






1、情况概述
很多网友朋友们会发现,会声会影在安装好,或者是在更新之后,会有个弹窗,像下图这样:

英文版是未注册提示:
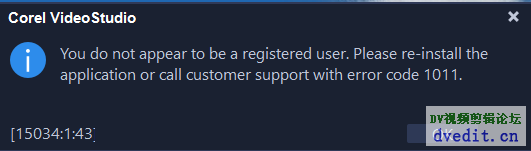
其实这个乱码提示只有简体中文版本上才会是乱码,英文版上显示的是″You do not appear to be a register user. Please re-install the application or call customer support with error 1011″,翻译一下就是:你似乎不是已注册用户,请重装软件或者联系客服。很明显,这个乱码弹窗,实际上是告诉你,你用的是盗版,不准你启动软件。
2、为什么会这样?
这是Corel加强防盗版的一个措施,目的是让大家都从下载器安装会声会影,会声会影主程序会验证你是否打开过下载器,没有用过下载器就会提示乱码,而论坛大部分人用的都是破解版的(替换了dll的离线安装版),所以才会显示盗版乱码提示。
3、如何解决?
其实很简单,只需要大家打开会声会影下载器,一直点击下一步,到达下载界面,参考下面的截图,到了下载界面就可以关闭下载器了。
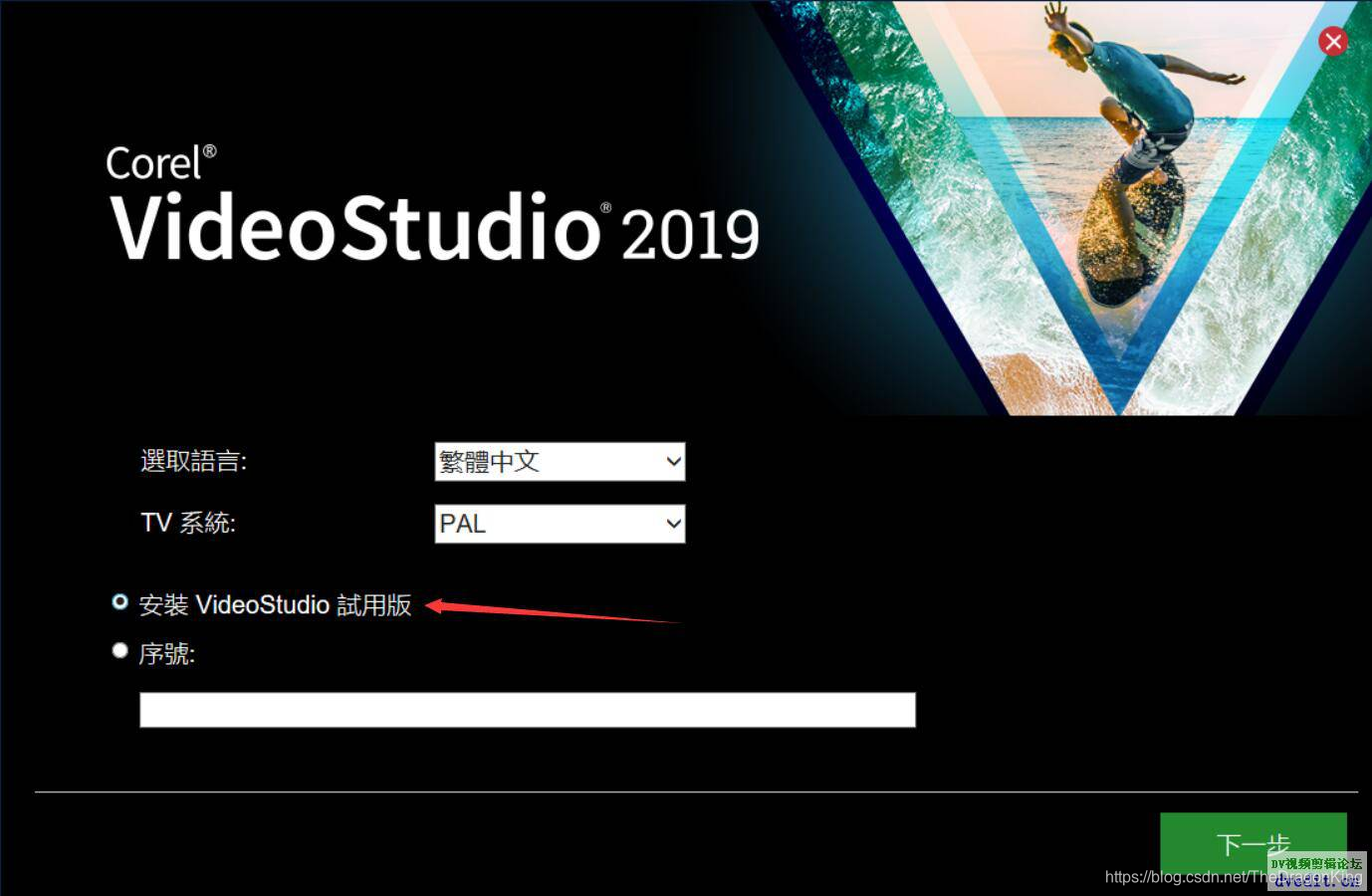
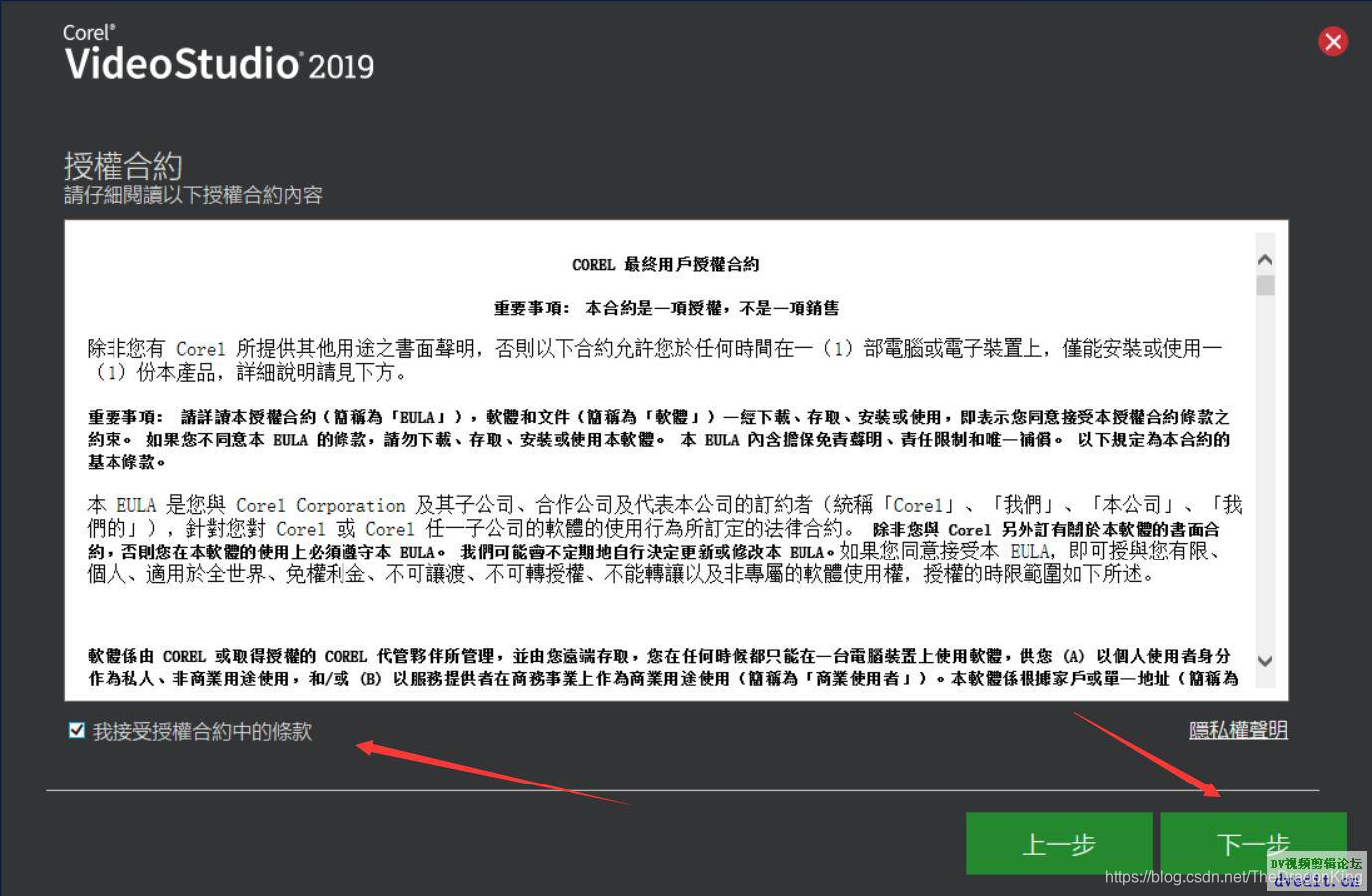
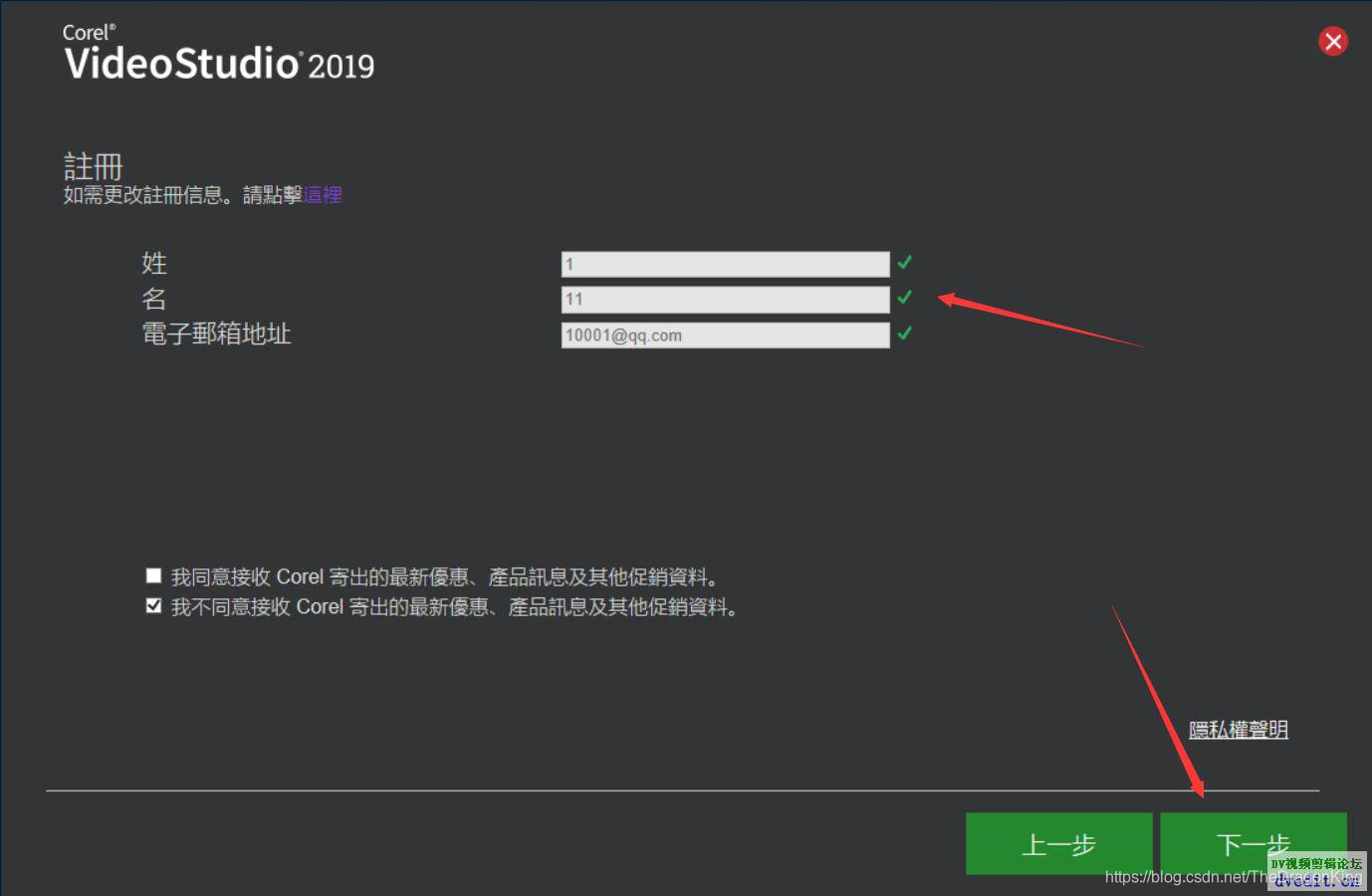
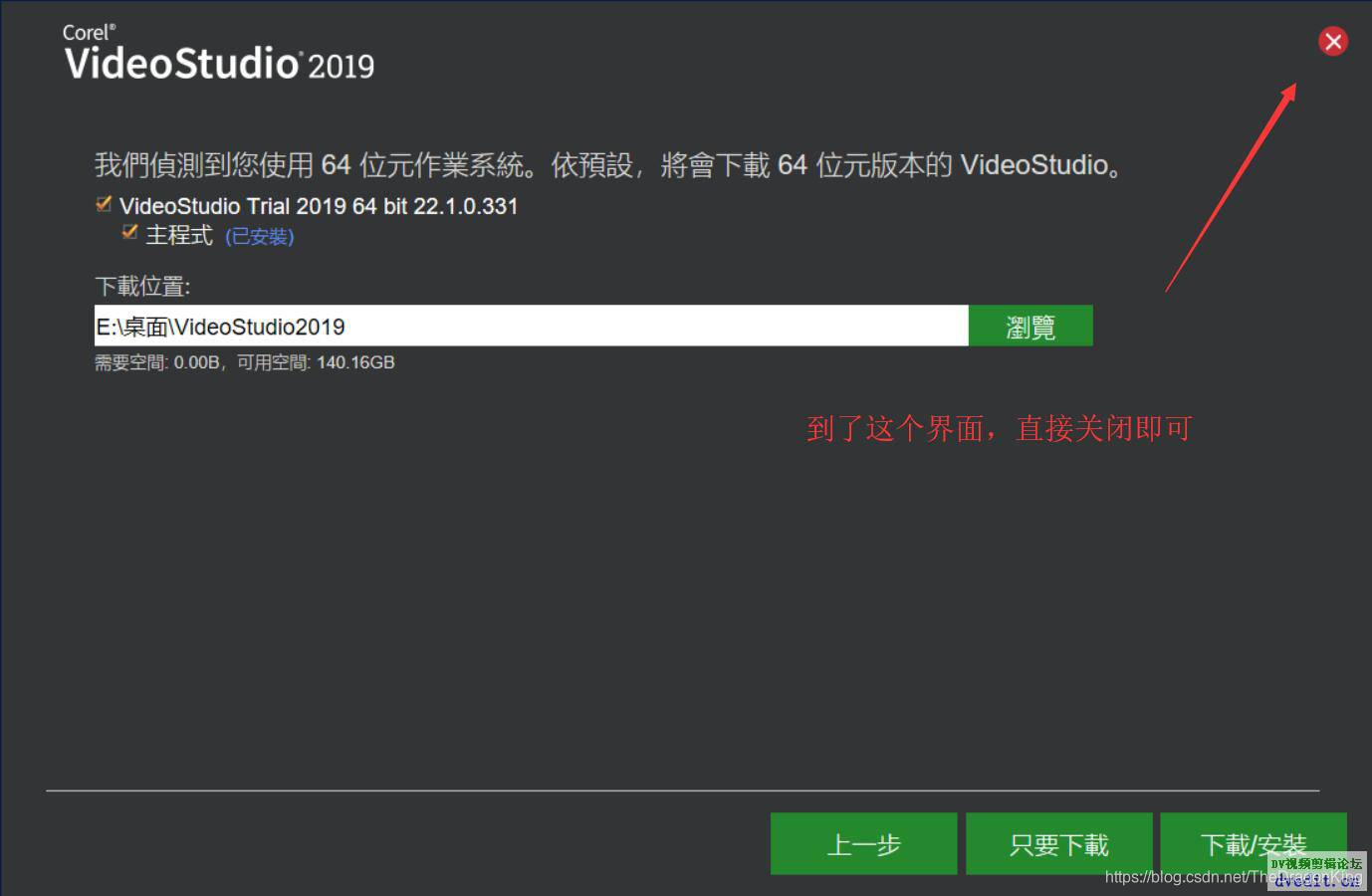
提醒一下:有人说下载器截图2,会卡在那里,动不了,那是因为软件服务器在国外,加载需要时间,请耐心等待,就可以了;有人说下载器截图3输入了邮箱,也无法点击下一步,这是因为你输入的姓名、邮箱格式不符合要求,建议大家写的尽可能“真一点”,国外比较流行谷歌邮箱,因此,姓名可以写马化腾,邮箱写mahuateng@gmail.com,这样下载器才会以为你写的是真的,才让你点击下一步。
4、哪里有下载器?
Corel官网就可以下载到最新的下载器,下面就提供下载器的官网下载地址给大家:会声会影2018下载器,会声会影2019下载器
未来版本的会声会影,比如2020、2021、2022,此方法也应该是适应的,新版本的下载器可以在这个页面找到:https://www.videostudiopro.com/en/pages/download/

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









