







笔记整理:和东顺,天津大学硕士,研究方向为软件缺陷分析
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/29889
发表会议:AAAI2024
1. 动机
多文档问答(MD-QA)面临一些关键挑战,这些挑战包括:
逻辑关联推理:MD-QA要求模型能够理解不同文档之间的逻辑关系,并能够从多个文档中抽取和综合相关信息来回答问题。
交替推理与检索:MD-QA的任务要求模型能够在推理和检索之间进行交替操作,即先根据已有信息进行推理,然后根据推理结果检索新的相关信息,如此循环往复直到找到答案。
多模态信息融合:MD-QA可能涉及到多种类型的文档结构,例如表格、页面等,这就要求模型能够处理这些复杂结构中的信息。
高效利用大型语言模型:现有的方法在使用大型语言模型时存在延迟和成本问题,尤其是在需要多次交互式提示的情况下。此外,如何有效地将不同的文档结构融入到提示设计中,以便模型能够理解这些结构,仍然是一个开放的问题。
为了解决上述挑战,本文提出了知识图谱提示(KGP)方法,该方法包括构建知识图谱以及设计基于大型语言模型的图谱遍历代理,从而增强模型在多文档问题回答中的性能。通过这种方式,模型不仅可以理解不同文档间的逻辑关联,还能够在不同文档结构之间高效地进行推理和检索。
2. 贡献
(1)通用知识图谱构建方法。提出了三种在文档上构建知识图谱的方法,将段落或文档结构作为节点,将它们的词义/语义相似性或结构关系作为边。然后在MD-QA中通过检查每个问题的邻域和支持事实之间的重叠程度,对所构建知识图谱的质量进行了实证评估。
(2)利用知识图谱制定提示。设计了一种知识图谱提示(KGP)方法,利用基于 LLM 的知识图谱遍历代理,通过遍历构建的知识图谱来检索与问题相关的上下文。此外,还对该代理进行了微调,以根据访问节点(检索到的段落)自适应地遍历最有希望接近问题的邻域。
(3)验证MD-QA框架的案例研究。本文比较了在图遍历中使用不同类型 LLM 代理时,MD-QA 在不同文档数构建的 KG 上的性能。
3. 方法
3.1 知识图谱构建
本文将段落建模为节点,将它们的词汇/语义相似性建模为边,从而构建图。更具体地说,在图1中,将每篇文档分割成单个段落,对于每个段落 Si,在 KG 中添加一个节点 vi,其特征是该段落 Xi 的文本。然后,通过检查段落节点对之间的词法/语义相似性来添加边。
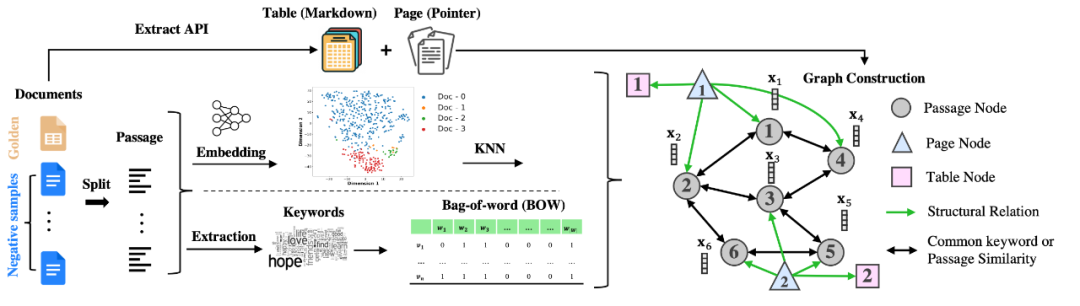
图1 知识图谱构建
TF-IDF KG 构建。为了根据词性相似性添加边缘,首先对每篇文档进行 TF-IDF关键词提取和过滤,这样可以减少词袋(BOW)特征的维度,稀疏所构建的图,并提高图的遍历效率。此外,本文还将文档标题添加到提取的关键词集中,因为有些问题的重点是标题实体。本文收集所有文档中提取的关键词,形成关键词空间 W,然后将 W 中具有共同关键词的两个段落连接起来。
KNN-ST/MDR KG 构建。 为了根据语义相似性添加边缘,可以很容易地使用已有的模型(如句子转换器)为每个节点 vi 生成段落嵌入 Xi,然后计算成对相似性矩阵来构建 K 近邻(KNN)图。然而,这些现成的模型通常是在与 MD-QA 并不相关的任务中训练出来的,可能无法在问题所要求的嵌入相似性中充分囊括必要的逻辑关联。为了克服这一问题,本文采用了 MDR 的训练策略,通过根据先前的支持事实预测后续的支持事实来训练句子编码器,从而赋予编码器推理能力。因此,嵌入相似性和相应构建的 KNN 图从根本上囊括了不同段落之间的必要逻辑关联。
TAGME。此外,我们使用 TAGME从每个段落中提取维基百科实体,并根据两个段落节点是否共享共同的维基百科实体来构建图。
除了段落节点外,还通过 Extract-PDF 3 提取文档结构,进一步将结构节点添加到图中。本文仅考虑添加页面和表格,但构建的 KG 可以包含更多不同类型的文档结构。表格节点的特征是标记符,因为 LLM 可以理解标记符。页面节点的特征是页码,从页码向该页面的句子/表格节点添加有向边。
3.2 基于LLM的知识图谱遍历代理
本文引入了一个基于 LLM 的 KG 遍历代理,它是一个经过微调的 LLM,可以根据从当前访问节点收集到的信息,引导 KG 遍历向下一个最有希望回答问题的通道前进。
给定一个询问文档内容的问题 q,基于 LLM 的图遍历代理会对之前访问过的节点/检索到的段落 {sk} jk=0 进行推理,然后生成下一个段落 sj+1 如下:

其中, 连接先前检索到的段落/访问过的节点的文本信息。对于 的选择,一种方法是采用仅编码器模型,如 Robertabase,相应地,g 将是另一个编码器模型,φ 是测量嵌入相似性的内积。另一种方法是采用编码器-解码器模型,如 T5,相应地,g 将是一个身份函数,φ用来衡量文本的相似性。为了缓解幻觉问题并增强 LLM 遍历代理的推理能力,本文进一步对 进行了指令微调,根据之前的支持事实预测下一个支持事实,从而将原本编码在其预训练参数中的常识性知识与指令微调后增强的推理能力整合在一起。在访问了根据公式(1)从候选邻居队列中选出的得分最高的节点后,候选邻居队列会通过添加这些新访问节点的邻居进行更新。本文反复应用这一过程,直到达到预设预算。接下来,以图 2 为例说明上述过程,并介绍算法。
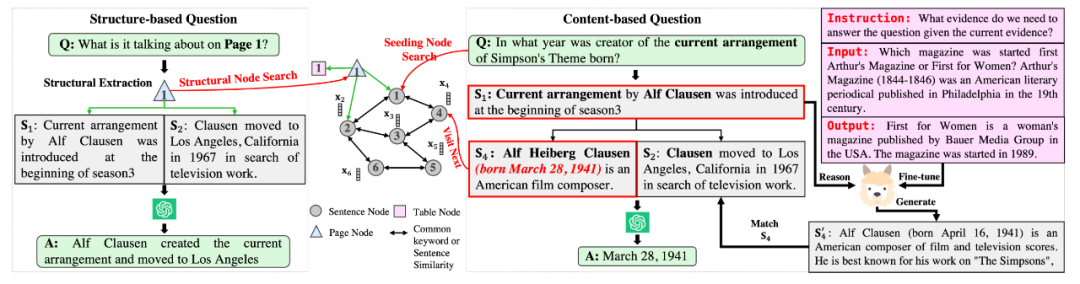
图2 用于上下文检索的基于 LLM 的 KG 遍历代理
图 2 展示了一个基于内容的问题,即 "当前辛普森主题曲编曲的创作者是哪一年出生的?该方法使用 TF-IDF 搜索来初始化节点 1 的种子段落:Alf Heiberg Clausen(生于 1941 年 3 月 28 日),美国电影作曲家。随后,在当前检索到的上下文(节点 1)前加上问题,并提示 LLM 生成下一步接近问题所需的证据。由于通过指令微调增强了 LLM 的推理能力,因此它有望识别问题与当前检索上下文之间的逻辑关联。因此,它可以预测保持逻辑连贯性的后续段落,尽管其中可能包含事实错误,例如,"Alf Clausen(生于 1941 年 4 月 16 日)是一位美国电影和电视配乐作曲家。为了纠正这一潜在的事实错误,该方法从候选邻接中选择与 LLM 生成的段落匹配度最高的节点,在本例中,节点 4 "Alf Heiberg Clausen (born March 28, 1941) is an American film composer"。由于这段话直接来源于文档,因此从本质上确保了信息的有效性。然后,该方法会提示 LLM 与检索到的上下文节点 1 和节点 4,以获得答案。
此外,对于询问文档结构的问题,该方法会提取文档结构名称,并在 KG 中找到其对应的结构节点。对于表格节点,检索其 markdown 格式的内容,而对于页面节点,遍历其一跳邻居并获取属于该页面的段落。
为MD-QA 提出的 KGP 方法的算法如下所示:
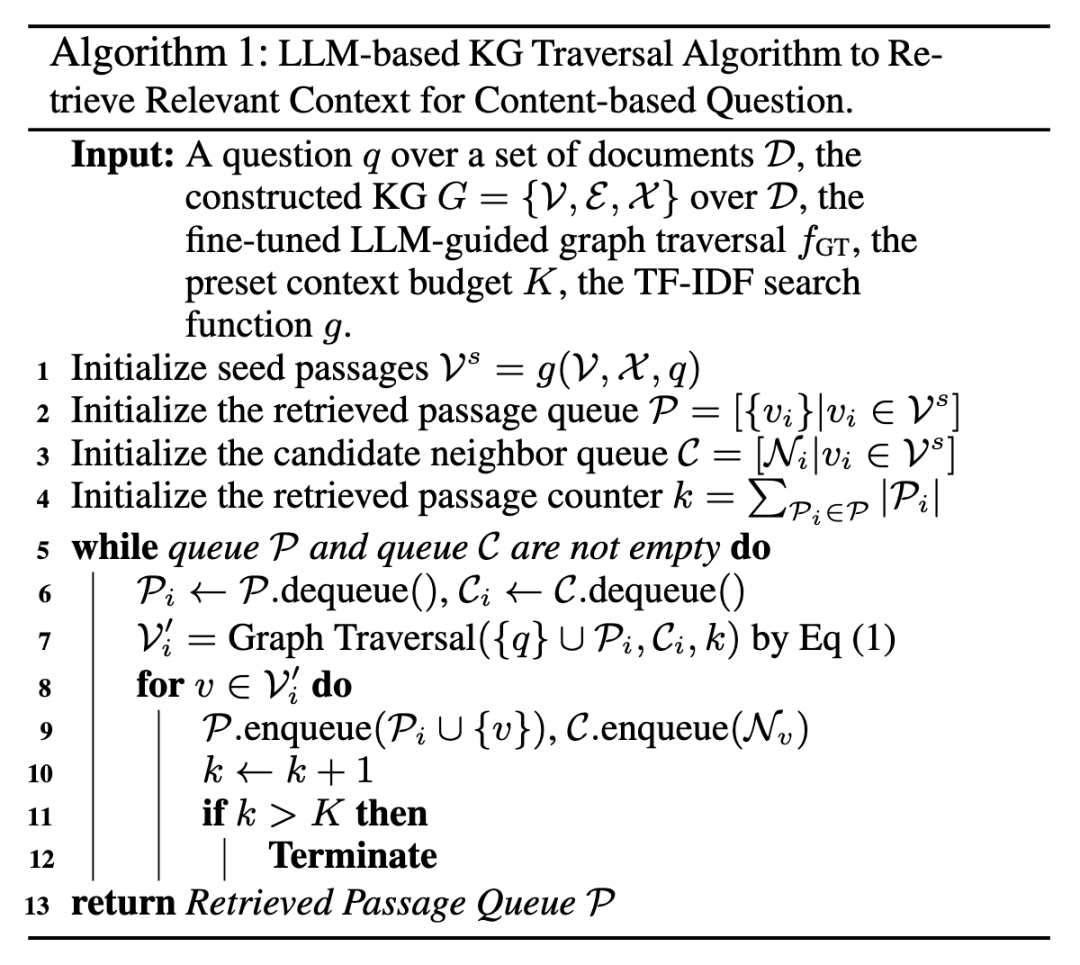
首先应用LLM来区分问题是关于文档结构还是内容。如果问题的重点是文档结构,会提取结构关键词(如页面或表格),并检索 KG 中相应结构节点中的内容。如果问题侧重于文档内容,则按照算法 1 的步骤进行。具体来说,首先通过 TF-IDF 搜索初始化种子段落 和推理路径队列 P。然后,对于每个种子段落 ,将其相邻段落节点 添加到候选相邻队列 C 中(第 1-4 行)。然后,从 P/C 中反复排出最早排出的推理路径/候选邻居 / ,并使用基于 LLM 的微调图遍历代理,根据公式(1)对 中排出的邻居进行排序(第 5-7 行)。最后,根据排名从 中选择前 k 个通过节点 V_i^ 进行下一步访问,并相应更新候选邻居队列和推理路径队列(第 8-13 行)。当候选邻居队列变空或满足检索通道的前缀预算 K 时,上述过程结束。
4. 实验
4.1 与现有基线相比,KGP 的 MD-QA 性能如何?
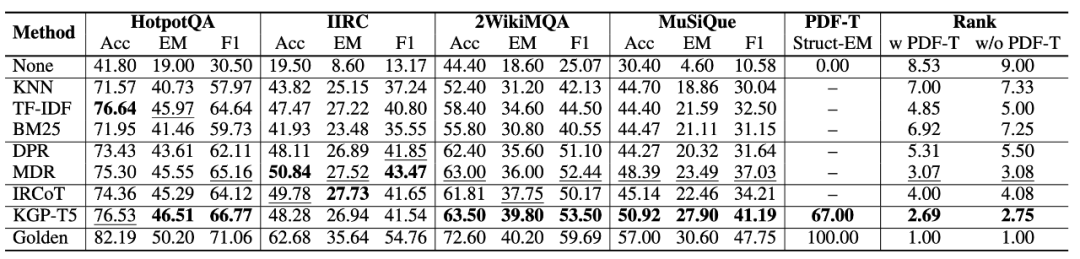
表1 MD-QA性能对比
4.2 构建的 KG 和基于 LLM 的图遍历代理的质量如何影响 MD-QA 性能?
(1)构建的KG的影响
通过改变 TF-IDF/KNN-ST/KNN-MDR/TAGME 的超参数来构建不同密度的 KG,并使用 KGP-T5 研究其对 MD-QA 性能和邻居匹配时间的影响。
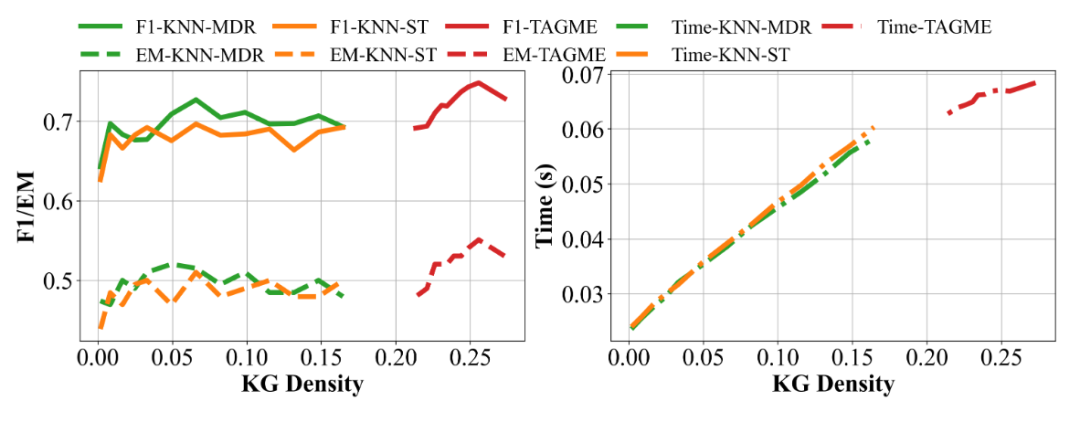
图3 随着 KG 密度的增加,性能/延迟也会增加
如图 3 所示,随着 KG 密度的增加,F1/EM 会增加并保持稳定,而选择下一个要访问的最有希望的邻居的延迟也会增加。当两个构建的 KG 密度相同时,KNN-MDR 的性能比 KNN-ST 更好。与 KNN-MDR/ST 相比,由于 TAGME 生成的 KG 比 KNN-ST/MDR 生成的 KG 更密集,因此 TAGME 性能更优,但代价是延迟增加。
(2)图谱遍历代理的影响
本文研究了使用不同 LLM 代理遍历 TAGME 构建的KG对 MD-QA 的影响。具体来说,在表 2 中比较了通过 ChatGPT、LLaMA、T5 和 MDR 的指导随机或智能地选择下一个要访问的邻居的代理。由于随机代理只是在没有 LLM 指导的情况下盲目地遍历 KG,因此不可避免地会收集到不相关的段落,因此没有 LLM 的指导,它的性能最差,进一步验证了使用 LLM 引导图遍历的必要性。
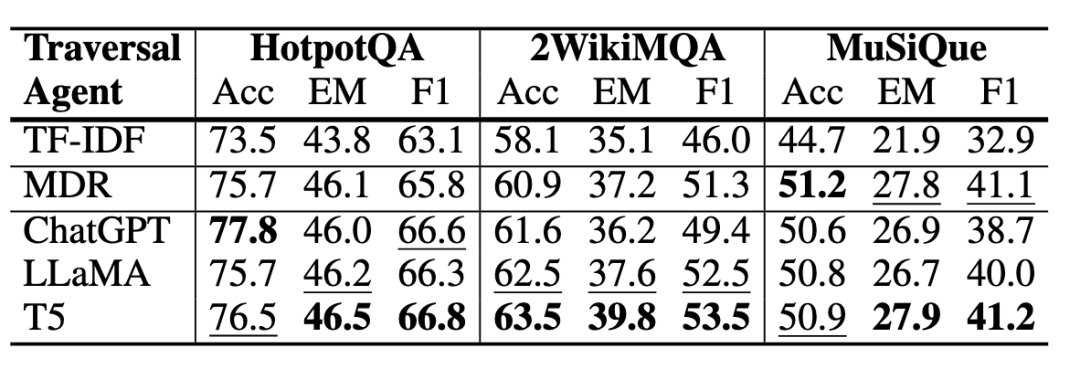
表2 比较基于 LLM 的 KG 遍历代理
(3)敏感性分析
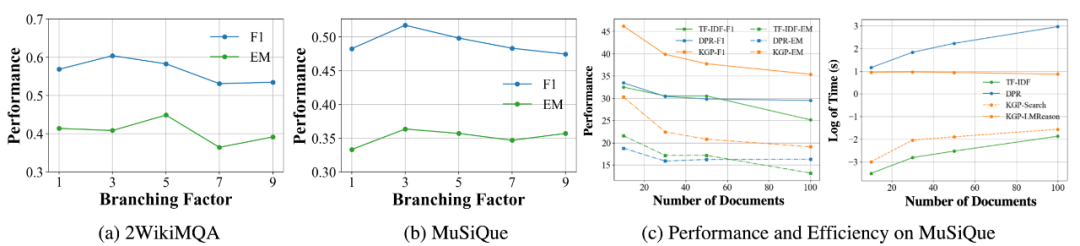
图4 敏感性分析
本文对分支因子(从候选邻居中选择下一步访问的节点数)进行敏感性分析。在图 4(a)-(b)中,随着分支因子的增加,性能首先会提高,因为从候选邻居中选择的通道节点越多,到达最终答案的推理路径就越多。但是,为了确保公平比较,本文固定了上下文预算(即每道题允许检索的段落总数在所有基线中都是相同的),随着分支因子的增加,性能会下降,因为初始播种节点的数量会减少,从而导致 KG 的覆盖率降低。此外,在图 4(c) 中比较了当构建的 KG 包含不同数量的文档时 KGP 的效率。KGP 的性能始终高于其他基线,效率也高于基于嵌入的 DPR。TF-IDF 比 KGP 稍快,因为它是一种纯粹基于启发式的方法。
5. 总结
回答多文档问题需要进行知识推理,并从不同模式的不同文档中进行检索,这给应用“预训练、提示和预测”范式的 LLM 带来了挑战。通过识别段落之间的逻辑关联和文档内部的结构关系,本文提出了一种知识图谱提示方法(KGP),用于在 MD-QA 中辅助 LLM。KGP 从文档中构建知识图谱,节点是句子或文档结构,边是它们的词义/语义相似性/结构关系。由于构建的 KG 可能包含不相关的邻接,因此本文进一步设计了基于 LLM 的图遍历代理,该代理在处理问题时会选择性地访问最有希望的节点。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









