







来自:https://blog.csdn.net/sinat_33718563/article/details/78825971
最近在做视频拼接的项目,里面用到了图像的单应性矩阵变换,在最后的图像重映射,由于目标图像的坐标是非整数的,所以需要用到插值的方法,用的就是双线性插值,下面的博文主要是查看了前辈的博客对双线性插值算法原理进行了一个总结,在这里也感谢一些大牛的博文。
http://www.cnblogs.com/linkr/p/3630902.html
http://www.cnblogs.com/funny-world/p/3162003.html
第一部分
双线性插值
假设源图像大小为mxn,目标图像为axb。那么两幅图像的边长比分别为:m/a和n/b。注意,通常这个比例不是整数,编程存储的时候要用浮点型。目标图像的第(i,j)个像素点(i行j列)可以通过边长比对应回源图像。其对应坐标为(i*m/a,j*n/b)。显然,这个对应坐标一般来说不是整数,而非整数的坐标是无法在图像这种离散数据上使用的。双线性插值通过寻找距离这个对应坐标最近的四个像素点,来计算该点的值(灰度值或者RGB值)。
若图像为灰度图像,那么(i,j)点的灰度值的数学计算模型是:
f(x,y)=b1+b2x+b3y+b4xy
其中b1,b2,b3,b4是相关的系数。关于其的计算过程如下如下:
如图,已知Q12,Q22,Q11,Q21,但是要插值的点为P点,这就要用双线性插值了,首先在x轴方向上,对R1和R2两个点进行插值,这个很简单,然后根据R1和R2对P点进行插值,这就是所谓的双线性插值。
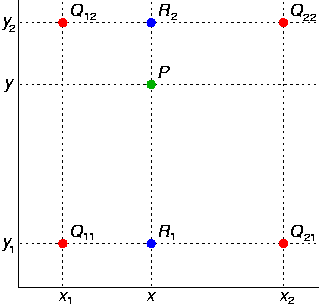
附:维基百科--双线性插值:
双线性插值,又称为双线性内插。在数学上,双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。
假如我们想得到未知函数  在点
在点 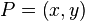 的值,假设我们已知函数 在
的值,假设我们已知函数 在  ,
,  ,
,  , 及
, 及  四个点的值。
四个点的值。
首先在 x 方向进行线性插值,得到

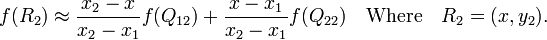
然后在 y 方向进行线性插值,得到
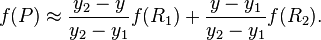
这样就得到所要的结果  ,
,
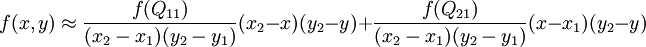

如果选择一个坐标系统使得 的四个已知点坐标分别为 (0, 0)、(0, 1)、(1, 0) 和 (1, 1),那么插值公式就可以化简为
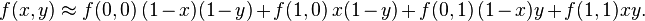
或者用矩阵运算表示为

这种插值方法的结果通常不是线性的,线性插值的结果与插值的顺序无关。首先进行 y 方向的插值,然后进行 x 方向的插值,所得到的结果是一样的。
第二部分
opencv和Matlab中的双线性插值
这部分的前提是,你已经明白什么是双线性插值并且在给定源图像和目标图像尺寸的情况下,可以用笔计算出目标图像某个像素点的值。当然,最好的情况是你已经用某种语言实现了网上一大堆博客上原创或转载的双线性插值算法,然后发现计算出来的结果和matlab、openCV对应的resize()函数得到的结果完全不一样。
那这个究竟是怎么回事呢?
其实答案很简单,就是坐标系的选择问题,或者说源图像和目标图像之间的对应问题。
按照网上一些博客上写的,源图像和目标图像的原点(0,0)均选择左上角,然后根据插值公式计算目标图像每点像素,假设你需要将一幅5x5的图像缩小成3x3,那么源图像和目标图像各个像素之间的对应关系如下:

只画了一行,用做示意,从图中可以很明显的看到,如果选择右上角为原点(0,0),那么最右边和最下边的像素实际上并没有参与计算,而且目标图像的每个像素点计算出的灰度值也相对于源图像偏左偏上。
那么,让坐标加1或者选择右下角为原点怎么样呢?很不幸,还是一样的效果,不过这次得到的图像将偏右偏下。
最好的方法就是,两个图像的几何中心重合,并且目标图像的每个像素之间都是等间隔的,并且都和两边有一定的边距,这也是matlab和openCV的做法。如下图:

如果你不懂我上面说的什么,没关系,只要在计算对应坐标的时候改为以下公式即可,
int x=(i+0.5)*m/a-0.5
int y=(j+0.5)*n/b-0.5
代替
int x=i*m/a
int y=j*n/b
利用上述公式,将得到正确的双线性插值结果
第三部分 图像处理界双线性插值算法的优化
在图像处理中,双线性插值算法的使用频率相当高,比如在图像的缩放中,在所有的扭曲算法中,都可以利用该算法改进处理的视觉效果。首先,我们看看该算法的简介。
在数学上,双线性插值算法可以看成是两个变量间的线性插值的延伸。执行该过程的关键思路是先在一个方向上执行线性插值,然后再在另外一个方向上插值。下图示意出这个过程的大概意思。

用一个简单的数学表达式可以表示如下:
f(x,y)=f(0,0)(1-x)(1-y)+f(1,0)x(1-y)+f(0,1)(1-x)y+f(1,1)xy
合并有关项,可写为: f(x,y)=(f(0,0)(1-x)+f(1,0)x) (1-y)+(f(0,1)(1-x)+f(1,1)x)y
由上式可以看出,这个过程存在着大量的浮点数运算,对于图像这样大的计算用户来说,是一个较为耗时的过程。
考虑到图像的特殊性,他的像素值的计算结果需要落在0到255之间,最多只有256种结果,由上式可以看出,一般情况下,计算出的f(x,y)是个浮点数,我们还需要对该浮点数进行取整。因此,我们可以考虑将该过程中的所有类似于1-x、1-y的变量放大合适的倍数,得到对应的整数,最后再除以一个合适的整数作为插值的结果。
如何取这个合适的放大倍数呢,要从三个方面考虑,第一:精度问题,如果这个数取得过小,那么经过计算后可能会导致结果出现较大的误差。第二,这个数不能太大,太大会导致计算过程超过长整形所能表达的范围。第三:速度考虑。假如放大倍数取为12,那么算式在最后的结果中应该需要除以12*12=144,但是如果取为16,则最后的除数为16*16=256,这个数字好,我们可以用右移来实现,而右移要比普通的整除快多了。
综合考虑上述三条,我们选择2048这个数比较合适。
下面我们假定某个算法得到了我们要取样的坐标分别PosX以及PosY,其中PosX=25.489,PosY=58.698。则这个过程的类似代码片段如下:
NewX = Int(PosX) '向下取整,NewX=25
NewY = Int(PosY) '向下取整,NewY=58
PartX = (PosX - NewX) * 2048 '对应表达式中的X
PartY = (PosY - NewY) * 2048 '对应表达式中的Y
InvX = 2048 - PartX '对应表达式中的1-X
InvY = 2048 - PartY '对应表达式中的1-Y
Index1 = SamStride * NewY + NewX * 3 '计算取样点左上角邻近的那个像素点的内存地址
Index2 = Index1 + SamStride '左下角像素点地址
ImageData(Speed + 2) = ((Sample(Index1 + 2) * InvX + Sample(Index1 + 5) * PartX) * InvY + (Sample(Index2 + 2) * InvX +
Sample(Index2 + 5) * PartX) * PartY) \ 4194304 '处理红色分量
ImageData(Speed + 1) = ((Sample(Index1 + 1) * InvX + Sample(Index1 + 4) * PartX) * InvY + (Sample(Index2 + 1) * InvX +
Sample(Index2 + 4) * PartX) * PartY) \ 4194304 '处理绿色分量
ImageData(Speed) = ((Sample(Index1) * InvX + Sample(Index1 + 3) * PartX) * InvY + (Sample(Index2) * InvX +
Sample(Index2 + 3) * PartX) * PartY) \ 4194304 '处理蓝色分量
以上代码中涉及到的变量都为整型(PosX及PosY当然为浮点型)。
代码中Sample数组保存了从中取样的图像数据,SamStride为该图像的扫描行大小。
观察上述代码,除了有2句涉及到了浮点计算,其他都是整数之间的运算。
在Basic语言中,编译时如果勾选所有的高级优化,则\ 4194304会被编译为>>22,即右移22位,如果使用的是C语言,则直接写为>>22。
需要注意的是,在进行这代代码前,需要保证PosX以及PosY在合理的范围内,即不能超出取样图像的宽度和高度范围。
通过这样的改进,速度较直接用浮点类型快至少100%以上,而处理后的效果基本没有什么区别。















 2680
2680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









