






转载公众号 | 老刘说NLP
本次分享关于GraphRAG的一个有意思的综述,会有收获。供大家一起参考并思考。
一、关于GrpahRAG的一个有意思的综述
图检索增强生成(GraphRAG)的方法、技术和应用综述,《Graph Retrieval-Augmented Generation: A Survey》,https://arxiv.org/abs/2408.08921,这个工作有点意思,系统化地概述了GraphRAG的工作流程,包括基于图的索引(Graph-Based Indexing)、图引导的检索(Graph-Guided Retrieval)和图增强的生成(Graph-Enhanced Generation)。
其中有几张图是可以看看的,一图胜千言。
1、使用大型语言模型(LLMs)、检索增强生成(RAG)和图检索增强生成(GraphRAG)在处理用户查询时的不同方法和效果
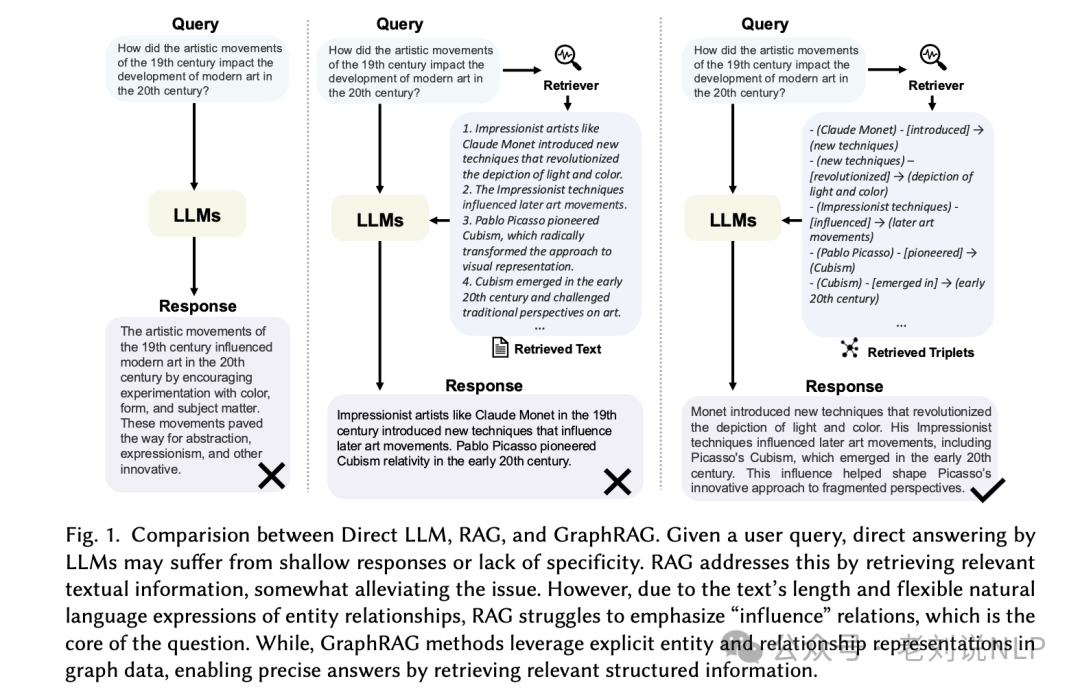
1)直接LLM:当用户提出一个问题时,如果直接使用LLMs进行回答,可能会遇到回答过于肤浅或缺乏特定性的问题。这是因为LLMs依赖于其预训练的知识库,而这个知识库可能不包含最新的信息或特定领域的深入知识。
2)RAG:RAG通过检索相关的文本信息来增强LLMs的回答,从而在一定程度上缓解了直接LLMs的问题。RAG会在生成回答之前,从大型文本语料库中检索与用户查询相关的信息片段,并将这些信息作为上下文提供给LLMs,以便生成更丰富、更准确的回答。
3)GraphRAG:尽管RAG在某些情况下能够改善回答的质量,但由于文本长度和自然语言中实体关系的灵活表达,RAG在强调问题核心的“影响”关系方面存在困难。GraphRAG方法利用图数据中明确的实体和关系表示,通过检索相关的结构化信息,能够提供更精确的答案。GraphRAG通过图数据库检索与查询相关的节点、三元组、路径或子图等图元素,并将这些元素用于生成回答,从而更好地捕捉实体间的复杂关系和上下文信息。
GraphRAG相对于直接LLM和RAG,通过利用图结构化数据,能够更有效地处理复杂的关系和上下文,提供更准确和深入的回答。这种方法特别适合于需要理解和推理实体间复杂关系的场景。
2、图检索增强生成(GraphRAG)框架在问答任务中的概览
在这个框架中,GraphRAG 被分为三个主要阶段:G-Indexing(图基索引)、G-Retrieval(图引导检索)和 G-Generation(图增强生成)。以下是对这三个阶段的详细解读:
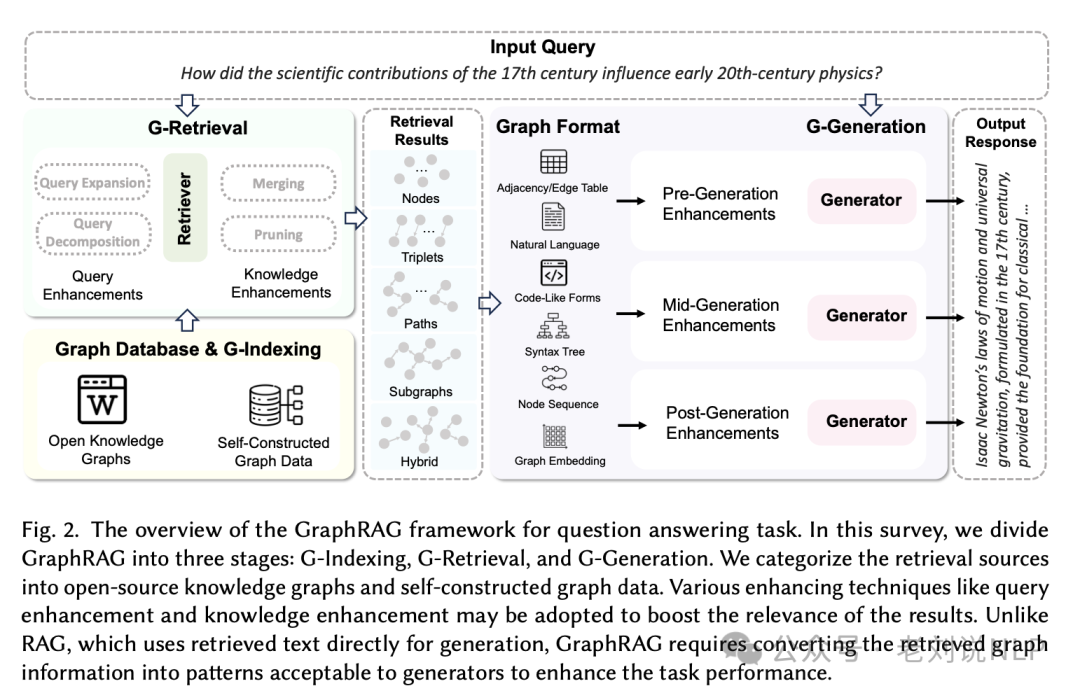
1) G-Indexing(图基索引):
这是 GraphRAG 过程的初始阶段,目的是识别或构建与下游任务对齐的图数据库G,并在此数据库上建立索引。
图数据库可以来源于公开的知识图谱、图数据,或基于专有数据源(如文本或其他形式的数据)构建。
索引过程包括映射节点和边的属性、建立连接节点之间的指针,以及组织数据以支持快速遍历和检索操作。
2) G-Retrieval(图引导检索):
在图基索引之后,图引导检索阶段专注于根据用户查询或输入从图数据库中提取相关信息。
给定一个用自然语言表达的用户查询,检索阶段的目标是从知识图谱中提取最相关的元素(例如实体、三元组、路径、子图)。
3) G-Generation(图增强生成):
图增强生成阶段涉及基于检索到的图数据综合有意义的输出或响应。
这一阶段,一个生成器接收查询、检索到的图元素以及可选的提示作为输入,以生成响应。
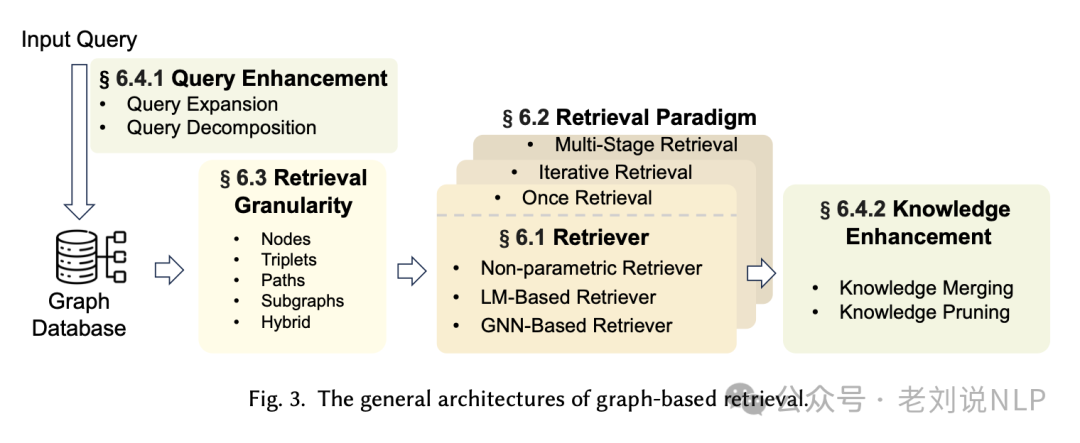
3、基于图的检索(Graph-Based Retrieval)的通用架构
基于图的检索(Graph-Based Retrieval)的通用架构是GraphRAG系统中的一个关键组成部分,它涉及到从图数据库中检索与用户查询最相关的信息。
1) Retriever(检索器):
检索器是负责从图数据库中检索信息的组件。根据其底层模型,检索器可以分为非参数检索器(Non-parametric Retriever)、基于语言模型的检索器(LM-based Retriever)和基于图神经网络的检索器(GNN-based Retriever)。
2) Retrieval Paradigm(检索范式):
检索范式决定了检索过程是如何进行的。包括一次性检索(Once Retrieval)、迭代检索(Iterative Retrieval)和多阶段检索(Multi-Stage Retrieval)。
一次性检索尝试在单个操作中检索所有相关信息。
迭代检索通过多次检索步骤来逐渐缩小和精确化检索结果。
多阶段检索将检索过程分为多个阶段,每个阶段可能使用不同类型的检索器。
3) Retrieval Granularity(检索粒度):
检索粒度决定了从图中检索的信息的详细程度,可以是节点(Nodes)、三元组(Triplets)、路径(Paths)或子图(Subgraphs)。
4) Query Enhancement(查询增强):
查询增强技术用于改善用户查询,使其更加丰富,包括查询扩展(Query Expansion)和查询分解(Query Decomposition)。
5) Knowledge Enhancement(知识增强):
知识增强技术用于改进检索到的知识,包括知识合并(Knowledge Merging)和知识剪枝(Knowledge Pruning)。
6) Graph Database(图数据库):
这是存储图数据的地方,可以是开放的知识图谱或自构建的图数据。
7) Retrieval Results(检索结果):
检索器根据用户查询和图数据库检索出的结果。
8) Output(输出):
最终的检索结果将作为输入提供给生成器(Generator),用于生成最终的响应。
4、图增强生成(Graph-Enhanced Generation,简称 G-Generation)阶段

这是 GraphRAG 框架中的最后一个阶段,负责将检索到的图数据与查询结合起来生成最终的响应。
1) Graph Formats(图格式):
在使用语言模型(LMs)作为生成器时,需要将图数据转换为 LMs 能够理解的格式。这包括图语言(Graph Languages)和图嵌入(Graph Embeddings)两种方式。
2) Generators(生成器):
根据下游任务的类型,选择合适的生成模型。可以是图神经网络(GNNs)、语言模型(LMs)或混合模型(Hybrid Models)。
3) Pre-Generation Enhancement(预生成增强):
在生成阶段之前,对输入数据或表示进行改进,以提高生成质量。这可能包括对检索到的图数据进行语义丰富处理。
4) Mid-Generation Enhancement(生成中增强):
在生成过程中应用的技术,根据中间结果或上下文提示调整生成策略。
5) Post-Generation Enhancement(后生成增强):
生成初始响应后,使用的方法,主要涉及整合多个生成的响应以获得最终响应。
6) Retrieval Results(检索结果):
来自 G-Retrieval 阶段的输出,即从图数据库中检索到的与查询相关的图元素。
7) Response(响应):
最终生成的响应,这是 G-Generation 阶段的输出,也是对用户查询的回答。
8) Hybrid Models(混合模型):
结合了 GNNs 和 LMs 的优势,可以进一步细分为级联范式(Cascaded Paradigm)和并行范式(Parallel Paradigm)。
9) Graph Languages(图语言):
包括邻接/边表(Adjacency/Edge Table)、自然语言(Natural Language)、代码形式(Code-like Forms)、语法树(Syntax Tree)和节点序列(Node Sequence)等,这些都是将图数据转换为文本序列的方法。
10) Graph Embeddings(图嵌入):- 使用 GNNs 将图数据表示为嵌入,以便与文本表示结合在一个统一的语义空间中。
5、将检索到的子图转换为不同的图语言形式,以适应不同生成器的输入格式要求
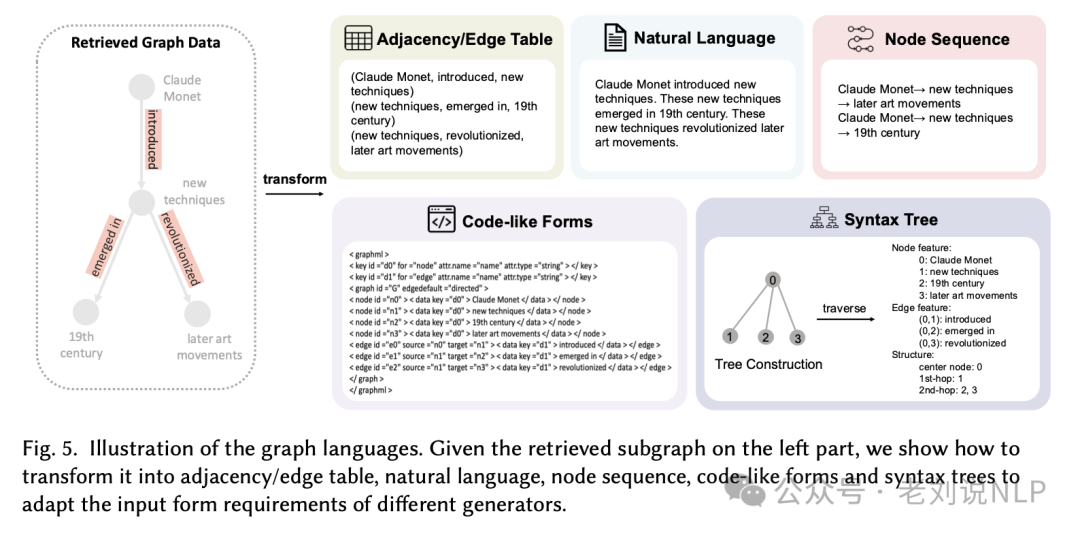
1) 原始子图:
图的左侧展示了一个检索到的子图,包含节点(例如 Claude Monet)和边(表示关系,如 "introduced"、"emerged in"、"revolutionized")。
2) 邻接/边表(Adjacency/Edge Table):
将子图转换为表格形式,列出节点和它们之间的连接关系。邻接表通常用于表示稀疏图中节点的直接邻居,而边表则列出图中所有的边。
3) 自然语言(Natural Language):
将图数据转换为自然语言描述,例如 "Claude Monet introduced new techniques. These new techniques emerged in the 19th century. These new techniques revolutionized later art movements." 这种描述方式便于语言模型理解和生成更自然的语言。
4) 节点序列(Node Sequence):
将子图中的节点按照特定的顺序排列成序列,例如 "Claude Monet → new techniques → 19th century"。这种序列保留了节点间的拓扑关系。
5) 代码形式(Code-like Forms):
使用类似编程语言的标记来表示图结构,例如使用 Graph Modeling Language (GML) 或 Graph Markup Language (GraphML)。这种方式适合于具有编程背景的语言模型。
6) 语法树(Syntax Tree):
将子图转换为类似语法树的结构,这种结构具有层次性,并且能够保持图的拓扑顺序。语法树可以更好地捕捉节点间的关系和图的层次结构。
7) 转换过程(Tree Construction):
展示了如何通过遍历子图来构建语法树,包括选择中心节点、确定一跳和二跳邻居节点,并为每条边分配特征(如 "introduced"、"emerged in"、"revolutionized")。
8) 结构(Structure):
说明了构建的语法树或序列的结构,例如中心节点、一跳和二跳邻居节点的组织方式。
6、 Graph Retrieval-Augmented Generation (GraphRAG) 技术概览
包括它所应用的任务、基准数据集、方法以及评估指标。
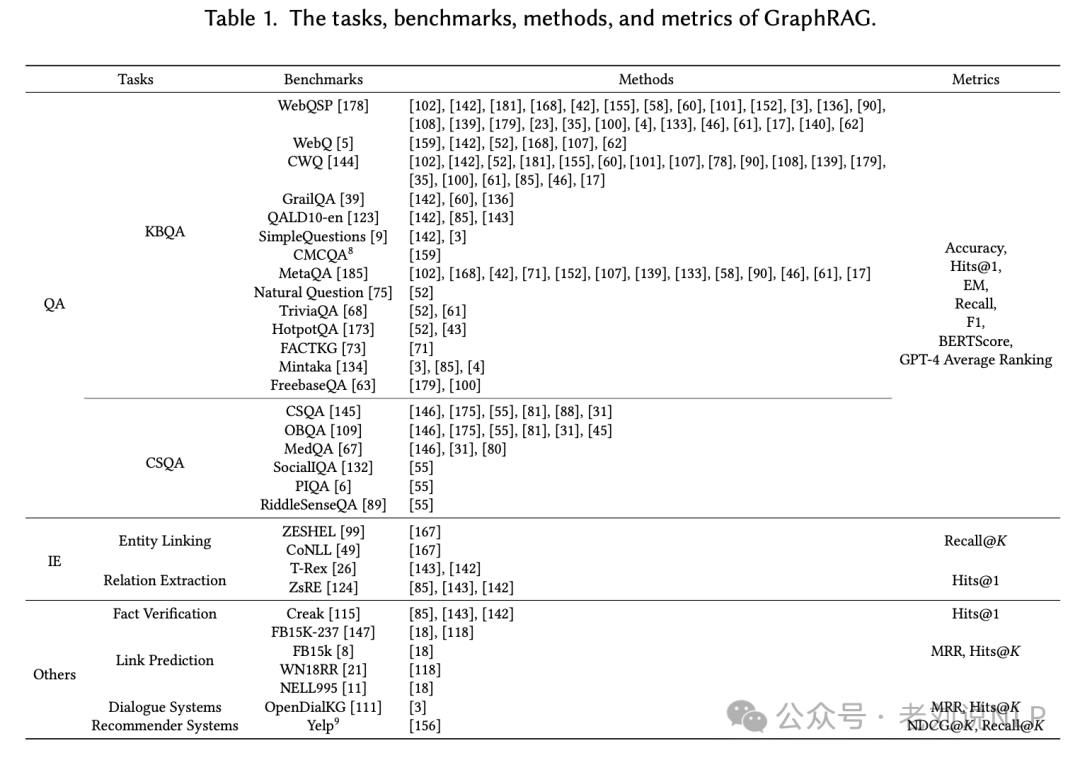
QA (Question Answering): 包括基于知识库的问题回答 (KBQA) 和常识问题回答 (CSQA)。
Information Extraction: 包括实体链接 (Entity Linking) 和关系提取 (Relation Extraction)。
Others: 其他应用,如事实验证 (Fact Verification)、链接预测 (Link Prediction)、对话系统 (Dialogue Systems) 和推荐系统 (Recommender Systems)。
1)基准数据集 (Benchmarks)
用于评估 GraphRAG 系统性能的各种数据集,例如:
WebQSP、WebQ、CWQ、GrailQA、QALD10-en 等用于 KBQA。
CSQA、OBQA、MedQA、SocialIQA、PIQA、RiddleSenseQA 等用于 CSQA。
其他如 T-Rex 用于关系提取,Creak 用于事实验证等。
2)方法 (Methods)
在 GraphRAG 中使用的技术和模型,包括但不限于:
基于 LLMs 的模型,如 GPT-4。
基于图的方法,如 GNN-RAG。
特定的系统实现,如 Microsoft 的 GraphRAG、NebulaGraph 的 GraphRAG 等。
3)评估指标 (Metrics) 评估 GraphRAG 系统性能的指标包括:
准确性 (Accuracy)
精确度 (Precision),常用于检索质量评估
召回率 (Recall)
F1 分数 (F1 Score),常用于平衡精确度和召回率
精确度在 top-k (Hits@1, Hits@k),表示前 k 个检索结果中包含正确答案的比例
编辑距离 (Edit Distance),用于评估生成文本与真实答案之间的差异
BERTScore 和 GPT-4 Average Ranking,用于评估生成文本的质量
总结
本文主要回顾了于GrpahRAG的一个有意思的综述,会有收获。
参考文献
1、https://arxiv.org/abs/2408.08921
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









