






 本文详细介绍了知识图在RAG管道中的各个阶段的应用,包括预处理中的查询增强、块提取时的文档层次结构和上下文词典,以及后处理中的递归知识图查询和答案增强。通过一个医学案例,展示了如何通过知识图提高RAG系统在回答问题时的准确性和个性化。
本文详细介绍了知识图在RAG管道中的各个阶段的应用,包括预处理中的查询增强、块提取时的文档层次结构和上下文词典,以及后处理中的递归知识图查询和答案增强。通过一个医学案例,展示了如何通过知识图提高RAG系统在回答问题时的准确性和个性化。
转载公众号 | 蓝蓝的小火苗
在本文中,我想准确介绍知识图 (KG) 在 RAG 管道中的应用领域。
我们将探讨 RAG 管道中出现的不同类型的问题,以及如何通过在整个管道的不同阶段应用知识图来解决这些问题。我们将讨论一个 RAG 管道的实际示例,该管道通过知识图在不同阶段得到增强,并准确说明每个阶段如何改进答案和查询。我希望传达的另一个关键要点是图技术的部署更类似于结构化数据存储,用于战略性地在 RAG 系统中注入人类推理,而不是简单地为所有目的查询结构化数据的通用存储。
有关复杂 RAG 和多跳数据检索的背景,请查看此非技术介绍和更具技术性的深入探讨。

让我们使用上图所示的阶段来介绍启用 KG 的 RAG 过程中不同步骤的术语:
第一阶段:预处理:这是指在使用查询帮助从矢量数据库中提取块之前对其进行的处理
第二阶段:块提取:这是指从数据库中检索最相关的信息块
第三-五阶段:后处理:这是指您为准备检索到的信息以生成答案而执行的过程
我们将首先展示不同阶段应该使用哪些技术,并在文章末尾提供一个实际示例。
预处理
1. 查询增强:在从矢量数据库执行检索之前向查询添加上下文 原因:此策略用于增强缺少上下文的查询并修复错误的查询。这也可以用来注入公司的世界观,即他们如何定义或看待某些常见或利基术语。
在很多情况下,公司可能对特定术语有自己的世界观。例如,一家旅游科技公司可能希望确保 GPT-4 的开箱即用法学硕士能够理解“海滨”房屋和“靠近海滩”房屋代表非常不同类型的房产,并且不能互换使用。在预处理阶段注入此上下文有助于确保 RAG 管道中的这种区别可以提供准确的响应。
从历史上看,知识图谱在企业搜索系统中的常见应用是帮助构建首字母缩略词词典,以便搜索引擎可以有效地识别所提出的问题或文档/数据存储中的首字母缩略词。
正如我们在上一篇文章中阐述的那样,这可以用于多跳推理。
时间:第一阶段
进一步阅读:https ://www.seobythesea.com/2019/08/augmented-search-queries/
块提取
1. 文档层次结构:创建文档层次结构和用于在矢量数据库中导航块的规则 原因:这用于快速识别文档层次结构中的相关块,并使您能够使用自然语言创建规则来指示查询在生成响应之前必须引用哪些文档/块。
第一知识图可以是引用存储在向量数据库内的块的文档描述的层次结构。
第二个知识图可以用于导航文档层次结构的规则。例如,考虑风险基金的 RAG 系统。您可以编写一条自然语言规则,确定性地应用于查询规划代理“要回答有关投资者义务的问题,首先检查投资者在投资者投资组合列表中投资的内容,然后检查所述投资组合的法律文件”。
时间:第二阶段
进一步阅读:
https://docs.llamaindex.ai/en/stable/examples/query_engine/multi_doc_auto_retrieval/multi_doc_auto_retrieval.html
https://medium.com/enterprise-rag/a-first-intro-to-complex-rag-retrieval-augmented- Generation-a8624d70090f
2. 上下文词典:创建用于在矢量数据库中导航块的概念结构和规则 原因:上下文词典对于理解哪些文档块包含重要主题非常有用。这类似于书后的索引。

上下文词典本质上是元数据的知识图谱。
该字典可用于维护导航块的规则。您可以包含一条自然语言规则,“任何与幸福概念相关的问题,您必须按照上下文词典的定义对所有相关块进行详尽的搜索。” 查询规划代理中的 LLM 代理将其转换为 Cypher 查询,以增加要提取的块。建立这样的规则也可以保证chunk提取的一致性。
这与简单的元数据搜索有何不同?除了提高速度之外,如果文档简单的话那就不行了。但是,在某些情况下,您可能希望确保特定的信息块被标记为与某个概念相关,即使该块中可能未提及或暗示该概念。当讨论正交信息(即与特定概念有争议或不一致的信息)时,可能会发生这种情况。上下文词典可以轻松地与不明显的信息块建立清晰的关联。
时间:第二阶段
进一步阅读:https://medium.com/data-science-at-microsoft/creating-a-metadata-graph-struct-for-in-memory-optimization-2902e1b9b254
后期处理
1. 递归知识图查询 原因:这用于组合提取的信息并存储有凝聚力的联合答案。LLM 查询图表以获取答案。这在功能上类似于思想树或思想链过程,其中外部信息存储在知识图中,以帮助确定下一步的调查。
您基本上一次又一次地运行块提取,检索提取的信息,并将其存储在知识图中以强制连接以揭示关系。建立关系并将信息保存在知识图谱中后,使用从知识图谱中提取的完整上下文再次运行查询。如果上下文不足,请再次将提取的答案保存在同一 KG 中以强制执行更多连接并冲洗/重复。
如果数据不断流入您的系统并且您希望确保答案随着时间的推移根据新的上下文进行更新,这也特别有用。
时间:第三阶段
进一步阅读:https://neo4j.com/developer-blog/knowledge-graphs-llms-multi-hop-question-answering/
2. 答案增强:根据向量数据库最初生成的查询添加上下文 原因:这用于添加任何答案中必须存在的附加信息,这些信息涉及无法检索或向量数据库中不存在的特定概念。这对于在基于提到或触发的某些概念的答案中包含免责声明或警告特别有用。
一个有趣的猜测途径还可能包括使用答案增强作为面向消费者的 RAG 系统的一种方式,当某些答案提到某些产品时,在答案中包含个性化广告。
时间:第四阶段
3. 答案规则:根据KG中设定的规则进行结果的淘汰和重复 原因:这用于强制执行有关可以生成的答案的一致规则。这会对信任和安全产生影响,您可能希望消除已知的错误或危险答案。演示:https: //youtu.be/Ukz_wgLBNqw
Llamaindex有一个有趣的例子,使用维基百科的知识图来仔细检查 LLM 的答案是否真实:https://medium.com/@haiyangli_38602/make-meaningful-knowledge-graph-from-opensource-rebel-model- 6f9729a55527。这是一个有趣的例子,因为尽管维基百科不能作为内部 RAG 系统的基本事实来源,但您可以使用客观的行业或常识知识图谱来防止 LLM 幻觉。
时间:第五阶段
4. 块访问控制:原因:知识图可以强制执行有关用户可以根据其权限检索哪些块的规则。
例如,假设一家医疗保健公司正在构建一个 RAG 系统,其中包含对敏感临床试验数据的访问权限。他们只希望特权员工能够从向量存储中检索敏感数据。通过将这些访问规则存储为知识图数据的属性,他们可以告诉 RAG 系统仅在用户被允许的情况下检索特权块。
时间:第六阶段(见下文)
1 / 4 / 6. 块个性化:原因:知识图可用于个性化对用户的每个响应。
例如,考虑一个企业 RAG 系统,您希望在其中为每个办公室的每个员工、团队或部门自定义响应。在生成答案时,RAG 系统可以咨询 KG,以根据用户的角色和位置了解哪些块包含最相关的信息。
您需要包含上下文以及该上下文对每个答案意味着什么。
然后,您可能希望将该上下文包含为提示或答案增强。
该策略可以建立在块访问控制的基础上。一旦 RAG 系统确定了该特定用户最相关的数据,它还可以确保该用户确实有权访问该数据。
何时:此功能可以包含在第 1、4 或 6 阶段中。
结合了所讨论的所有用例的实际示例
让我们用医学领域的一个例子来解构这一点。在这篇文章中,Wisecube 提出了以下问题:“阿尔茨海默病治疗的最新研究是什么?” 改造 RAG 系统以利用上述策略可以采用以下步骤。明确地说,我们并不认为每个 RAG 系统都一定需要以下全部甚至任何步骤。我们认为这些技术可用于特定用例,我们认为这些技术在复杂的 RAG 用例中相对常见,也可能适用于一些简单的用例。
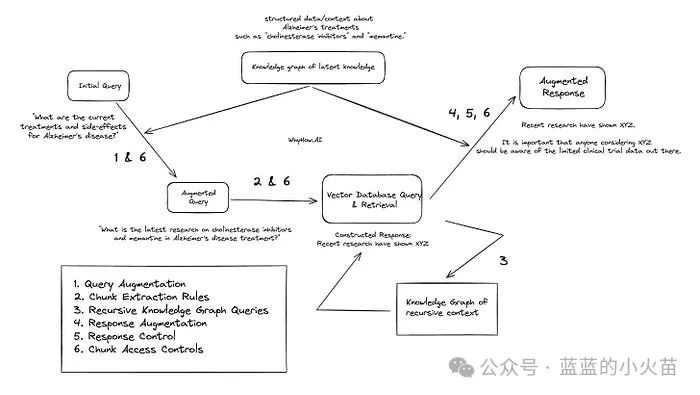
在这里,我将文章顶部的初始图像中的相同初始阶段映射到此处的该图像中,因此 RAG 过程中的编号阶段是对齐的,还有几个附加阶段。然后,我们结合讨论的所有技术(块增强、块提取规则、递归知识图查询、响应增强、响应控制、块访问控制)——相应的阶段 1 到阶段 6。
1. 查询增强:对于“阿尔茨海默病治疗的最新研究是什么?”这个问题,通过访问知识图谱,法学硕士代理可以一致地检索有关最新阿尔茨海默病治疗的结构化数据,例如“胆碱酯酶抑制剂”和“美金刚”。
然后,RAG 系统会将问题变得更加具体:“胆碱酯酶抑制剂和美金刚在阿尔茨海默病治疗中的最新研究是什么?”
2. 文档层次结构和矢量数据库检索:使用文档层次结构,确定哪些文档和块与“胆碱酯酶抑制剂”和“美金刚”最相关,并返回相关答案。
关于“胆碱酯酶抑制剂”存在的相关块提取规则有助于指导查询引擎提取最有用的块。文档层次结构帮助查询引擎快速识别与副作用相关的文档,并开始提取文档中的块。
上下文字典帮助查询引擎快速识别与“胆碱酯酶抑制剂”相关的块,并开始提取与该主题相关的块。关于“胆碱酯酶抑制剂”的既定规则规定,有关胆碱酯酶抑制剂副作用的查询还应该检查与酶 X 相关的块。这是因为酶 X 是众所周知的副作用,不容错过,相关块也包含在内因此。
3. 递归知识图查询:使用递归知识图查询,初始查询会返回“memantime”的副作用,称为“XYZ 效应”。
“XYZ 效应”作为上下文存储在递归上下文的单独知识图中。
要求法学硕士使用 XYZ 效应的附加上下文检查新增强的查询。根据过去格式化的答案来衡量答案,它确定需要有关 XYZ 效应的更多信息才能构成令人满意的答案。然后,它在知识图谱内的 XYZ 效应节点内执行更深入的搜索,从而执行多跳查询。
在 XYZ 效应节点中,它会发现有关临床试验 A 和临床试验 B 的信息,并将其包含在答案中。
4. 块控制访问 尽管临床试验 A 和 B 都包含有用的上下文,但与临床试验 B 节点关联的元数据标签指出,用户对该节点的访问受到限制。因此,常设控制访问规则可防止临床试验 B 节点包含在对用户的响应中。
仅有关临床试验 A 的信息会返回给法学硕士,以帮助制定其返回的答案。
5. 增强响应:作为后处理步骤,您还可以选择使用医疗保健行业特定的知识图来增强后处理输出。例如,您可以包含特定于美金刚治疗的默认健康警告或包含与临床试验 A 相关的任何其他信息。
6. 块个性化:由于用户是存储的研发部门的初级员工,并且用户无法获取有关临床试验 B 的信息,因此答案会增加一条注释,说明他们被禁止访问临床试验 B 信息,并且被告知要咨询高级经理以获取更多信息。
与向量数据库相比,使用知识图谱进行查询增强的优点在于,知识图谱可以对关系已知的某些关键主题和概念强制执行一致的检索。在WhyHow.AI,我们正在简化 RAG 管道中的知识图谱创建和管理。
有趣的想法:公司/行业本体货币化
如果构建复杂的 RAG 系统的每个人都需要某种知识图谱,那么知识图谱的市场可能会呈指数级增长,创建和需要的小型本体的数量也会呈指数级增长。如果属实,本体买家和卖家的市场动态将变得更加分散,本体市场也会变得有趣。
个性化:数字孪生
尽管我们将个性化定义为对用户和向量数据库之间信息流的控制,但个性化也可以理解为对识别用户的特征的封装。
作为数字孪生的知识图可以反映更广泛的用户特征集合的存储,这些特征可用于一系列个性化工作。就知识图谱是外部数据存储(即LLM模型外部)而言,它更容易以连贯的形式提取(即知识图谱数据可以以更模块化的方式插入、播放和删除) 。理论上,可以提取额外的个人上下文并将其作为个人数字孪生/数据存储进行维护。如果未来存在允许用户在模型之间移植个人偏好的模块化数字孪生,那么知识图很可能将代表系统和模型之间这种模型间个性化的最佳手段。
英文链接:https://medium.com/enterprise-rag/injecting-knowledge-graphs-in-different-rag-stages-a3cd1221f57b
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









