







 R-CNN通过结合selective search、CNN和SVM实现目标检测,提升了性能。其框架包括region proposal、CNN特征提取、SVM分类和边框回归。尽管训练繁琐、速度慢且耗资源,但在图像分类和目标检测任务中表现出色。
R-CNN通过结合selective search、CNN和SVM实现目标检测,提升了性能。其框架包括region proposal、CNN特征提取、SVM分类和边框回归。尽管训练繁琐、速度慢且耗资源,但在图像分类和目标检测任务中表现出色。
一、为什么提出R-CNN
目标检测性能停滞不前,性能最好的集成方法又太复杂,所以作者提出了一个既能大幅提升性能,又更简单的R-CNN。
二、R-CNN的框架
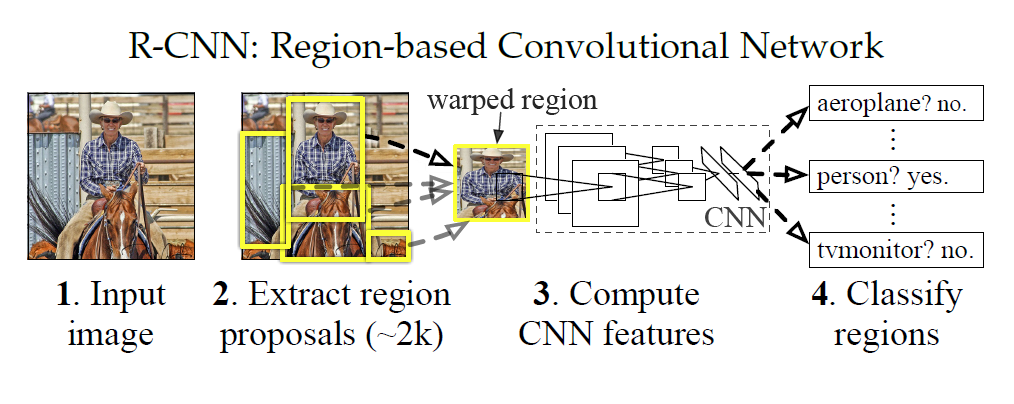
上面的框架图清晰的给出了R-CNN的目标检测流程:
1) 输入测试图像
2) 利用selective search算法在图像中提取2000个左右的region proposal。
3) 将每个region proposal变换(warp)成227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征。
4) 将每个region proposal提取到的CNN特征输入到SVM进行分类。
针对上面的框架给出几点解释:
上面的框架图是测试的流程图,要进行测试我们首先要训练好提取特征的CNN模型,以及用于分类的SVM:使用在ImageNet上预训练的模型(AlexNet/VGG16)进行微调得到用于特征提取的CNN模型,然后利用CNN模型对训练集提特征训练SVM。
对每个region proposal缩放到同一尺度是因为CNN全连接层输入需要保证维度固定。
上图少画了一个过程——对于SVM分好类的region proposal做边框回归(bounding-box regression),边框回归是对region proposal进行纠正的线性回归算法,为了让region proposal提取到的窗口跟目标真实窗口更吻合。因为region proposal提取到的窗口不可能跟人手工标记那么准,如果reg
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









