






LMDeploy简介
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能1 :
- 高效推理引擎 TurboMind:基于 FasterTransformer,我们实现了高效推理引擎 TurboMind,支持 InternLM、LLaMA、vicuna等模型在 NVIDIA GPU 上的推理。
- 交互推理方式:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。
- 多 GPU 部署和量化:我们提供了全面的模型部署和量化支持,已在不同规模上完成验证。
- persistent batch 推理:进一步优化模型执行效率。
LMDeploy实战体验
官方发布了非常详细的教程,链接如下。
Tutorial/lmdeploy/README.md at camp2 · InternLM/Tutorial · GitHub
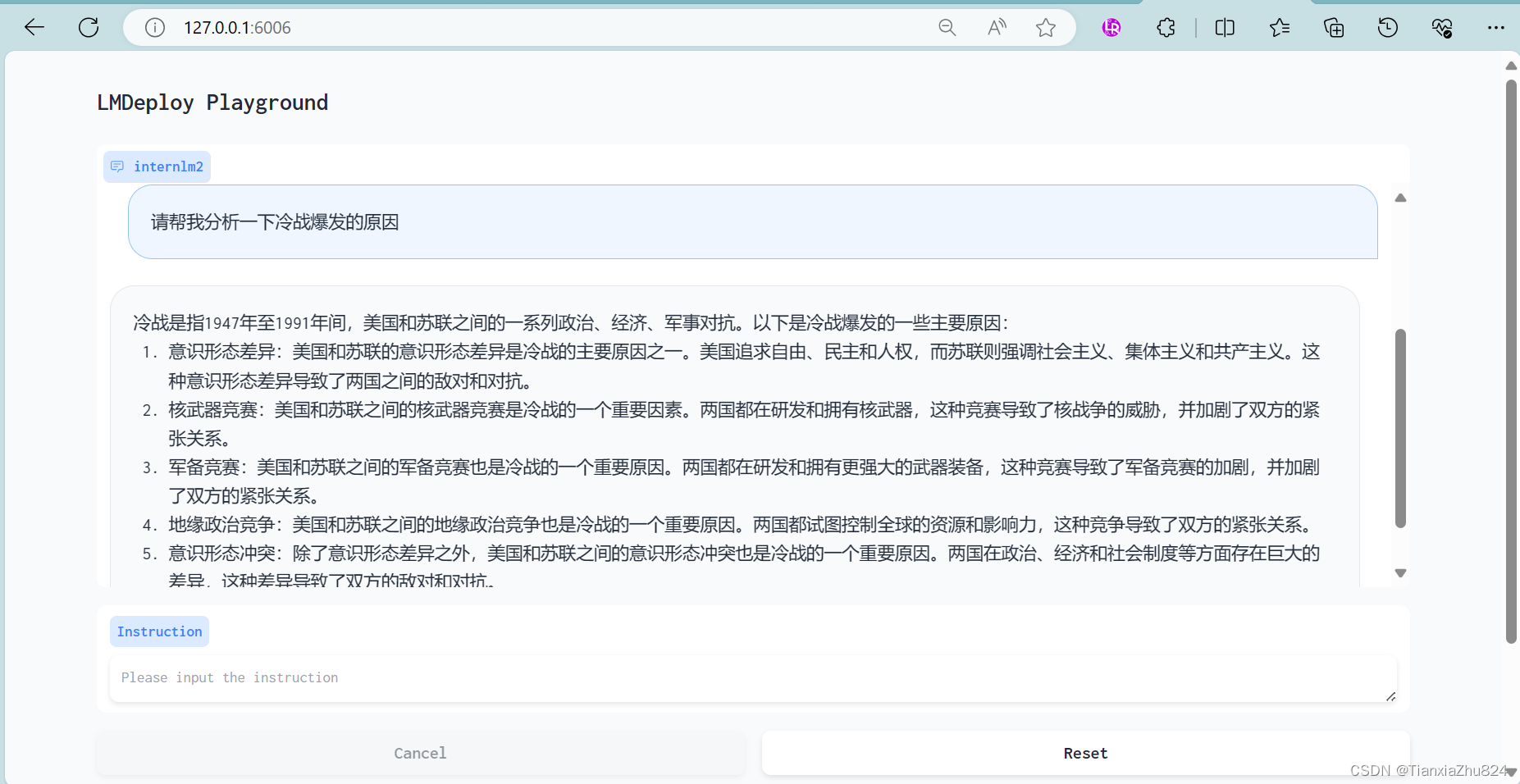
LMDeploy模型对话(chat)
主要包含两个步骤(详细操作可见教程)
- 配置 LMDeploy 运行环境
- 以命令行方式与 InternLM2-Chat-1.8B 模型对话
使用Transformer库运行模型
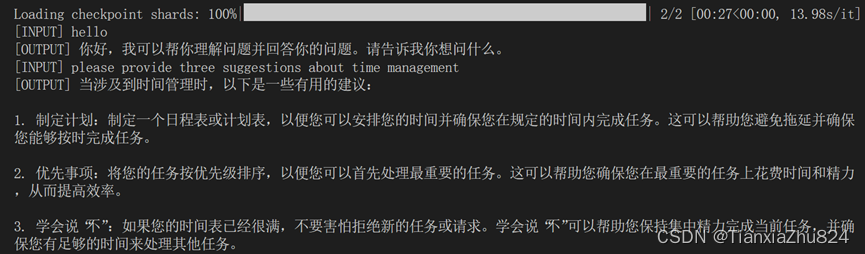
可以感受到其推理速度较慢。
使用LMDeploy与模型对话


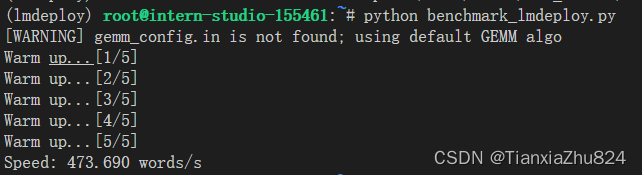
相较于原生Transformer,LMDeploy的推理速度明显加快了。
可以通过编写速度测试脚本来定量比较Transformer库推理Internlm2-chat-1.8b的速度,该部分在教程中有详细介绍。
结果大致如图:

LMDeploy模型量化(lite)
总的来说,量化是一种以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。
设置最大KV Cache缓存大小
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,KV Cache全部存储于显存,以加快访存速度。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
按照教程进行相应的设置,可以看到显存占用明显降低。


使用W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。它支持以下NVIDIA显卡:
- 图灵架构(sm75):20系列、T4
- 安培架构(sm80,sm86):30系列、A10、A16、A30、A100
- Ada Lovelace架构(sm90):40 系列

相应操作后,可以看到,显存占用变为2472MB,明显降低。
LMDeploy服务(serve)
首先按照教程启动API服务器。
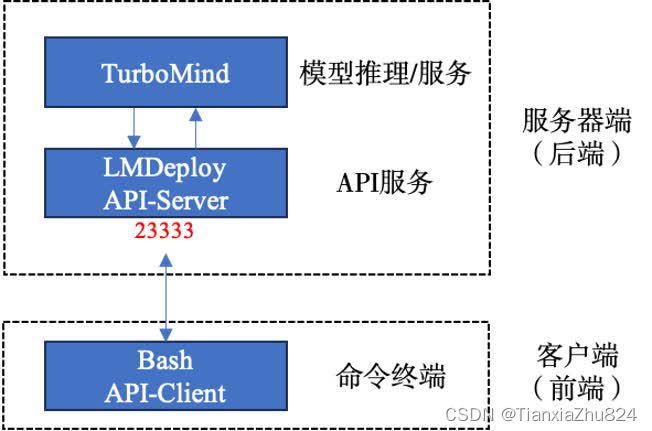
命令行客户端连接API服务器

当前的架构如下:
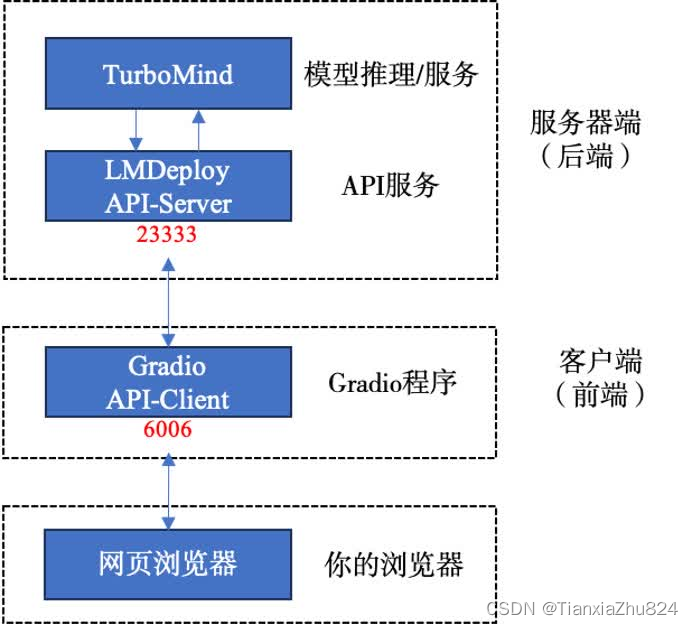
网页客户端连接API服务器
当前的架构如下图所示:
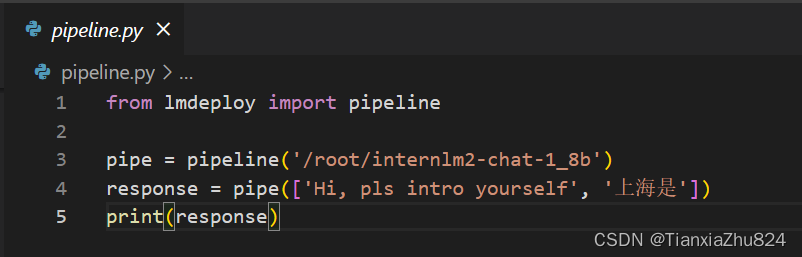
LMdeploy的Python代码集成
上述操作是在命令行中进行的,在开发项目时,有时我们需要将大模型推理集成到Python代码里面。
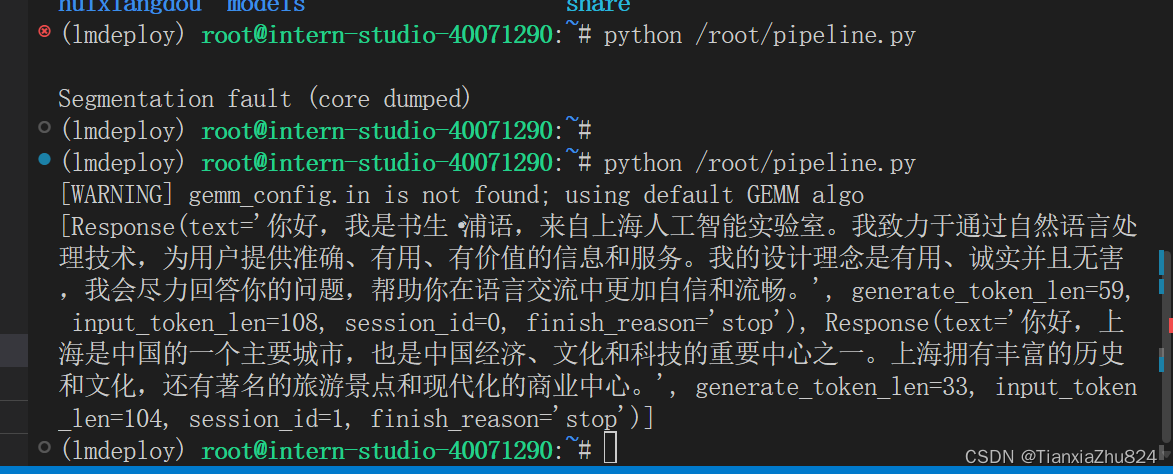
向TurboMind后端传递参数
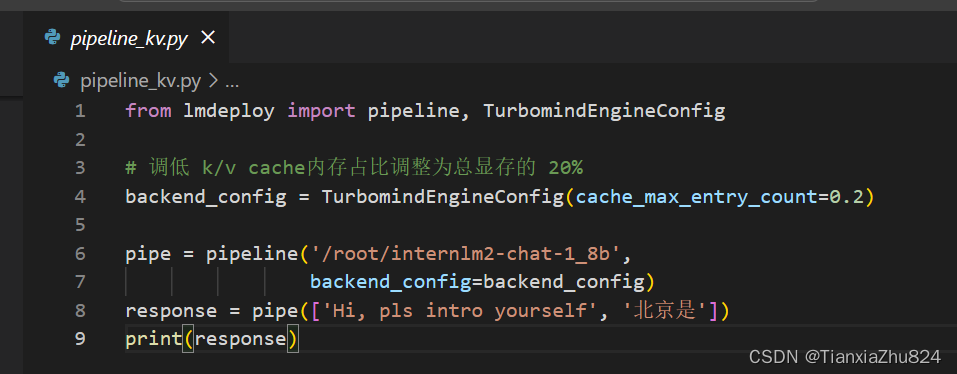
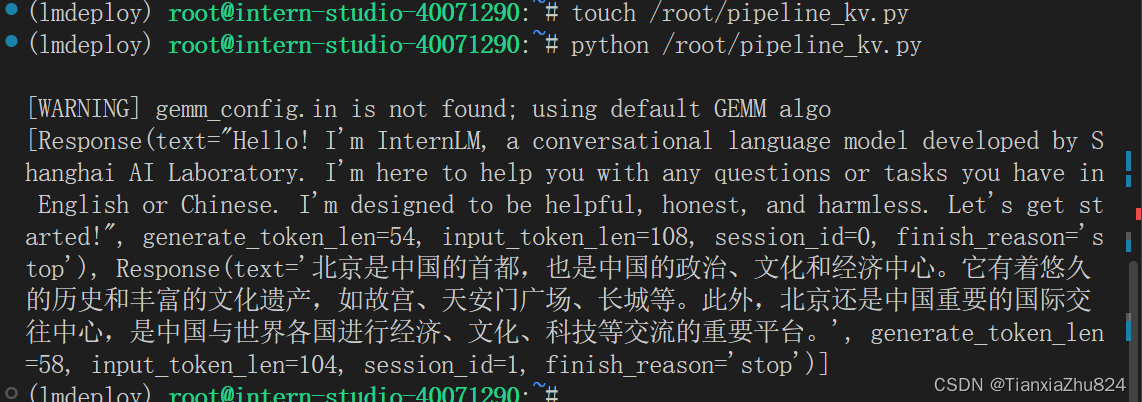
在第3章,我们通过向lmdeploy传递附加参数,实现模型的量化推理,及设置KV Cache最大占用比例。在Python代码中,可以通过创建TurbomindEngineConfig,向lmdeploy传递参数。
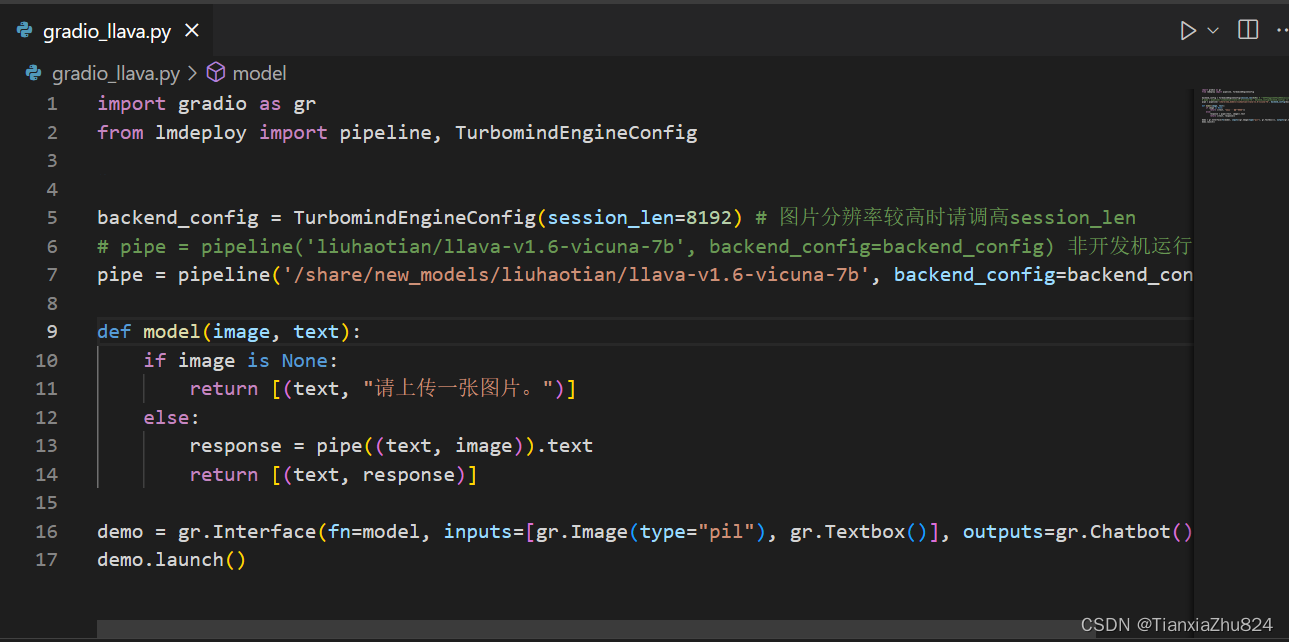
使用LMDeploy运行视觉多模态大模型llava
















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









