







一、广义线性模型
1.1 指数分布族
一维的指数分布族: f λ ( y ) = exp { λ y − Ψ ( λ ) } ⋅ f 0 ( y ) (1) f_{\lambda}(y)=\exp\{\lambda y-\Psi(\lambda)\}\cdot f_0(y)\tag1 fλ(y)=exp{λy−Ψ(λ)}⋅f0(y)(1)
1.2 常见的指数分布:
- N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2),化成指数分布的话, λ = μ σ 2 , Ψ ( λ ) = μ 2 σ 2 \lambda=\frac{\mu}{\sigma^2}, \Psi(\lambda)=\frac{\mu}{2\sigma^2} λ=σ2μ,Ψ(λ)=2σ2μ
- P o i ( μ ) Poi(\mu) Poi(μ),化成指数分布的话, λ = ln μ , Ψ ( λ ) = μ \lambda=\ln \mu, \Psi(\lambda)=\mu λ=lnμ,Ψ(λ)=μ
- B i ( n , π ) Bi(n, \pi) Bi(n,π),化成指数分布的话, λ = ln π 1 − π , Ψ ( λ ) = n ln ( 1 + e λ ) \lambda=\ln\frac{\pi}{1-\pi}, \Psi(\lambda)=n\ln(1+e^\lambda) λ=ln1−ππ,Ψ(λ)=nln(1+eλ)
1.3 广义线性模型
广义线性模型就是解决响应变量是服从二项分布、泊松分布或理论上是任何指数分布族的线性拟合问题。
现有
N
N
N个观测点
y
=
{
y
1
,
⋯
,
y
N
}
\bm y=\{y_1,\cdots,y_N\}
y={y1,⋯,yN}来自某一指数分布族,即
y
i
∼
f
λ
i
(
⋅
)
,
i
=
1
,
⋯
,
N
(2)
y_i\sim f_{\lambda_i}(\cdot), i=1,\cdots,N\tag2
yi∼fλi(⋅),i=1,⋯,N(2)
此时需要估计
N
N
N个参数
λ
1
,
⋯
,
λ
N
\lambda_1,\cdots,\lambda_N
λ1,⋯,λN(观测点独立,但不同分布,具体的
λ
i
\lambda_i
λi不同)
通过线性回归,将 N N N个参数的问题,转化为对 p p p个参数的估计,这就是广义线性模型的核心策略。如下:
设
λ
=
X
α
(3)
\bm\lambda=\bm X\bm\alpha\tag3
λ=Xα(3)
其中,
X
\bm X
X为
N
×
p
N\times p
N×p的结构矩阵,
α
\bm\alpha
α为
p
p
p维未知参数。
即
[
λ
1
λ
2
⋮
λ
N
]
=
[
x
1
x
2
⋮
x
N
]
N
×
p
[
α
1
α
2
⋮
α
p
]
p
×
1
(4)
\begin{bmatrix} \lambda_1 \\ \lambda_2 \\ \vdots\\ \lambda_N \end{bmatrix}=\begin{bmatrix} \bm x_1 \\ \bm x_2 \\ \vdots\\ \bm x_N \end{bmatrix}_{N\times p}\begin{bmatrix} \alpha_1 \\ \alpha_2 \\ \vdots\\ \alpha_p \end{bmatrix}_{p\times 1}\tag4
⎣⎢⎢⎢⎡λ1λ2⋮λN⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡x1x2⋮xN⎦⎥⎥⎥⎤N×p⎣⎢⎢⎢⎡α1α2⋮αp⎦⎥⎥⎥⎤p×1(4)
亦即
λ
1
=
x
1
⊤
α
\lambda_1=\bm x_1^\top\bm\alpha
λ1=x1⊤α,
λ
2
=
x
2
⊤
α
\lambda_2=\bm x_2^\top\bm\alpha
λ2=x2⊤α,
⋯
\cdots
⋯,
λ
N
=
x
N
⊤
α
\lambda_N=\bm x_N^\top\bm\alpha
λN=xN⊤α。例如,
λ
1
=
x
11
α
1
+
x
12
α
2
+
⋯
+
x
1
p
α
p
\lambda_1=x_{11}\alpha_1+x_{12}\alpha_2+\cdots+x_{1p}\alpha_p
λ1=x11α1+x12α2+⋯+x1pαp
y
\bm y
y的联合密度函数为
f
(
y
)
=
∏
i
=
1
N
f
λ
i
(
y
i
)
=
exp
{
∑
i
=
1
N
(
λ
i
y
i
−
Ψ
(
λ
i
)
)
}
∏
i
=
1
N
f
0
(
y
i
)
(5)
f(\bm y)=\prod_{i=1}^Nf_{\lambda_i}(y_i)=\exp\left\{\sum_{i=1}^N(\lambda_iy_i-\Psi(\lambda_i))\right\}\prod_{i=1}^Nf_0(y_i)\tag5
f(y)=i=1∏Nfλi(yi)=exp{i=1∑N(λiyi−Ψ(λi))}i=1∏Nf0(yi)(5)
化成向量形式为
f
(
y
)
=
exp
{
λ
⊤
y
−
Ψ
(
λ
)
}
f
0
(
y
)
(6)
f(\bm y)=\exp\left\{\bm\lambda^\top\bm y-\Psi(\bm\lambda)\right\}f_0(\bm y)\tag6
f(y)=exp{λ⊤y−Ψ(λ)}f0(y)(6)
此时有
N
N
N个参数
λ
1
,
⋯
,
λ
N
\lambda_1,\cdots,\lambda_N
λ1,⋯,λN,再将
λ
=
X
α
\bm\lambda=\bm X\bm\alpha
λ=Xα带入可得
f
α
(
y
)
=
exp
{
α
⊤
X
⊤
y
−
Ψ
(
X
α
)
}
f
0
(
y
)
(7)
f_\bm\alpha(\bm y)=\exp\left\{\bm\alpha^\top\bm X^\top\bm y-\Psi(\bm X\bm\alpha)\right\}f_0(\bm y)\tag7
fα(y)=exp{α⊤X⊤y−Ψ(Xα)}f0(y)(7)
此时有
p
p
p个参数
α
1
,
⋯
,
α
p
\alpha_1,\cdots,\alpha_p
α1,⋯,αp
为进一步求解,令
z
=
X
⊤
y
\bm z=\bm X^\top\bm y
z=X⊤y,带入可得
f
α
(
y
)
=
exp
{
α
⊤
z
−
γ
(
α
)
}
⋅
f
0
(
y
)
(8)
f_\bm\alpha(\bm y)=\exp\left\{\bm\alpha^\top\bm z-\gamma(\bm\alpha)\right\}\cdot f_0(\bm y)\tag8
fα(y)=exp{α⊤z−γ(α)}⋅f0(y)(8)
其中,
γ
(
α
)
=
Ψ
(
X
α
)
\gamma(\bm\alpha)=\Psi(\bm X\bm\alpha)
γ(α)=Ψ(Xα)
( 8 ) (8) (8)式是 p p p维参数的指数分布族, z \bm z z为充分统计量,故对一个 p p p维的广义线性模型,其估计都依赖与 z \bm z z,这样,不管 N N N多大,只分析 p p p维即可,避免了高维估计。
1.4 估计参数
用极大似然来估计参数 α \bm\alpha α。
由
(
8
)
(8)
(8)式可得:
l
y
(
α
)
=
α
⊤
z
−
γ
(
α
)
+
ln
f
0
(
y
)
(9)
l_{\bm y}(\bm\alpha)=\bm\alpha^\top\bm z-\gamma(\bm\alpha)+\ln f_0(\bm y)\tag9
ly(α)=α⊤z−γ(α)+lnf0(y)(9)
求导得
∂
∂
α
l
y
(
α
)
=
z
−
∂
∂
α
γ
(
α
)
(10)
\frac{\partial}{\partial\bm\alpha}l_{\bm y}(\bm\alpha)=\bm z-\frac{\partial}{\partial\bm\alpha}\gamma(\bm\alpha)\tag{10}
∂α∂ly(α)=z−∂α∂γ(α)(10)
由于
z
=
X
⊤
y
\bm z=\bm X^\top\bm y
z=X⊤y,
∂
∂
α
γ
(
α
)
=
E
α
(
z
)
\frac{\partial}{\partial\bm\alpha}\gamma(\bm\alpha)=E_\bm\alpha(\bm z)
∂α∂γ(α)=Eα(z),所以有
X
⊤
y
−
E
(
X
⊤
y
)
=
X
⊤
(
y
−
E
(
y
)
)
=
X
⊤
(
y
−
μ
(
α
^
)
)
=
0
(11)
\bm X^\top\bm y-E(\bm X^\top\bm y)=\bm X^\top\left(\bm y-E(\bm y)\right)=\bm X^\top\left(\bm y-\mu(\hat\bm\alpha)\right)=0\tag{11}
X⊤y−E(X⊤y)=X⊤(y−E(y))=X⊤(y−μ(α^))=0(11)
即未知参数
α
\bm\alpha
α的极大似然估计满足
X
⊤
(
y
−
μ
(
α
^
)
)
=
0
(12)
\bm X^\top\left(\bm y-\mu(\hat\bm\alpha)\right)=0\tag{12}
X⊤(y−μ(α^))=0(12)
二、逻辑回归模型
2.1 基本思想
假设我们有 n n n组分类数据, { y 1 , ⋯ , y n } \left\{y_1,\cdots,y_n\right\} {y1,⋯,yn}, y i ∈ { 0 , 1 } y_i\in\{0, 1\} yi∈{0,1},因变量服从伯努利分布,即 y i ∼ B i ( p i ) y_i\sim Bi(p_i) yi∼Bi(pi), p i = P { y i = 1 ∣ x i } p_i=P\{y_i=1|\bm x_i\} pi=P{yi=1∣xi},逻辑回归本质上是估计 p i p_i pi。
由于伯努利分布是指数分布族,所以可以用广义线性模型来估计 p i p_i pi,所以逻辑回归是广义线性模型的一种。
2.2 模型的形式
由
1.3
1.3
1.3节可知,对于
y
i
∼
f
λ
i
(
⋅
)
,
i
=
1
,
⋯
,
N
(13)
y_i\sim f_{\lambda_i}(\cdot), i=1,\cdots,N\tag{13}
yi∼fλi(⋅),i=1,⋯,N(13)
需要先对参数
λ
\bm\lambda
λ进行变换
λ
=
X
α
(14)
\bm\lambda=\bm X\bm\alpha\tag{14}
λ=Xα(14)
即
λ
i
=
x
i
⊤
α
=
x
i
,
1
α
1
+
⋯
+
x
i
,
p
α
p
\lambda_i=\bm x_i^\top\bm\alpha=x_{i,1}\alpha_1+\cdots+x_{i,p}\alpha_p
λi=xi⊤α=xi,1α1+⋯+xi,pαp
对于伯努利分布 B i ( p ) Bi(p) Bi(p), λ = ln p 1 − p \lambda=\ln \frac{p}{1-p} λ=ln1−pp,所以有 ln p i 1 − p i = x i ⊤ α = x i , 1 α 1 + ⋯ + x i , p α p (15) \ln \frac{p_i}{1-p_i}=\bm x_i^\top\bm\alpha=x_{i,1}\alpha_1+\cdots+x_{i,p}\alpha_p\tag{15} ln1−pipi=xi⊤α=xi,1α1+⋯+xi,pαp(15)
对上式化简可得 p i = exp ( x i ⊤ α ) 1 + exp ( x i ⊤ α ) = 1 1 + exp ( − x i ⊤ α ) (16) p_i=\frac{\exp(\bm x_i^\top\bm\alpha)}{1+\exp(\bm x_i^\top\bm\alpha)}=\frac{1}{1+\exp(-\bm x_i^\top\bm\alpha)}\tag{16} pi=1+exp(xi⊤α)exp(xi⊤α)=1+exp(−xi⊤α)1(16)
如果令 z i = x i ⊤ α z_i=x_i^\top\bm\alpha zi=xi⊤α的话,上式可化为 p i = 1 1 + exp ( − z i ) (17) p_i=\frac{1}{1+\exp(-z_i)}\tag{17} pi=1+exp(−zi)1(17)
这就是典型的 S i g m o i d Sigmoid Sigmoid函数 g ( z ) = 1 1 + exp ( − z ) (18) g(z)=\frac{1}{1+\exp(-z)}\tag{18} g(z)=1+exp(−z)1(18)
这样,就将估计 n n n个参数 p 1 , ⋯ , p n p_1,\cdots,p_n p1,⋯,pn转化为估计 p p p个参数 α 1 , ⋯ , α p \alpha_1,\cdots,\alpha_p α1,⋯,αp了,具体 p p p的大小,根据我们选择有多少特征。
由 ( 15 ) (15) (15)可知, x i , 1 α 1 + ⋯ + x i , p α p x_{i,1}\alpha_1+\cdots+x_{i,p}\alpha_p xi,1α1+⋯+xi,pαp并不是 y i = 1 y_i=1 yi=1的概率,而是对数几率(事件的几率 p 1 − p \frac{p}{1-p} 1−pp)
2.3 参数的估计
还是用极大似然法估计 α 1 , ⋯ , α p \alpha_1,\cdots,\alpha_p α1,⋯,αp
1.4 1.4 1.4的推导的针对一般的广义线性模型,对于逻辑回归,我们可有:
似然函数为
L
=
∏
i
=
1
n
p
i
y
i
(
1
−
p
i
)
1
−
y
i
(19)
L=\prod_{i=1}^np_i^{y_i}(1-p_i)^{1-y_i}\tag{19}
L=i=1∏npiyi(1−pi)1−yi(19)
对数似然函数为
l
=
∑
i
=
1
n
[
y
i
ln
p
i
+
(
1
−
y
i
)
ln
(
1
−
p
i
)
]
(20)
l=\sum_{i=1}^n\left[y_i\ln p_i+(1-y_i)\ln(1-p_i)\right]\tag{20}
l=i=1∑n[yilnpi+(1−yi)ln(1−pi)](20)
进行化简:
l
=
∑
i
=
1
n
[
y
i
ln
p
i
1
−
p
i
+
ln
(
1
−
p
i
)
]
=
∑
i
=
1
n
[
y
i
(
x
i
⊤
α
)
−
ln
(
1
+
exp
(
x
i
⊤
α
)
)
]
l=\sum\limits_{i=1}^n\left[y_i\ln\frac{p_i}{1-p_i}+\ln(1-p_i)\right]=\sum\limits_{i=1}^n\left[y_i(\bm x_i^\top\bm\alpha)-\ln(1+\exp(\bm x_i^\top\bm\alpha))\right]
l=i=1∑n[yiln1−pipi+ln(1−pi)]=i=1∑n[yi(xi⊤α)−ln(1+exp(xi⊤α))]
故对
l
=
∑
i
=
1
n
[
y
i
(
x
i
⊤
α
)
−
ln
(
1
+
exp
(
x
i
⊤
α
)
)
]
(21)
l=\sum\limits_{i=1}^n\left[y_i(\bm x_i^\top\bm\alpha)-\ln(1+\exp(\bm x_i^\top\bm\alpha))\right]\tag{21}
l=i=1∑n[yi(xi⊤α)−ln(1+exp(xi⊤α))](21)
求极大值,即可得到参数
α
\bm\alpha
α的估计
2.4 参数的求解
可用梯度下降法、牛顿法、拟牛顿法等进行求解
2.4.1 梯度下降法
梯度下降法是求解无约束最优化问题的一种最常用的方法,优点是实现简单。梯度下降法是一种迭代算法。先选取适当的初值 x ( 0 ) x^{(0)} x(0),不断迭代,更新 x x x的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使函数值下降最快的方向,在迭代的每一步,以负梯度方向更新 x x x的值,从而达到减小函数值的目的。
为什么负梯度方向是使函数值下降最快的方向?
设函数 f ( x ) f(x) f(x)在 x k x_k xk附近连续可微,且 g k = ∇ f ( x k ) ≠ 0 g_k=\nabla f(x_k)\ne0 gk=∇f(xk)=0, 由Taylor展开式 f ( x ) = f ( x k ) + ( x − x k ) T ∇ f ( x k ) + o ( ∣ ∣ x − x k ∣ ∣ ) f(x)=f(x_k)+(x-x_k)^T\nabla f(x_k)+o(||x-x_k||) f(x)=f(xk)+(x−xk)T∇f(xk)+o(∣∣x−xk∣∣)
可知, 若记 x − x k = α d k x-x_k=\alpha d_k x−xk=αdk, 则满足 d k T g k < 0 d_k^Tg_k\lt0 dkTgk<0的方向 d k d_k dk是下降方向. 当 α \alpha α给定后, d k T g k d^T_kg_k dkTgk越小, 即 − d k T g k -d^T_kg_k −dkTgk越大, 函数下降越快. 由 C a u c h y − S c h w a r t z Cauchy-Schwartz Cauchy−Schwartz不等式 ∣ d k T g k ∣ ≤ ∣ d k ∣ ∣ g k ∣ |d_k^Tg_k|\le |d_k||g_k| ∣dkTgk∣≤∣dk∣∣gk∣
故当且仅当 d k = − g k d_k=-g_k dk=−gk时, d k T g k d^T_kg_k dkTgk最小, 从而称 − g k -g_k −gk时最速下降方向.
对
(
21
)
(21)
(21)变形得
l
=
∑
i
=
1
n
[
−
y
i
(
x
i
⊤
α
)
+
ln
(
1
+
exp
(
x
i
⊤
α
)
)
]
(22)
l=\sum\limits_{i=1}^n\left[-y_i(\bm x_i^\top\bm\alpha)+\ln(1+\exp(\bm x_i^\top\bm\alpha))\right]\tag{22}
l=i=1∑n[−yi(xi⊤α)+ln(1+exp(xi⊤α))](22)
所以我们得目标是
min
α
l
(23)
\min_{\bm\alpha} l\tag{23}
αminl(23)
对 ( 22 ) (22) (22)求导得 ∂ ∂ α l = ∑ i = 1 n ( 1 1 + exp ( − x i ⊤ α ) − y i ) x i (24) \frac{\partial}{\partial\bm\alpha}l=\sum_{i=1}^n(\frac{1}{1+\exp(-\bm x_i^\top\bm\alpha)}-y_i)\bm x_i\tag{24} ∂α∂l=i=1∑n(1+exp(−xi⊤α)1−yi)xi(24)
所以可以得到参数 α \bm\alpha α的更新方式为 α t + 1 = α t − η ∑ i = 1 n ( 1 1 + exp ( − x i ⊤ α t ) − y i ) x i (25) \bm\alpha^{t+1}=\bm\alpha^t-\eta\sum_{i=1}^n(\frac{1}{1+\exp(-\bm x_i^\top\bm\alpha^t)}-y_i)\bm x_i\tag{25} αt+1=αt−ηi=1∑n(1+exp(−xi⊤αt)1−yi)xi(25)
梯度下降法又分为梯度下降法、随机梯度下降法和批次随机梯度下降法。
- 梯度下降法:每次更新参数用所有的样本。
优点:得到的是全局最优解
缺点:计算量打,速度慢 - 随机梯度下降法:每次更新参数用随机抽取的一个样本
优点:速度快
缺点:有可能陷入局部极小解 - 批次随机梯度下降法:每次更新参数用随机抽取的一部分样本,优缺点介于上述两种之间
2.4.2 牛顿法和拟牛顿法
牛顿法和拟牛顿法也是求解无约束最优化问题的常用方法,有收敛速度快的优点。牛顿法是迭代算法,每一步需要求解目标函数的黑塞矩阵的逆,计算比较复杂。拟牛顿法通过正定矩阵近似黑塞矩阵的逆矩阵或黑塞矩阵,简化了这一计算过程。
- 牛顿法:
α ( t + 1 ) = α ( t ) − H t − 1 g t (26) \bm\alpha^{(t+1)}=\bm\alpha^{(t)}-H_t^{-1}g_t\tag{26} α(t+1)=α(t)−Ht−1gt(26)
其中, H ( α ) = [ ∂ 2 f ∂ α i ∂ α j ] n × n H(\bm\alpha)=\left[\frac{\partial^2 f}{\partial \alpha_i\partial \alpha_j}\right]_{n\times n} H(α)=[∂αi∂αj∂2f]n×n为黑塞矩阵, g t = ∇ f ( α ( t ) ) g_t=\nabla f(\bm\alpha^{(t)}) gt=∇f(α(t))为 f ( α ) f(\bm\alpha) f(α)在 α ( t ) \bm\alpha^{(t)} α(t)处的一阶导的值。 - 拟牛顿法:
用正定矩阵近似黑塞矩阵的逆矩阵或黑塞矩阵。
2.4.3 梯度下降法和牛顿法的对比
链接:最优化问题中,牛顿法为什么比梯度下降法求解需要的迭代次数更少?
牛顿法比梯度下降法收敛的要快,这是因为牛顿法是二阶收敛,梯度下降是一阶收敛。事实上,梯度下降法每次只从当前位置选一个上升速度最大的方向走一步,牛顿法在选择方向时,不仅会考虑上升速度是否够大,还会考虑你走了一步之后,上升速度是否会变得更大,所以所需要的迭代次数更少。
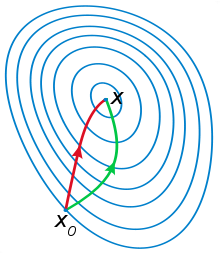
下面是wiki上的图片,红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
2.5 面试常见题
2.5.1 简单介绍一下算法
逻辑回归是在数据服从伯努利分布的假设下,通过极大似然的方法,运用梯度下降法来求解参数,从而达到将数据二分类的目的。
2.5.2 逻辑回归是如何做分类的
逻辑回归作为一个回归函数,如何用于分类问题。 逻辑回归中,对于每个 x \bm x x,其条件概率 y y y的确是一个连续的变量。而逻辑回归中可以设定一个阈值, y y y值大于这个阈值的是一类, y y y值小于这个阈值的是另外一类。至于阈值的选择,通常是根据实际情况来确定,一般情况下选取 0.5 作为阈值来划分。
2.5.3 逻辑回归损失函数
逻辑回归的损失函数是其极大似然函数。
2.5.4 逻辑回归中为什么使用对数损失而不用平方损失
对于逻辑回归,这里所说的对数损失和极大似然是相同的。 不使用平方损失的原因是,在使用 Sigmoid 函数作为正样本的概率时,同时将平方损失作为损失函数,这时所构造出来的损失函数是非凸的,不容易求解,容易得到其局部最优解。 而如果使用极大似然,其目标函数就是对数似然函数,该损失函数是关于未知参数的高阶连续可导的凸函数,便于求其全局最优解。
2.5.5 优缺点
-
优点:
-
形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
-
训练速度快。分类的时候,计算量仅仅只和特征的数目相关。并且逻辑回归的分布式优化 SGD 发展比较成熟。
-
方便调整输出结果,通过调整阈值的方式。
-
-
缺点:
- 准确率欠佳。因为形式非常的简单,而现实中的数据非常复杂,因此,很难达到很高的准确性。
- 很难处理数据不平衡的问题。
- 只能处理二分类问题。处理多分类的话,需要一对一或一对多。
2.5.6 和线性回归的联系与区别
- 区别:
- 一个是分类,一个是回归
- 线性回归假设因变量服从正态分布,逻辑回归假设因变量服从伯努利分布
- 线性回归优化的目标函数是平方损失,而逻辑回归优化的是对数损失
- 线性归回要求自变量与因变量呈线性关系,而逻辑回归没有要求
- 联系:
- 两个都是线性模型,线性回归是普通线性模型,逻辑回归是广义线性模型
- 目标函数都可以认为是极大似然函数
2.5.7 需要标准化吗?
不需要,但如果加入了正则化,就需要,和线性回归一样。
详见数据特征 标准化和归一化
2.5.8 LR一般需要连续特征离散化原因
- 离散特征的增加和减少都很容易,易于模型快速迭代
- 稀疏向量内积乘法速度快,计算结果方便存储,容易扩展
- 离散化的特征对异常数据有很强的鲁棒性(比如年龄为300异常值可归为年龄>30这一段)
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性(假设原本只有一个参数控制连续特征,离散化后,便有M个参数控制),能够提升模型表达能力,加大拟合;
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
2.5.9 怎么样连续特征离散化?
等宽法、等频法、根据经验
详情见连续数据离散化最通俗的理解与操作
2.5.10 逻辑回归在训练的过程当中,如果有很多的特征高度相关或者说有一个特征重复了很多遍,会造成怎样的影响
如果在损失函数最终收敛的情况下,其实就算有很多特征高度相关也不会影响分类器的效果。 但是对特征本身来说的话,假设只有一个特征,在不考虑采样的情况下,你现在将它重复 N 遍。训练以后完以后,数据还是这么多,但是这个特征本身重复了 N 遍,实质上将原来的特征分成了 N 份,每一个特征都是原来特征权重值的百分之一。
2.5.11 为什么还是会在训练的过程当中将高度相关的特征去掉
- 去掉高度相关的特征会让模型的可解释性更好
- 可以大大提高训练的速度















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









