







depth: int.
Number of Transformer blocks.
而transformer block在文中具体是指:
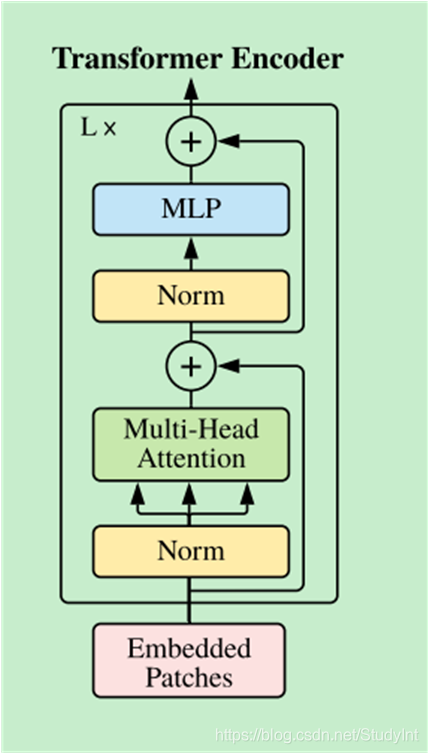
也即是,如果depth = 8,就是设置了8层transformer encoder
depth: int.而transformer block在文中具体是指:
也即是,如果depth = 8,就是设置了8层transformer encoder
 731
1416
731
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























