hooks import run_intermediate_hooks
from torch._inductor.utils import maybe_profile
from torch._inductor.codegen.memory_planning import _align as align
from torch import device, empty_strided
from torch._inductor.async_compile import AsyncCompile
from torch._inductor.select_algorithm import extern_kernels
from torch._inductor.codegen.multi_kernel import MultiKernelCall
aten = torch.ops.aten
inductor_ops = torch.ops.inductor
_quantized = torch.ops._quantized
assert_size_stride = torch._C._dynamo.guards.assert_size_stride
empty_strided_cpu = torch._C._dynamo.guards._empty_strided_cpu
empty_strided_cuda = torch._C._dynamo.guards._empty_strided_cuda
reinterpret_tensor = torch._C._dynamo.guards._reinterpret_tensor
alloc_from_pool = torch.ops.inductor._alloc_from_pool
async_compile = AsyncCompile()
# kernel path: /tmp/torchinductor_cifi/ji/cjihuz3ubhgbl4o4aqxe4i5j3uvylsainlqsrb5i6i2xjzb5n72h.py
# Source Nodes: [add], Original ATen: [aten.add]
# add => add
triton_poi_fused_add_0 = async_compile.triton('triton_', '''
import triton
import triton.language as tl
from triton.compiler.compiler import AttrsDescriptor
from torch._inductor.runtime import triton_helpers, triton_heuristics
from torch._inductor.runtime.triton_helpers import libdevice, math as tl_math
from torch._inductor.runtime.hints import AutotuneHint, ReductionHint, TileHint, instance_descriptor, DeviceProperties
@triton_heuristics.pointwise(
size_hints=[1048576],
filename=__file__,
triton_meta={'signature': {0: '*fp32', 1: '*fp32', 2: '*fp32', 3: 'i32'}, 'device': DeviceProperties(type='cuda', index=0, cc=86, major=8, regs_per_multiprocessor=65536, max_threads_per_multi_processor=1536, multi_processor_count=16), 'constants': {}, 'configs': [AttrsDescriptor(divisible_by_16=(0, 1, 2, 3), equal_to_1=())]},
inductor_meta={'autotune_hints': set(), 'kernel_name': 'triton_poi_fused_add_0', 'mutated_arg_names': [], 'no_x_dim': False, 'num_load': 2, 'num_reduction': 0, 'backend_hash': 'BA4D03034BF4ECE36F7AD5ADE912877A9B0F0ECFFE747E304421059DC5771599', 'are_deterministic_algorithms_enabled': False, 'assert_indirect_indexing': True, 'autotune_local_cache': True, 'autotune_pointwise': True, 'autotune_remote_cache': False, 'force_disable_caches': False, 'dynamic_scale_rblock': True, 'max_autotune': False, 'max_autotune_pointwise': False, 'min_split_scan_rblock': 256, 'spill_threshold': 16, 'store_cubin': False},
min_elem_per_thread=0
)
@triton.jit
def triton_(in_ptr0, in_ptr1, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 1000000
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (x0), xmask)
tmp1 = tl.load(in_ptr1 + (x0), xmask)
tmp2 = tmp0 + tmp1
tl.store(out_ptr0 + (x0), tmp2, xmask)
''', device_str='cuda')
import triton
import triton.language as tl
from torch._inductor.runtime.triton_heuristics import grid, split_scan_grid, start_graph, end_graph
from torch._C import _cuda_getCurrentRawStream as get_raw_stream
async_compile.wait(globals())
del async_compile
def call(args):
arg0_1, arg1_1 = args
args.clear()
assert_size_stride(arg0_1, (1000, 1000), (1000, 1))
assert_size_stride(arg1_1, (1000, 1000), (1000, 1))
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0)
buf0 = empty_strided_cuda((1000, 1000), (1000, 1), torch.float32)
# Source Nodes: [add], Original ATen: [aten.add]
stream0 = get_raw_stream(0)
triton_poi_fused_add_0.run(arg0_1, arg1_1, buf0, 1000000, grid=grid(1000000), stream=stream0)
del arg0_1
del arg1_1
return (buf0, )
def benchmark_compiled_module(times=10, repeat=10):
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
arg0_1 = rand_strided((1000, 1000), (1000, 1), device='cuda:0', dtype=torch.float32)
arg1_1 = rand_strided((1000, 1000), (1000, 1), device='cuda:0', dtype=torch.float32)
fn = lambda: call([arg0_1, arg1_1])
return print_performance(fn, times=times, repeat=repeat)
if __name__ == "__main__":
from torch._inductor.wrapper_benchmark import compiled_module_main
compiled_module_main('None', benchmark_compiled_module)
torch中使用Triton 内核(用户编写的)
import torch
import triton
from triton import language as tl
# Triton 核心定义
@triton.jit
def add_kernel(
in_ptr0,
in_ptr1,
out_ptr,
n_elements,
BLOCK_SIZE: "tl.constexpr",
):
pid = tl.program_id(axis=0) # 获取程序ID
block_start = pid * BLOCK_SIZE # 计算当前线程块的起始位置
offsets = block_start + tl.arange(0, BLOCK_SIZE) # 当前线程块内的偏移量
mask = offsets < n_elements # 避免越界
x = tl.load(in_ptr0 + offsets, mask=mask) # 加载输入张量x
y = tl.load(in_ptr1 + offsets, mask=mask) # 加载输入张量y
output = x + y # 执行加法操作
tl.store(out_ptr + offsets, output, mask=mask) # 存储结果
# 使用 Torch 编译器来加速函数
@torch.compile(fullgraph=True)
def add_fn(x, y):
output = torch.zeros_like(x) # 创建输出张量
n_elements = output.numel() # 获取元素数量
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]),) # 计算网格大小
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=4) # 调用 Triton 核心
return output
# 测试代码
x = torch.randn(4, device="cuda") # 创建输入张量 x
y = torch.randn(4, device="cuda") # 创建输入张量 y
out = add_fn(x, y) # 调用加法函数
print(f"Vector addition of\nX:\t{x}\nY:\t{y}\nis equal to\n{out}")

















 3065
3065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









