







前言
大型语言模型 (LLM) 的第一波炒作来自 ChatGPT 和类似的基于网络的聊天机器人,相信在座的各位都并不陌生了,甚至不少人也已经以不同的方式试用过它的功能,这些模型非常擅长理解和生成文本,但是也存在一些问题。
LLM 的一大问题是所谓的知识截止。知识截止术语表明大模型不知道训练后发生的任何事件。例如,如果我们向 ChatGPT 询问 2023 年的事件,我们将得到以下响应。
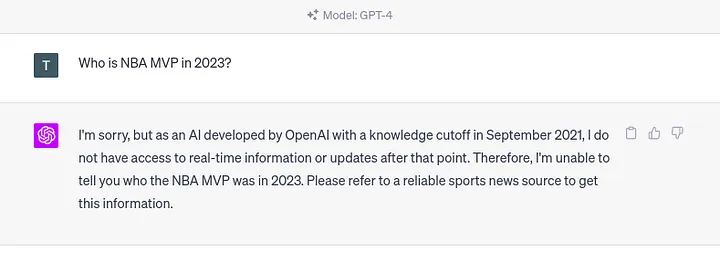
如果我们向大模型询问其训练数据集中不存在的事件,也会出现同样的问题。因为大模型不仅无法获取知识截止日期以后的知识,也不了解任何可能可用的私人或机密信息。更不用说大模型知道的许多公开信息可能已经过时了。
因此,更新和扩展大模型的知识在今天非常重要。
大模型的另一个问题是,他们接受的训练是尽可能生成听起来逼真的文本,但这些文本可能并不准确。有些虚假的信息比其他信息更难发现。特别是对于缺失的数据,LLM 很可能会编造一个听起来令人信服但实际上是错误的答案,也就是我们所说的大模型会产生幻觉。
因此,我们在使用时必须非常小心,不要盲目相信大模型所提供的一切。验证大模型的答案或产生更准确的结果是另一个需要解决的大问题。
当然,大模型还有其他问题,比如偏见、快速注入等等。不过,我们不会在这里讨论它们。在这篇文章中,我们将介绍并重点讨论微调和检索增强大模型(RAG)的概念,并评估它们的优缺点。
LLM 的监督微调
我们可以通过提供额外的问答对在监督训练阶段微调大模型,以此来优化大模型的性能。
此外,我们还确定了两种不同的方法来微调大模型。
一个方法是微调模型以更新和扩展其内部知识。
另一个方法侧重于针对特定任务(例如文本摘要或将自然语言翻译为数据库查询)微调模型。
首先,我们将讨论第一个方法,使用微调技术来更新和扩展大模型的内部知识。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











