







 从AlexNet[1]在2012年的LSVRC分类大赛中取得胜利之后,“深度残差网络[2]”可以称得上是近年来计算机视觉(或深度学习)领域中最具开创性的工作了。ResNet的出现使上百甚至上千层的神经网络的训练成为可能,并且训练的成果也是可圈可点的。
从AlexNet[1]在2012年的LSVRC分类大赛中取得胜利之后,“深度残差网络[2]”可以称得上是近年来计算机视觉(或深度学习)领域中最具开创性的工作了。ResNet的出现使上百甚至上千层的神经网络的训练成为可能,并且训练的成果也是可圈可点的。
利用ResNet强大的表征能力,不仅是图像分类,而且很多其他计算机视觉应用(比如物体检测和面部识别)的性能都得到了极大的提升。
自从ResNet在2015年震惊学术界产业界后,许多研究界的专家人员就开始探究其背后的成功之道了,研究人员也对ResNet的结构做了很多改进。这篇文章分为两部分,在第一部分我会为那些对ResNet不熟悉的读者们重温一下这个创新型的工作,而在第二部分我则会简单介绍最近我读过的一些关于ResNet的解读及其变体的论文。
重温ResNet
根据无限逼近定理(Universal ApproximationTheorem),我们知道,只要有足够的容量,一个单层的“前馈神经网络”就已经足以表示任何函数了。但是,这个层可能会非常庞大,所以网络很容易会出现过拟合的问题。对此,学术界有一个常见的做法——让我们的网络结构不断变深。
自AlexNet以来,state-of-the-art的CNN结构都在不断地变深。VGG[3]和GoogLeNet[4]分别有19个和22个卷积层,而AlexNet只有5个。
然而,我们不能通过简单地叠加层的方式来增加网络的深度。梯度消失问题的存在,使深度网络的训练变得相当困难。“梯度消失”问题指的是即当梯度在被反向传播到前面的层时,重复的相乘可能会使梯度变得无限小。因此,随着网络深度的不断增加,其性能会逐渐趋于饱和,甚至还会开始下降。
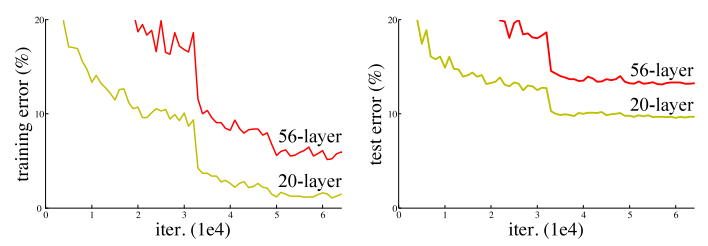
在ResNet出现之前,研究人员们发现了几个用于处理梯度消失问题的方法,比如,[4]在中间层添加辅助损失(auxiliary loss)作为额外的监督。但没有一种方法能够一次性彻底解决这一问题。
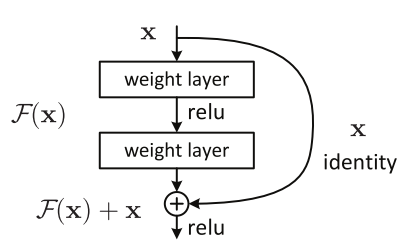
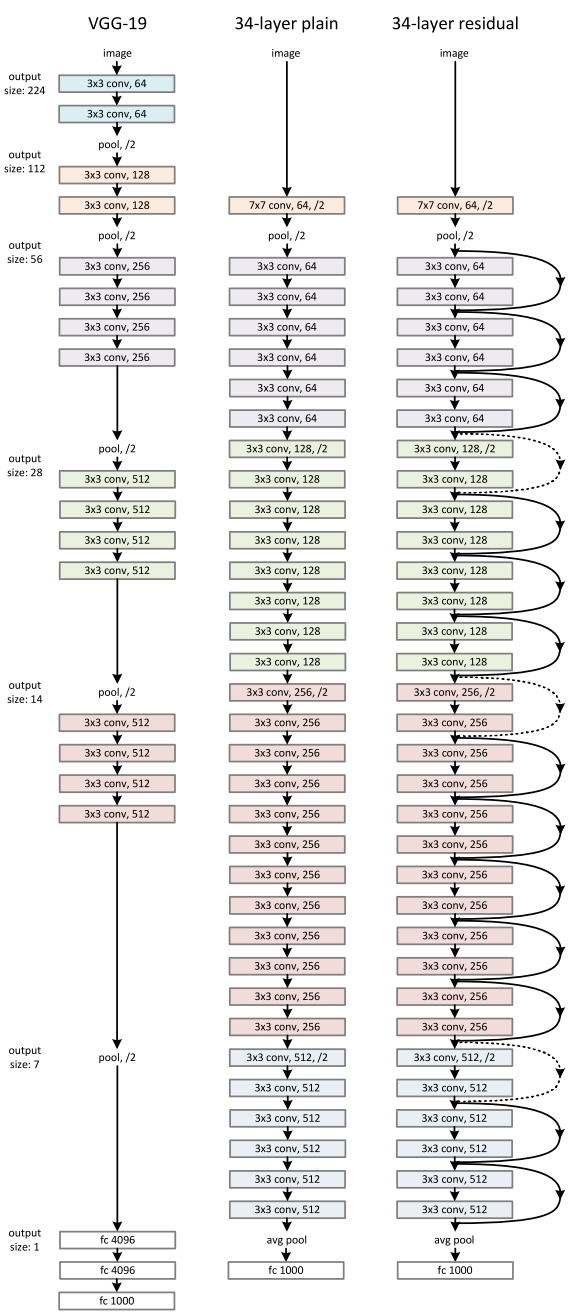
ResNet的基本思想是引入了能够跳过一层或多层的“shortcutconnection”,如上图所示。
[2]的作者认为,增加网络的层不应该降低网络的性能,因为我们可以将“恒等变换(identity mapping)”简单地叠加在网络上,而且所得到的输出架构也会执行相同的操作。这就暗示了更深层的模型的训练错误率不应该高于与之对应的浅层模型。他们还作出了这样的假设:让堆叠的层适应一个残差映射,与让它们直接适应所需的底层映射相比要简单一些,上图所示的残差块能够明确地使它完成这一点。
ResNet并不是第一个利用shortcut connection的,HighwayNetwork[5]引入了“gated shortcut connection”,其中带参数的gate控制了shortcut中可通过的信息量。类似的做法也存在于LSTM[6]单元里,在LSTM单元中也有一个forget gate来控制着流入下一阶段的信息量。因此,ResNet可以被看作是HighwayNetwork的一个特例。
然而实验结果显示,Highway Network的表现并不比ResNet要出色。这个结果似乎有些奇怪,因为Highway Network的解空间(solution space)中包含了ResNet,所以它的性能表现按理来说应该要比ResNet好的。这就表明保持这些“梯度高速路”的畅通可能比追求更大的解空间更重要。
照着这一想法,文章的作者们进一步完善了残差块,并且提出了一个残差块的pre-activ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









