










背景:
学习transformer模型,计算multiHead attention的时候,权重矩阵Wq,Wk,Wv给我造成了很大的困扰:

1,为啥要需要W*?
2,这个W*是从哪里来的?
结论:
搜索了各种信息,消化理解如下:
1,W*权重矩阵就是训练的目的,就是要找到合适的W*(weights)。
2,W* 是函数nn.Linear初始化的,默认为随机数。经过不断地训练,更新,最终获得比较好的结果
举例:300G的权重weights文件
还记得马斯克的Grok-1吗?那个权重weights文件300G。

完整计算Multi-Head attention图示
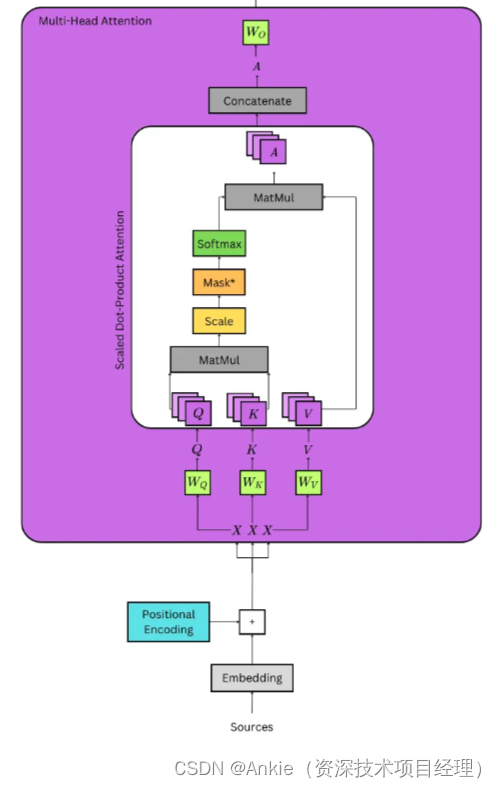
训练W*过程举例:
在PyTorch中,训练一个包含nn.Linear层的神经网络涉及几个关键步骤。以下是一个基本的训练流程:
1. 定义模型结构
首先,你需要定义你的神经网络模型,这包括使用nn.Linear来创建全连接层。
import torch | |
import torch.nn as nn | |
class MyModel(nn.Module): | |
def __init__(self, input_size, hidden_size, output_size): | |
super(MyModel, self).__init__() | |
self.fc1 = nn.Linear(input_size, hidden_size) # 第一个全连接层 | |
self.relu = nn.ReLU() # 激活函数 | |
self.fc2 = nn.Linear(hidden_size, output_size) # 第二个全连接层(输出层) | |
def forward(self, x): | |
x = self.fc1(x) | |
x = self.relu(x) | |
x = self.fc2(x) | |
return x | |
# 实例化模型 | |
input_size = 784 # 假设输入是28x28的图像,展平后为784维 | |
hidden_size = 128 # 隐藏层的大小 | |
output_size = 10 # 假设有10个分类 | |
model = MyModel(input_size, hidden_size, output_size) |
2. 定义损失函数和优化器
接下来,你需要选择一个合适的损失函数和优化器。损失函数用于衡量模型预测与真实标签之间的差异,而优化器则用于根据损失函数的梯度更新模型的权重。
criterion = nn.CrossEntropyLoss() # 多分类问题常用的损失函数 | |
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,学习率设为0.001 |
3. 准备数据集
你需要准备训练数据集和验证数据集(如果有的话)。这些数据集应该被转换为PyTorch张量,并且通常会被划分为小批量以便进行迭代训练。
# 假设你已经有了训练数据和标签 | |
train_data = ... | |
train_labels = ... | |
# 转换为张量 | |
train_data = torch.tensor(train_data, dtype=torch.float32) | |
train_labels = torch.tensor(train_labels, dtype=torch.long) |
4. 训练循环
现在你可以开始训练循环了。在每个epoch中,你会遍历整个数据集(或其一个子集),进行前向传播、计算损失、反向传播和参数更新。
num_epochs = 10 # 训练轮数 | |
for epoch in range(num_epochs): | |
# 将梯度清零,否则梯度会累积 | |
optimizer.zero_grad() | |
# 前向传播 | |
outputs = model(train_data) | |
# 计算损失 | |
loss = criterion(outputs, train_labels) | |
# 反向传播 | |
loss.backward() | |
# 更新参数 | |
optimizer.step() | |
# 打印统计信息(可选) | |
if (epoch+1) % 10 == 0: | |
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}') |
5. 验证和测试
在训练过程中或训练结束后,你可能还希望验证模型的性能。这通常通过在验证集或测试集上运行模型并计算相关指标(如准确率)来完成。
# 假设你也有一个验证集 | |
val_data = ... | |
val_labels = ... | |
# 转换为张量 | |
val_data = torch.tensor(val_data, dtype=torch.float32) | |
val_labels = torch.tensor(val_labels, dtype=torch.long) | |
# 不需要计算梯度 | |
with torch.no_grad(): | |
val_outputs = model(val_data) | |
val_loss = criterion(val_outputs, val_labels) | |
_, predicted = torch.max(val_outputs, 1) | |
correct = (predicted == val_labels).sum().item() | |
accuracy = correct / val_labels.size(0) | |
print(f'Validation Loss: {val_loss.item():.4f}, Accuracy: {accuracy:.4f}') |
这就是训练包含nn.Linear层的神经网络的基本流程。在实际应用中,你可能还需要添加其他组件,如数据加载器、学习率调度器、模型保存


















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











