








笔记整理:徐欣,浙江大学硕士
链接:https://arxiv.org/pdf/2303.08559.pdf
简介
本文探究了大型语言模型 (LLMs)和微调的小型预训练语言模型(SLMs)在少样本信息抽取(IE)任务上的表现。本文发现LLMs在IE任务上表现不佳,同时存在高延迟和高开销的缺点,但是LLMs擅长处理对SLMs困难的样本。由此,本文提出了适应性的filter-then-rerank范式,SLMs作为过滤器,LLMs作为重排工具。
构建少样本数据集
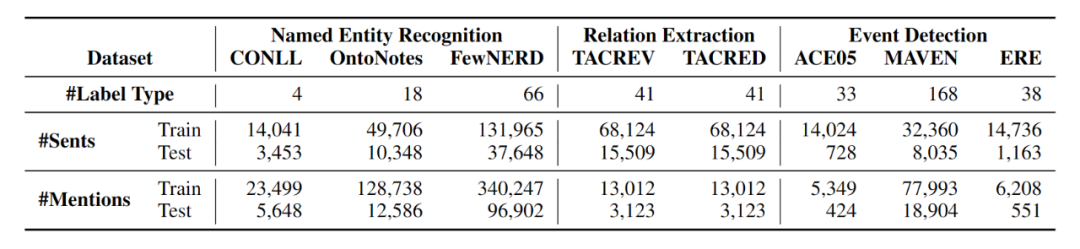
本文在命名实体识别(NER)、关系抽取(RE)和事件检测(ED)三个任务的8个数据集上进行了实验,原数据集统计如上表所示。本文采用K-shot采样,对于NER和ED,K=1,5,10,20;对于RE,K=1,5,10,20,50,100。如果K-shot数据集包含大于300个句子,按1:9分出验证集和训练集;如果小于300个句子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6630
6630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









