






首先看看这个模型里面的第一部分:self-attention
通俗翻译就是“自注意力”。
这个部分的模型原理其实也正应了英文名字的意思。
咱们以文本问题为例子。
例如下面两句稍有差异的句子:
1.The animal didn't cross the street, because it was too tired.
2.The animal didn't cross the street, because it was too narrow.
现在要问,两句话中,it指得是那个对象呢?animal还是street?显然,第一句的it指得是animal,第二句指得是street。
那么问题来了,如何让机器知道句子里面的it指得是哪个对象呢?
显然,句子里面的各个单词都是是有互相联系的,甚至和标点符号都有联系,不同的词语之间,关系紧密度大小不同。表面上看,句子是由一个个单独的单词组合而成,但实际上,一句话里面,每个都蕴含了一句话的整体信息,就是部分包含整体的意思。
知道了这里,作者就想,既然句子里面的各个单词之间有相互的关系,那肯定存在某种数值关系去表示各个单词之间的紧密程度,“世界是由数组成的嘛-----毕达哥拉斯语录”。要不咱就透视一下,对句子做某种变换(量子力学里面经常有的操作,目的就是将某一过程或者对象放在不同表象里面去看,类似于不同角度的感觉),让句子里面的每一个单词的都能够发生数字关系,而且科学家相信,存在这样的特定具体的变换,能够确切地表示出句子中各个单词之间的关系。只是我们是要机器自己去学习出这种数值关系而已。所谓的学习嘛,你们懂的,还用老套路-梯度下降法嘛,自动求最佳提特征的参数。具体的参数形式(形状)后面再提。
时间有限,我快速给出图来表达这种意思。

图1 每个词与其他词(包括与这个单词自己)的互相关系紧密度数学表达
每个词表达成各个词的线性组合,这是可能的吧?没有证明这一定不可以,对吧,万一今后试验成功了呢?人工智能很大程度不就是试出来的嘛。。。
每个词前面的系数就代表了关系紧密程度。
好了,这些系数:0.02、0.6、0.01、0.1···都是怎么求得的呢?作者构造了一种方法来求这些系数:
设想存在某个参数张量(简单理解为参数矩阵)Wq,又设想存在某个参数张量Wk,以及Wv。我们总能对某个单词(设为X)提取特征(做变换)对吧。好嘞,如下:
Wq*X= q
Wk*X= k
Wv*X= v
先别管为啥要整出三种参数张量,后面你会看到发明这个的那帮人怎么用他们玩游戏的。。。
X在这里被科学家们对应指定成了一些向量,我们叫做词向量。这没什么不可以的,只要你愿意,你自己都一个制作出一套标准对象,只要让这些对象(哪怕是密码什么的)和词语是唯一对应就行了。
好了,单词都被整成了向量了,我们当然可以用参数张量去提特征了。也就是可以进行运算了嘛!计算机除了计算啥都也不会了嘛。。(一切皆是数---毕达哥斯拉语录,毕哥简直就是计算机的源头呀)
到这里,下面看看作者是怎么玩这个游戏的。
用Wq左乘X得出另外一个张量q:Wq*X = q
用Wk左乘X得出另外一个张量k: Wk*X = k
用Wv左乘X得出另外一个张量v: Wv*X = v
于是我们就多出了三个可以玩的棋子:q 、k 、v
前面说了,咱们目的是要对一句话里面的这些个单词进行“透视”一下嘛,看看这些个单词背后究竟是个啥样。我们说两个人之间是亲兄弟,长的很想,那人家还猜的到他们关系紧密,要是长得不太一样的俩兄弟呢,谁表面看得出来?这时候是要看啥最准?看基因对吧,这个东西可看不见摸不着,这两人做个基因检测(被透视一下),看看隐藏在他们里面的基因信息,组合组合,核对核对,就能判断了。对吧。这里的W就是起到了类似透视的作用。
总得来说作者把词语都先透视一遍,得到了隐藏着更深信息的q 、k 、v,所以关系看得准不准,关键看隐藏在背后的东西。
好,下面就用单词的这些背后的东西来看看单词之间的关系。。怎么验证他们的关系?“滴血验亲!!”哈哈,开玩笑,不是我的错,后面实在是太像了。拿你们的血出来接触接触就知道了(古装电视剧神法)。。。相似相溶原理(高中化学都扯出来了)。。。
对X1单词来说有q1、k1、v1,对X2单词来说有q2、k2、v2。。。。。以此类推
先上图,更好理解。我最喜欢图了,对于人类来说,图就是效率!
为了简化说明,这里只举两个单词的句例。

图2 词的权重系数求法
图2假设了一句话就只有这两个单词,照前面的思想,那我们可以写成:X1 = 0.88*X1 + 0.12*X2 这种表达式子。这里的 0.88和0.12怎么来的呢?假如q1*k1 = 112; q1*k2 = 96 ,dk是词向量的长度,例如64,那么如下可以如下求得0.88和0.12:
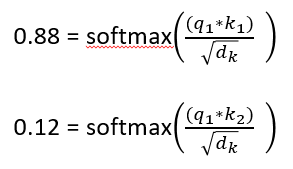
有的人说:这个softmax好像有点熟但又陌生。。。。那快快复习一下吧,动动手自己计算一下记忆更加深刻。
简要说就一句话,用我的q(q1)和我自的k(k1)可以求出我自己和自己的关系,用我的q(q1)和你的k(k2)可以求出我和你的关系。为啥要除以一个 ?为的是排除词向量的长度对关系的影响。总不能两个长得越高的人,亲密度就越好吧!那还了得。。
X2要表示成X1和X2的线性叠加关系,遵照同样方法计算。
像这样的每个词表达成所有词的线性叠加关系以及权重系数的求法,就是self-attention了---自注意力机制!
未完。。。。。。待续。。。。。。。。。。。还没讲完整个transformer哦。。














 1586
1586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









