






转载公众号 | 老刘说NLP
今天我们一起来看看知识图谱领域的知识推理问题,其数据有哪些,跟大模型结合怎么做。
一、知识图谱领域中的知识推理任务界定
知识图谱中的推理知识推理是指根据知识图谱中已有的知识,采用某些方法,推理出新的知识(知识图谱补全)或识别知识图谱中错误的知识(知识图谱去噪),前者专注于扩充知识图谱,后者专注于知识图谱内部已有三元组正确性的判断。
进一步的,知识图谱补全,是给定三元组中任意两个元素,试图推理出缺失的另外一个元素。包括连接预测、实体预测、关系预测、属性预测。
其中:实体预测指 给定头实体和关系(关系和尾实体),找出与之形成有效三元组的尾实体(头实体) 。例如,已知(h,r)预测t,一种是在原KG中h存在r这条边,但在测试集的t不在(h,r)后(缺失答案实体)。
关系预测指给定头实体和尾实体,找出与之形成有效三元组的关系。原KG中的h不存在r这条边(缺失边)。
不过,无论实体预测还是关系预测,最后都转化为选择与给定元素形成的三元组更可能有效的实体/关系作为推理预测结果,这种有效性可以通过规则的方式推理或通过基于特定假设的得分函数计算。而知识图谱去噪,实际上是在判断三元组的正确与否。
知识图谱补全任务模型主要有基于表示学习和基于规则两种。基于表示学习的方法先通过表示学习得到知识图谱中实体和关系的表示,然后利用得分函数对候选实体进行打分排序,选取得分最高的候选实体作为正确实体。
二、大模型时代的知识图谱推理思路
大模型时代下进行知识图谱推理,目前已经出现了多种方式
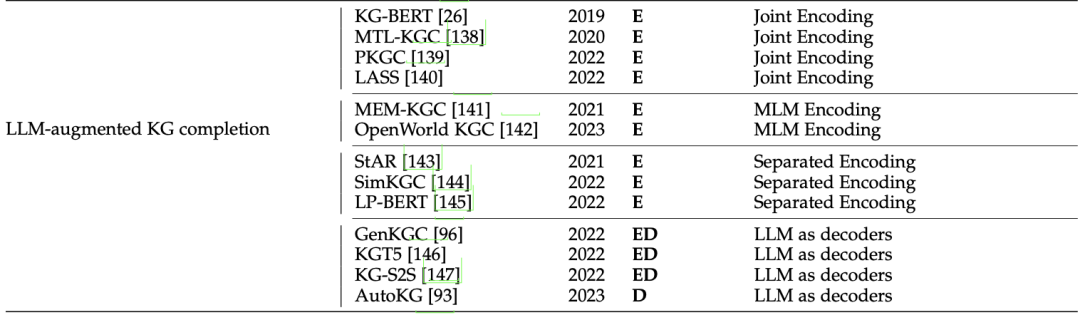
例如,将LLM作为文本编码器。给定一个来自KG的三元组(h,r,t),它首先使用LLM编码器将实体h、t和关系r的文本去脚本化编码为以下表示形式
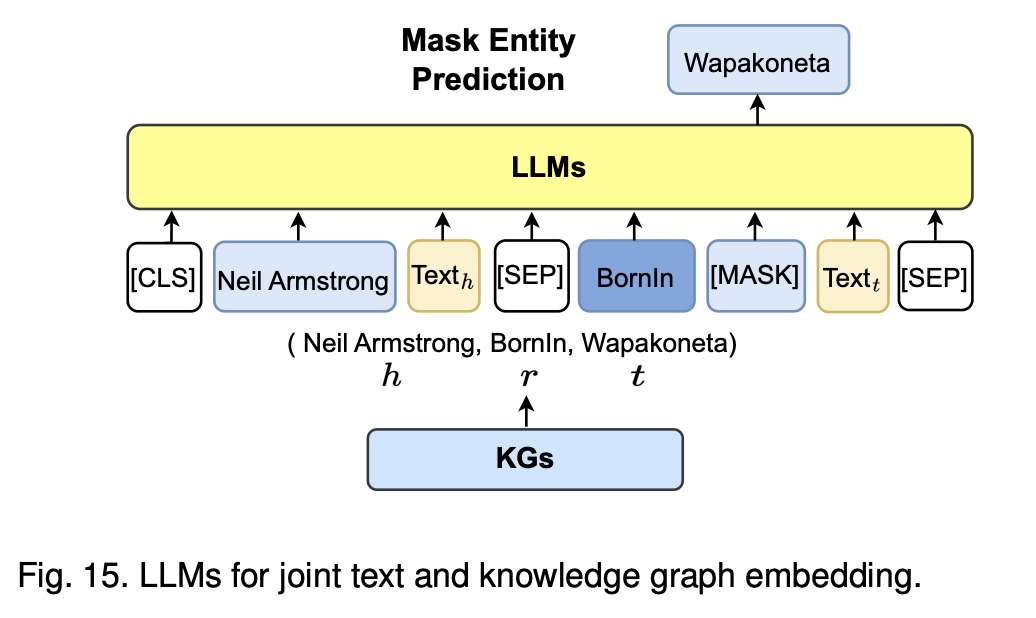
或者直接使用大模型作为尸体以及文本的联合编码器进行建模
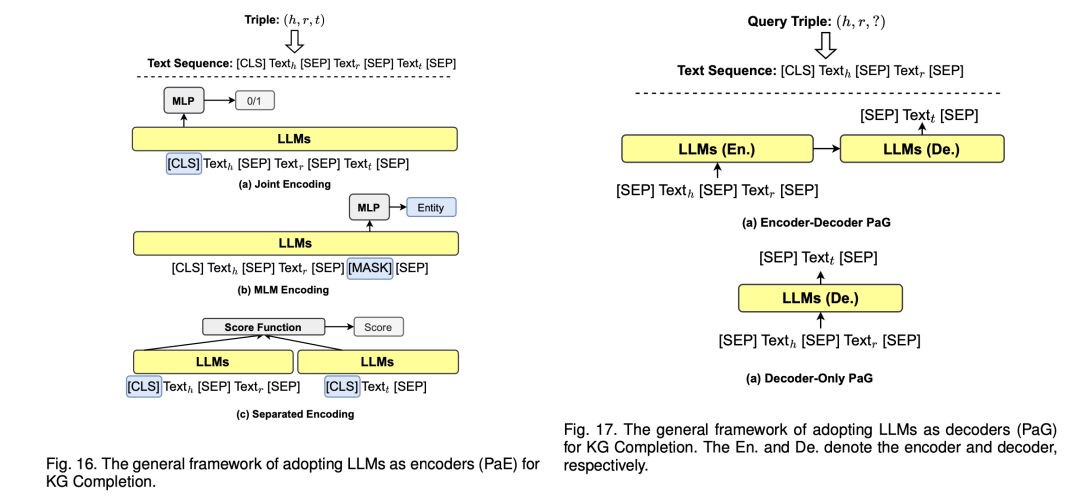
或者使用提示方式进行处理。
例如,一个三元组织查询(迈阿密,位置,?)可能有一个提示 "迈阿密位于[MASK]",其中"<主体>位于[MASK]"是 "位置 "关系的模版,训练目标是用PLM的预测来正确填充[MASK];
BertNet提出了一种应用GPT-3的方法,以输入实体对和手动种子提示自动生成一个加权的提示en-semble。然后,再次使用PLM进行搜索,并将排名靠前的实体对与集合体进行配对,以使KG完成补全。
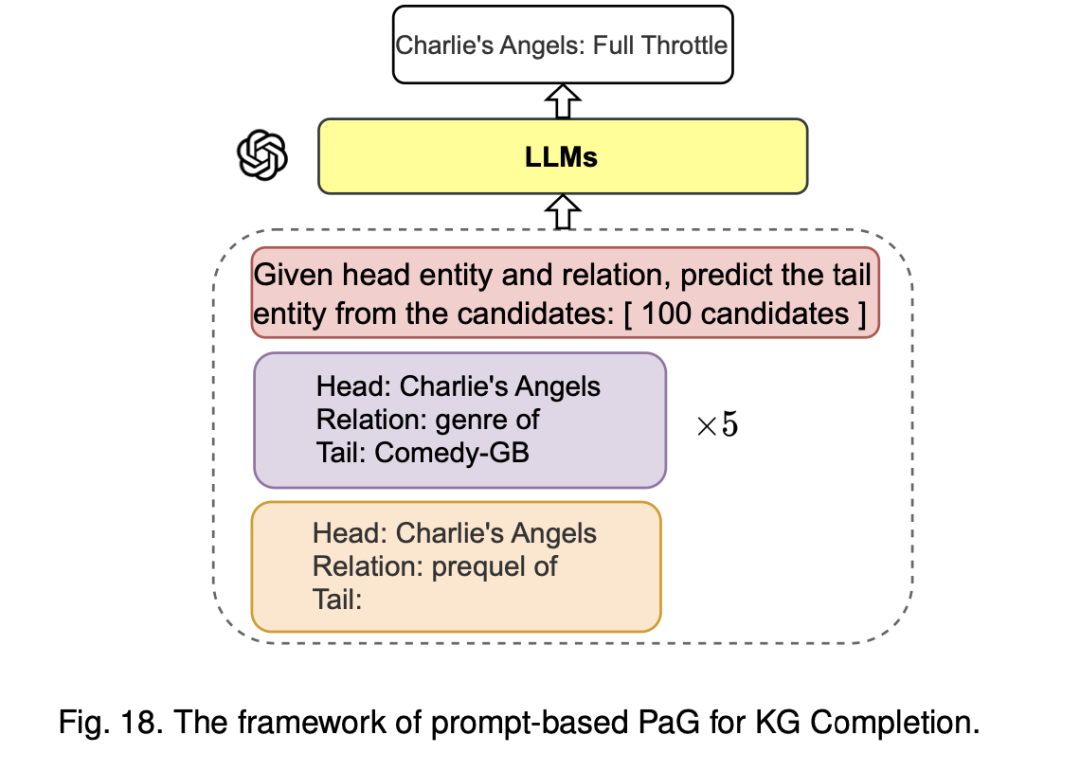
其中进一步的细节,可以查看:《Unifying Large Language Models and Knowledge Graphs: A Roadmap》(https://arxiv.org/pdf/2306.08302)
三、知识图谱推理常用数据集有哪些?
知识图谱补全任务,是为了评测知识图谱表示学习的重要途径,当前,已经陆续出现了一些具有代表性的评测数据集。
1、FB15k
整个Freebase知识图谱共有19亿个三元组,FB15k是FreeBase的子集,15k表示其中有15k(14951)个实体。FB15k数据集中包含很多反向关系,训练集中大约有70%的比例,例如:(Avatar, film/directed_by, James Cameron)和 (James Cameron, director/film, Avatar)是一对反向三元组。
地址: https://web.informatik.uni-mannheim.de/pi1/kge-datasets/fb15k.tar.gz
2、FB15k-237
FB15k-237是知识图谱Freebase的子集,移除了FB15K中的逆三元组,即反向关系三元组。
地址: https://web.informatik.uni-mannheim.de/pi1/kge-datasets/fb15k-237.tar.gz
3、WN18
WN18是wordNet的子集,包含18种关系和40k种实体。WN18也存在反向关系的问题,18种关系中14种关系构成了7对反向关系对。
例如(europe, has_part, republic_of_estonia)和(republic_of_estonia, part_of, europe)是反向三元组,它们涉及到的反向关系是has_part和part_of。WN18中还有三种自反关系:verb_group、similar_to和derivationally_related_form。
地址: https://web.informatik.uni-mannheim.de/pi1/kge-datasets/wn18.tar.gz
4、WN18rr
WN18rr是从WordNet抽取的子集,共40943个实体、11种关系。在WN18的基础上移除了逆三元组。WN18RR有层级结构导致对所有不处理传递关系的补全模型都提出了很大的挑战。
地址: https://web.informatik.uni-mannheim.de/pi1/kge-datasets/wnrr.tar.gz
5、YAGO3-10
YAGO3-10是YAGO数据集的子集,共123182个实体,37种关系。 地址: https://web.informatik.uni-mannheim.de/pi1/kge-datasets/yago3-10.tar.gz
6、ogbl-biokg
Open Graph Benchmark (OGB)图学习基准数据集代表,ogbl-biokg基于多个生物医学知识库,节点类型涵盖疾病、蛋白质、药物、副作用及蛋白质功能等生物医学概念,涉及了从分子规模到整个种群的近10万结点之间的51种异构相互作用,构成500多万个三元组。
地址: https://github.com/snap-stanford/ogb
7、ogbl-wikikg2
ogbl-wikikg2数据采集于Wikidata知识库,描述现实世界中约250万个实体间的500多种关系,构成1700多万个事实三元组,其主要难点在于从海量且复杂的已知事实中进行学习,并精准预测实体间的潜在关系。
地址: https://github.com/snap-stanford/ogb
8、其他数据集
此外,还存在如下可用的实体推理数据集。
总结
本文主要对知识推理这个任务在大模型上的任务进行了指引,并介绍了其中的评测数据集,感兴趣的可以跟进参考文献。
参考文献
1、https://blog.csdn.net/a493823882/article/details/120125762
2、https://www.zhihu.com/question/403056317/answer/1303360180
3、https://blog.csdn.net/TgqDT3gGaMdkHasLZv/article/details/105190084
4、https://arxiv.org/pdf/2002.00819.pdf
5、https://blog.csdn.net/weixin_46987878/articl e/details/107057452
6、http://jos.org.cn/html/2018/10/5551.htm
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 1540
1540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









