







前言
语义分割,是一项基本任务,作为普通学生的我,只能利用大佬们提供的砖头和假设图纸进行搭建工作,这是我对自己的认知,不知读者你们如何认为?
开始阅读:
** 代码地址 **:https://github.com/nhatuan84/GFF-Gated-Fully-Fusion-for-Semantic-Segmentation
摘要
语义分割通过密集地预测每个像素的类别来产生对场景的全面理解。 深度卷积神经网络的高层次特征已经证明了它们在语义分割任务中的有效性。
现有的问题:对于详细信息很重要的小/薄对象,高层次特征的粗分辨率往往会导致较差的结果。
解决办法:自然要考虑使用低级别特征来补偿高级别特征中丢失的详细信息。 然而简单地组合多层次特征会受到它们之间语义差距的影响(即简单的拼接不够 for example Unet)。
**因此,本文的做法 :**提出了一种新的架构GFF,称为gated Fully Fusion 门控完全融合架构,以完全连接的方式使用门选择性地融合来自多个级别的特征。
具体来说,每个级别的特征都通过具有更强语义的高级特征和具有更多细节的低级特征来增强,并且使用gate来控制有用信息的传播,从而显著减少融合过程中的噪声。
这种架构组成的网络在Cityscape、Pascal Context, COCO-stuff 和 ADE20K四个数据集上实现了最优的结果。
(本文的中心就是这个门控装置,可以对每一个层次的特征都进行增强,最后达到更好的结果)
引言(绪论)
略
相关工作
略
方法
此模块,我们首先复盘了一下多水平特征融合以及三个基线网络的融合策略,然后介绍GFF和DFG模块的结合。
先看图: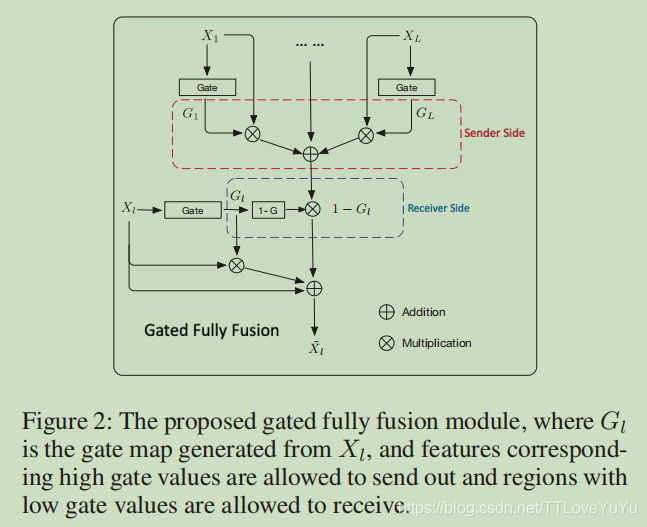
多水平的特征融合
考虑一个特征图 X 大小为
H
×
W
×
C
H × W × C
H×W×C,它来自某个主干网络的析取结果。特征图的语义内容以及细节内容由它们所处的网络深度决定。其中
H
H
H 为长,
w
w
w 为宽, C为通道数。因为经过的是下采样操作,故
H
i
+
1
≤
H
i
,
W
i
+
1
≤
W
i
H_{i+1} ≤ H_i, W_{i+1} ≤ W_i
Hi+1≤Hi,Wi+1≤Wi, 在语义分割中,顶层的特征概念图是输入图像的 1 / 8, 主要的限制在于X L只包含了大量的语义信息,即特征,但是空间信息太少,但是分割的结果又要和原始图像一般大,而浅层的就恰恰相反,所以就要结合这两个部分的信息来为分割服务。
这就可以抽象为这个公式:
X
1
,
X
2
,
…
…
→
X
1
′
,
X
2
′
,
…
…
{X_1,X_2, ……} \to {X_1 ', X_2',……}
X1,X2,……→X1′,X2′,……,
→
\to
→操作指的是经过一个操作
f
f
f,
X
i
′
X_i '
Xi′指的是融合后的特征,当然是来自第
i
i
i 层 与 各个层的特征结合的结果!
为了简化下列方程中的符号,忽略了双线性采样和
1
×
1
1×1
1×1卷积,这些卷积被用来重塑右手侧的特征映射,使融合的特征映射具有与左手侧相同的大小。 连接是一个简单的操作,可以聚合多个特征映射中的所有信息。
但它将有用的信息与大量的非信息特征混合在一起。 加法是通过在每个位置添加特征来组合特征映射的另一种简单方法,而它面临着与级联相似的问题。 FPN(Lin等人) 通过具有横向连接的自上而下的途径进行融合过程。
第一步 :
C
o
n
c
a
t
:
X
k
’
=
c
o
n
c
a
t
(
X
1
,
X
2
,
…
…
,
X
L
)
Concat : X_k ’ = concat(X_1, X_2, ……,X_L)
Concat:Xk’=concat(X1,X2,……,XL)
第二步:
A
d
d
i
t
i
o
n
:
X
k
′
=
∑
X
i
,
(
i
∈
[
1
,
L
]
)
Addition: X_k ' = ∑ X_i ,( i∈ [1, L])
Addition:Xk′=∑Xi,(i∈[1,L])
第三步:
F
P
N
:
X
k
′
=
X
k
+
1
′
+
X
k
′
这里
X
L
′
=
X
L
FPN: X_k ' = X_{k+1}' + X_k' 这里 X_L' = X_L
FPN:Xk′=Xk+1′+Xk′这里XL′=XL
即最后一层就是它自己。
这里仅仅是对各个层次特征信息的汇总具体的筛选还得看下面的模块!
门控特征融合 (Gated Fully Fusion )
多水平融合的基础任务是去放大有用的信息,门控操作基于简单的加法融合加上信息流的gate机制设计而成。每一层的
l
l
l都是由一个gate map协助构成,G是
H
×
W
H × W
H×W的
0
、
1
0、1
0、1矩阵,见公式
X
′
=
(
1
+
G
)
∗
X
+
(
1
−
G
)
∗
∑
G
i
⋅
X
i
X' = (1 + G)* X + (1 - G)* ∑ Gi ·Xi
X′=(1+G)∗X+(1−G)∗∑Gi⋅Xi
所以这个特征图是对特征为一的进行两倍的加强。其中 · 操作是其中·表示信道维中的元素式乘法广播,每个门控单元
G
i
=
s
i
g
n
a
l
(
W
i
×
X
i
)
G_i=signal(W_i×X_i)
Gi=signal(Wi×Xi)都用
x
∈
R
1
×
1
×
C
i
x∈R^{1×1×C_i}
x∈R1×1×Ci参数化的卷积层来估计。
i
i
i的取值为所有
L
L
L个门控特征图,详情见图。
GFF结合双门控机制:
只有当
G
i
(
x
,
y
)
G_i(x, y)
Gi(x,y)的值很大 而 GL(x, y)很小时,来自第 i 层特征图 位置(x,y)的一个特征向量 (i ≠ L),就能被融入到 L层中,例如,来自 i 层的有用的信息,但是当它传输到L层就消失了,在这时,信息就能实现从I层到L层的传输。有用的信息能够通过gates被正则化入正确的位置,无用的信息从发送方到接收方之间的传播也能被有效的被抑制,因为无用的信息只有在当前的位置上由无用的信息时才能够接收到!
Comparion with Other Gate module
与其他的门控机制来进行比较,18年有一篇工作使用gate来控制信息流,GFF不同于它的是:使用gates 将来自每一层的特征信息充分融合到各个水平的特征图中而不是单纯层与层之间。而各个层丰富的信息促使我们设计两个门控机制,分别位于接收者和发送方两者,这样就能充分过滤掉无用信息,实验结果能够证明这些好处!
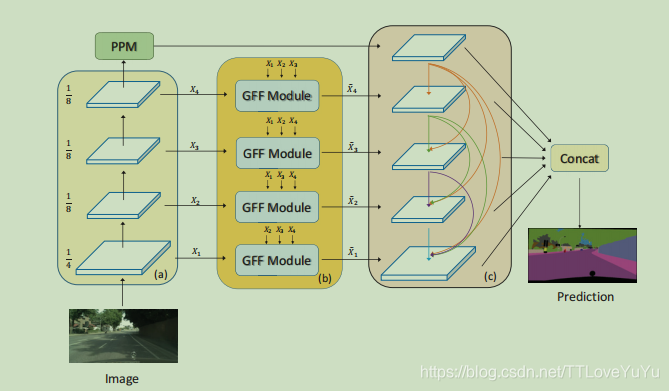
Dense Feature Pyramid
上下文建模的目的是编码更多的全局信息,它与所提出的GFF是正交的,因为GFF是为backbone水平设计的。 因此,我们进一步设计了一个模块,从PSPNet的输出中编码更多的上下文信息(赵等人 和GFF 在这种密集连接的激励下,可以加强特征传播(Huang等人。 我们还从PSPNet输出的特征映射开始,以自上而下的方式密集地连接特征映射,并且高级别的特征映射被多次重用,以向低级别添加更多的上下文信息。
因此,特征金字塔接收前面所有金字塔的特征映射,
y
0
,
X
1
,
.
.
.
X
i
−
1
y_0, X_1,...X_{i−1}
y0,X1,...Xi−1作为输入和输出当前金字塔
y
1
y_1
y1其中
X
0
X_0
X0是PSPNet的输出,
X
i
X_i
Xi是I-GFF模块的输出。 融合函数
H
i
H_i
Hi由单个卷积层实现。 由于特征金字塔是密集连接的,我们将该模块表示为密集特征金字塔(DFP)。 将DFP输出的YI集合用于最终预测。 GFF和DFP都可以插入到现有的FCN中进行端到端的训练,只需要稍微额外的计算成本。
Network Architecture And Implementation
网络架构及实现:
我们的网络是在先前的表现最优的网络PSPNet和ResNet作为网络主干对基础特征析取。ResNet最后两个阶段修改为空洞卷积设置步长为1,保留空间信息。下图展示了整个网络的架构。
PSPNet与主干网和金字塔池模块(PPM)形成了自下而上的路径,其中PPM在顶部,以编码上下文信息。残差主干网络模块的最后阶段的特征图作为GFF模块的输入,并且所有的特征图使用11卷积核来调整通道数至256。GFF输出的特征图使用两个33的卷积核同每一层的输出融合后作为DFP模块的输入。所有的卷积层后面都跟一个BN层和ReLU激活函数,紧跟DFP模块是最后的语义分割部分,所有的特征图都concatenate之后输入到这里。
相比PSPNet,我们的网络模型知识略微增加了参数和计算量,整个网络使用交叉熵函数端对端的修正分割的精度。为了方便培训过程,使用辅助损失和主要损失一起帮助优化跟踪。主要的损失来自网络的输出和辅助输出,使用的是ResNet的三个步骤特征图输出,并且定义权重为0.4。
实验
在这个模块中,我们在Cityscape数据集进行方法分析,并且介绍本结构在其他几个数据集上的效果。
实验细节
使用pytorch 架构, 权重decay设置为1e-4, 使用标准的随机梯度下降法来优化参数,多项式学习率,初始化 lr = 0.001, 学习率衰减使用 0.9 ∗ ( 1 − i t e r t o t a l i t e r s ) i t e r p o w e r 0.9 * (1 - \frac{iter}{total iters} )^{ iterpower} 0.9∗(1−totalitersiter)iterpower。 使用批量归一化算法Batchnormal来防止梯度消失。
Cityscape 数据集,裁剪成 size=864*864的大小,十万次迭代,设置mini-batch size = 8。
ADE20K, COCO-stuff, Pascal Context这三个数据集:设置 size = 512, 15万次迭代,minibatch = 16, 为了避免偶然情况的发生,使用数据增强技术,如随机水平横移,随机裁剪,随机补光,大小为[10, 10], 随机缩放,[0.75, 2]倍。
在Cityscape数据集上的实验
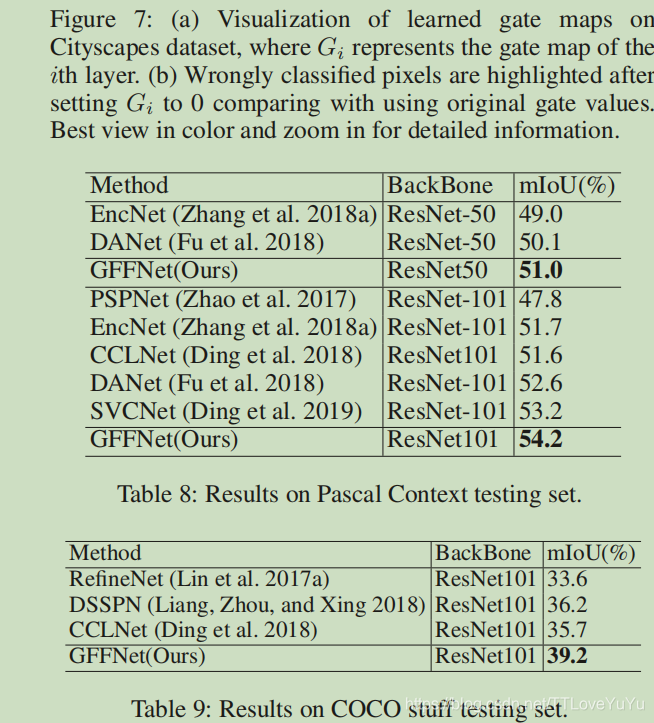
1、介绍数据集:它是一个大规模的语义城市场景理解数据集。 包含5000幅精细像素级注释图像,其中2975幅,500幅,1525幅分别用于训练,验证和测试的图像,训练和验证的标签已被公开发布,测试集的标签被保存以供在线评估。 它还提供了20000个粗注释图像。 对30个类进行注释,其中19个类用于像素级语义标记任务。 图像分辨率大小为1024×2048。 该数据集的评估度量是Union上的平均交集(mIoU)。
2、 强壮的baseline 模型:使用PSPNet作为本文的基础对比模型,本文对PSPNet进行复现,并且实现了78.6%的效果,所有的结果都是使用滑动窗口裁剪来预测。
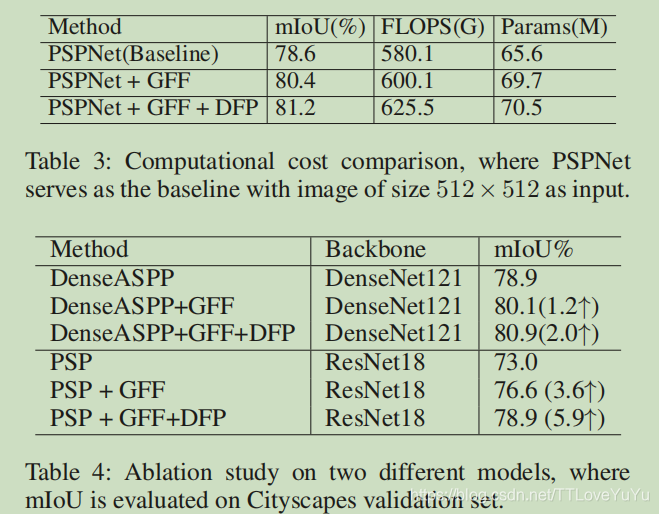
3、特征融合方法的消融实验(ablation study):首先,我们比较了几个方法,为了加速训练过程,(我们使用PSPNet已经训练好的模型参数为初始化),然后使用精炼数据来进行训练,并且对验证集上的表现做出说明。为了公平起见,将训练的通道数降低到256,使用两个3*3的卷积层来对融合的特征进行修正。至于FPN,我们将原始的FPN实现,并且将它加入到PSPNet中。
note :FPN融合了5个特征图,其中一个来自金字塔池化,其余来自backbone!
实验结果如表一所示,正如我们所预料的,连接和假发,都只是轻微的提升了baseline而FPN是三个融合方法中表现最好的,而GFF甚至将mIOU提升到了80.4%。由于GFF是一种基于添加的融合的门控版本,因此研究结果证明了所使用的门控机制的有效性。为了进行进一步的比较,我们还将所提出的门控机制添加到FPN自上而下的路径中,并观察到略有改善。


结论
本文提出了Fated Fully Fusion (GFF)架构 来通过操控gate来充分融合各个层次的特征图。这个新颖的模型架构打通了来自低分辨率的高级语义特征与来自高分辨率的低级语义特征之间的隧道。并在四个验证数据集上都获得了最新的成果。
特别指出:本文发现来自低水平的特征能够被融入到特征金字塔的每一层,而这也是为什么我们的模型能够准确的捕捉到视野范围里的小物体的缘故!
本文是出自北大信息科技学院的人工智能实验室DeepMotion名下,并且在AAAI会议上发表,所以作者花了功夫来精读一番,要是有所帮助,就点个赞吧!

















 2021
2021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









