







笔记整理:沈小力,东南大学硕士,研究方向为多模态知识图谱
链接:https://arxiv.org/pdf/2308.14346v1
1. 动机
近来,随着深度学习技术的进步,大语言模型(Large Language Model, LLM)在多种自然语言处理任务中取得了喜人的成果,特别是在创建端到端指令遵循的对话系统方面的潜力。另一方面,大健康以及智能医疗这一话题占据了社会舆论的前沿,逐渐成为人们优先、重点考虑的问题。在这一背景下,本文致力于开发一个智能医疗对话系统,以更广泛地提供专业、可访问且负担得起的医疗资源,确保医疗资源公平分配,并提高医疗保健提供者和患者之间的沟通效率。
然而,医疗咨询场景复杂,个人助手需有深厚医学知识和多轮对话能力以提供专业回答。通用语言模型常缺乏医学知识,易答非所问且缺乏满意的多轮追问能力。此外,高质量中文医学数据集稀缺,给训练医疗专业语言模型带来挑战。
为了面对这些挑战,复旦大学数据智能与社会计算实验室(FudanDISC)发布中文医疗健康个人助手——DISC-MedLLM。该团队精心构造了包含47万高质量的监督微调(SFT)数据集——DISC-Med-SFT,在通用领域中文大模型Baichuan-13B上进行训练。在单轮问答和多轮对话的医疗健康咨询评测中,模型的表现相比现有医学对话大模型展现出明显优势。
2. 贡献
(1)本文解决了构建综合文档存储库并确保检索器和查询语义之间的一致性的挑战,这些挑战是开发智能医疗对话系统的重大障碍。
(2)本文发布中文医疗健康个人助手——DISC-MedLLM,在单轮问答和多轮问答任务中相比现有医学对话大模型展现出明显优势。
(3)本文发布了包含47万高质量的监督微调(SFT)数据集——DISC-Med-SFT。
(4)本文讨论了现有医疗对话系统的局限性,例如适用范围有限和集成困难,并提出了未来潜在的改进方向。
3. 方法
DISC-MedLLM是基于高质量数据集DISC-Med-SFT在通用领域中文大模型Baichuan-13B上训练得到的医疗大模型。模型的优势以及框架图如图1所示,该模型从真实咨询场景中计算得到病人的真实分布,以此指导数据集的样本构造。进一步,该模型基于医学知识图谱和真实咨询数据,使用大模型和真人问询两种思路,进行数据集的构造。
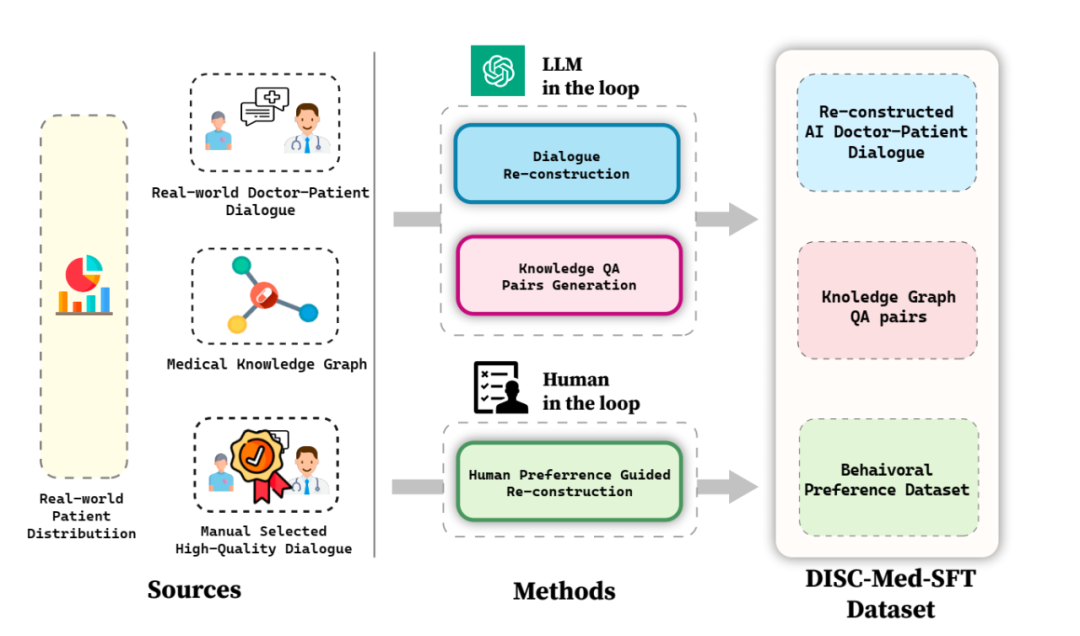
图 1 模型优势以及框架图
3.1 数据集DISC-Med-SFT的构造
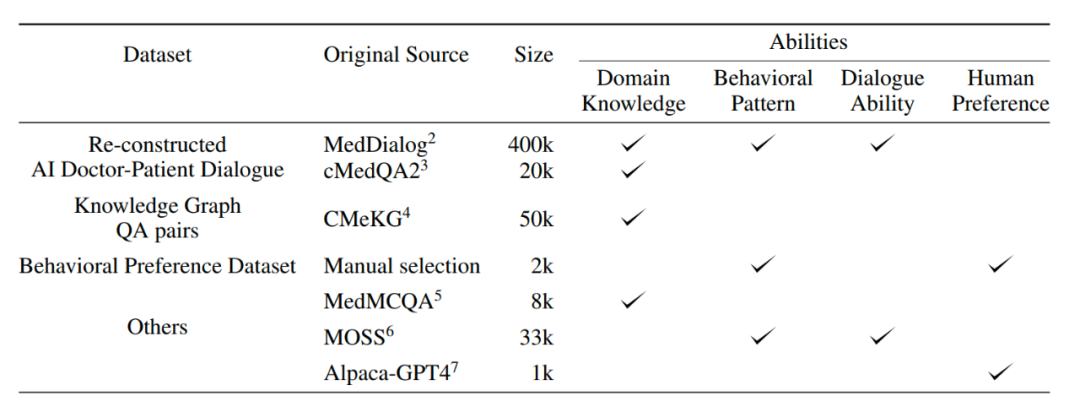
DISC-Med-SFT数据集包含重构AI医患对话、知识图谱问答对、行为偏好数据集等部分,如下表所示:
表 1 DISC-Med-SFT数据集介绍
其中,重构AI医患对话分别从两个公共数据集MedDialogc和MedQA2中选择40万个和2万个样本,作为SFT数据集构建的源样本。为了将真实世界医生回答调整为所需的高质量的统一格式的回答,该模型利用GPT-3.5来完成这个数据集的重构过程。重构的示例如图二所示。可以看出,调整后医生的回答与AI医疗助手的身份一致,既坚持原始医生提供的关键信息,又为患者提供更丰富全面的帮助。

图 2 AI医患对话重构示例
此外,该模型在CMeKG的基础上,根据疾病节点的科室信息在知识图谱中进行采样,利用适当设计的GPT-3.5模型Prompts,总共生成了超过5万个多样化的医学场景对话样本。
另外,在训练的最终阶段,为了进一步提高模型的性能,该模型使用更符合人类行为偏好数据集进行次级监督微调。从MedDialog和cMedQA2两个数据集中人工挑选了约2000个高质量、多样化的样本,在交给GPT-4改写几个示例并人工修订后,使用小样本的方法将其提供给GPT-3.5,生成高质量的行为偏好数据集。
3.2 模型训练
如图3所示,DISC-MedLLM的训练过程分为两个SFT阶段。第一阶段使用不同的数据集为模型配备领域知识和医学对话能力。在第二阶段,模型的性能通过符合人类偏好的行为偏好数据集得到增强。
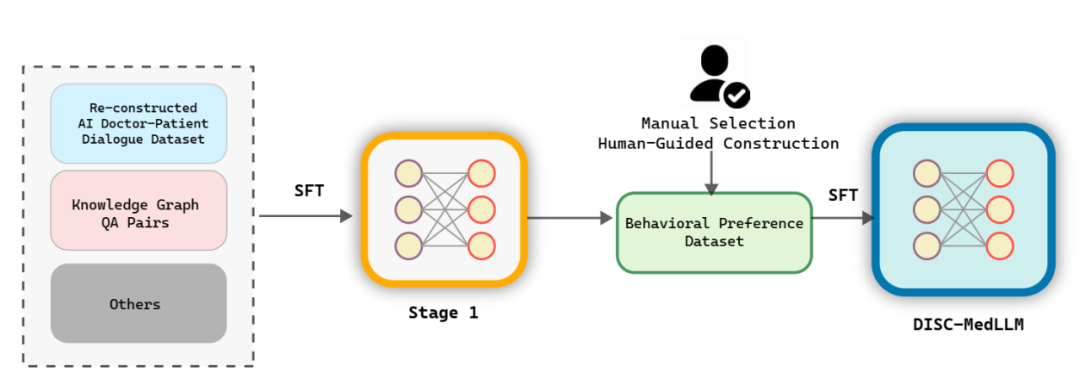
图 3 模型训练架构图
4. 实验结果
本文在两个在两个场景中评测医学LLMs的性能,即单轮QA和多轮对话。
单轮QA评测:为了评估模型在医学知识方面的准确性,我们从中国国家医疗执业医师资格考试(NMLEC)和全国硕士研究生入学考试(NEEP)西医306专业抽取了1500+个单选题,评测模型在单轮QA中的表现。
多轮对话评测:为了系统性评估模型的对话能力,我们从三个公共数据集——中文医疗基准评测(CMB-Clin)、中文医疗对话数据集(CMD)和中文医疗意图数据集(CMID)中随机选择样本并由GPT-3.5扮演患者与模型对话,提出了四个评测指标——主动性、准确性、帮助性和语言质量,由GPT-4打分。
表 2 单轮QA评测结果
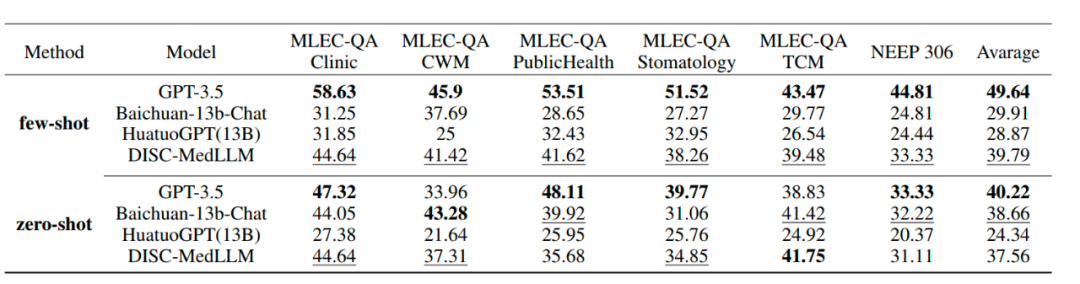
单轮QA结果单项选择题评测的总体结果显示在上表中。GPT-3.5展现出明显的领先优势。DISC-MedLLM在小样本设置下取得第二名,在零样本设置中落后于Baichuan-13B-Chat,排名第三。值得注意的是,本文模型的表现优于采用强化学习设置训练的HuatuoGPT(13B)。
表 3 多轮对话评测结果
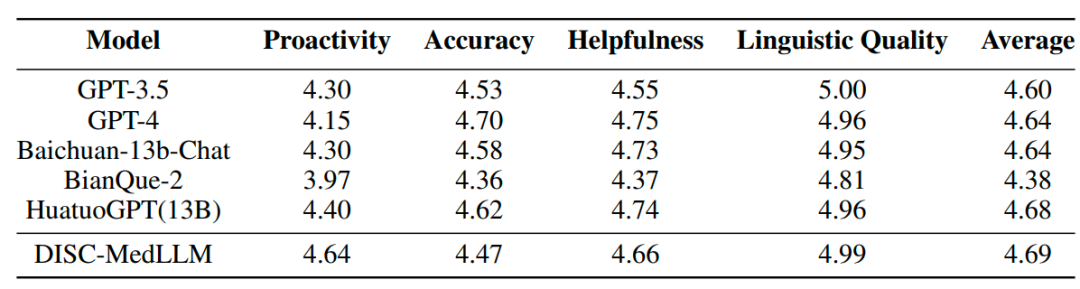
多轮对话结果在CMB-Clin评估中,DISC-MedLLM获得了最高的综合得分,HuatuoGPT紧随其后。我们的模型在积极性标准中得分最高,凸显了我们偏向医学行为模式的训练方法的有效性。
5. 总结
本文提出了DISC-Med-SFT数据集,利用了真实世界对话和通用领域的大型语言模型(LLM)来加强其在特定领域的知识、医学对话技能和对人类偏好的理解。通过对这些关键领域的专注,该数据集成功地训练出了DISC-Med-LLM模型,这是一种高度先进的医疗大模型,特别在医疗交互领域显示出显著的进步。
这一进步不仅仅体现在技术层面,DISC-MedLLM模型还展示了极高的实用性和广泛的应用潜力。它的高效性和准确性使其成为在线医疗领域的一大创新,有望极大地降低在线医疗咨询和治疗的成本,同时提高服务质量。此外,这种技术的发展还将推动医疗资源的普及,使得原本难以触及的区域和群体也能享受到优质的医疗服务。
更为重要的是,DISC-MedLLM模型的出现将使得个性化医疗服务更加便捷可行。通过深入了解和适应个体的医疗需求和偏好,该模型能够提供更加定制化的建议和治疗方案,从而为用户带来更加贴心和有效的医疗体验。在大健康事业的背景下,这种技术的发展不仅能提高医疗服务的质量和效率,还将带来更广泛的社会和经济影响,为未来医疗领域的发展开辟新的道路。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









