






在前面的一篇文章中实测体验了讯飞开放平台发布的V2.0版本大模型的能力,感兴趣的话可以自行移步阅读即可:
这里一并发布的还有API接口,如下所示:

点击【API测试申请】即可自动跳转至新建工单页面,如下所示:
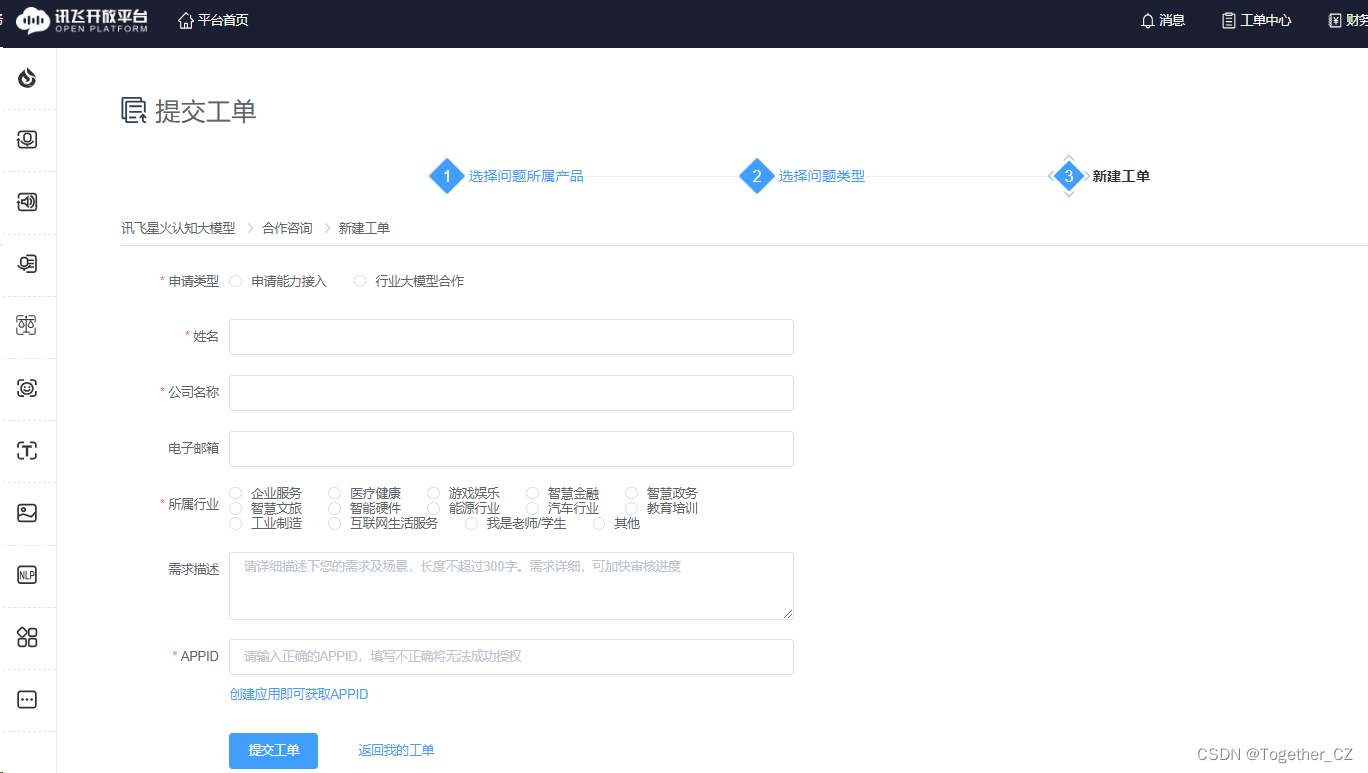
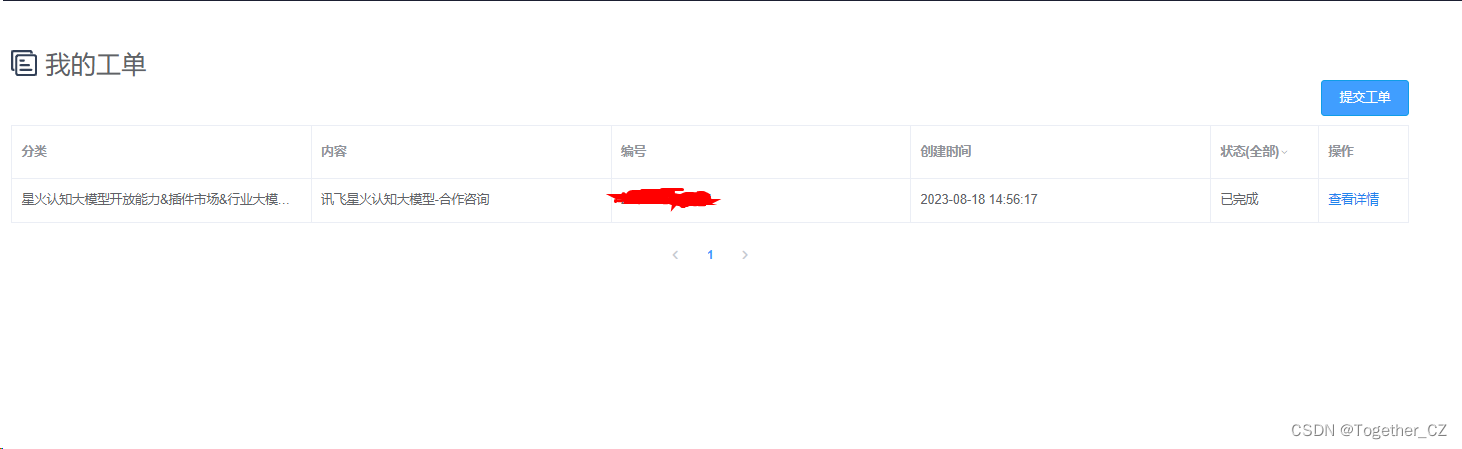
填写自己的对应信息即可提交工单,等待平台审核通过。
APPID的获取方法在这里。安装提示进行操作创建1个应用即可。如下所示:
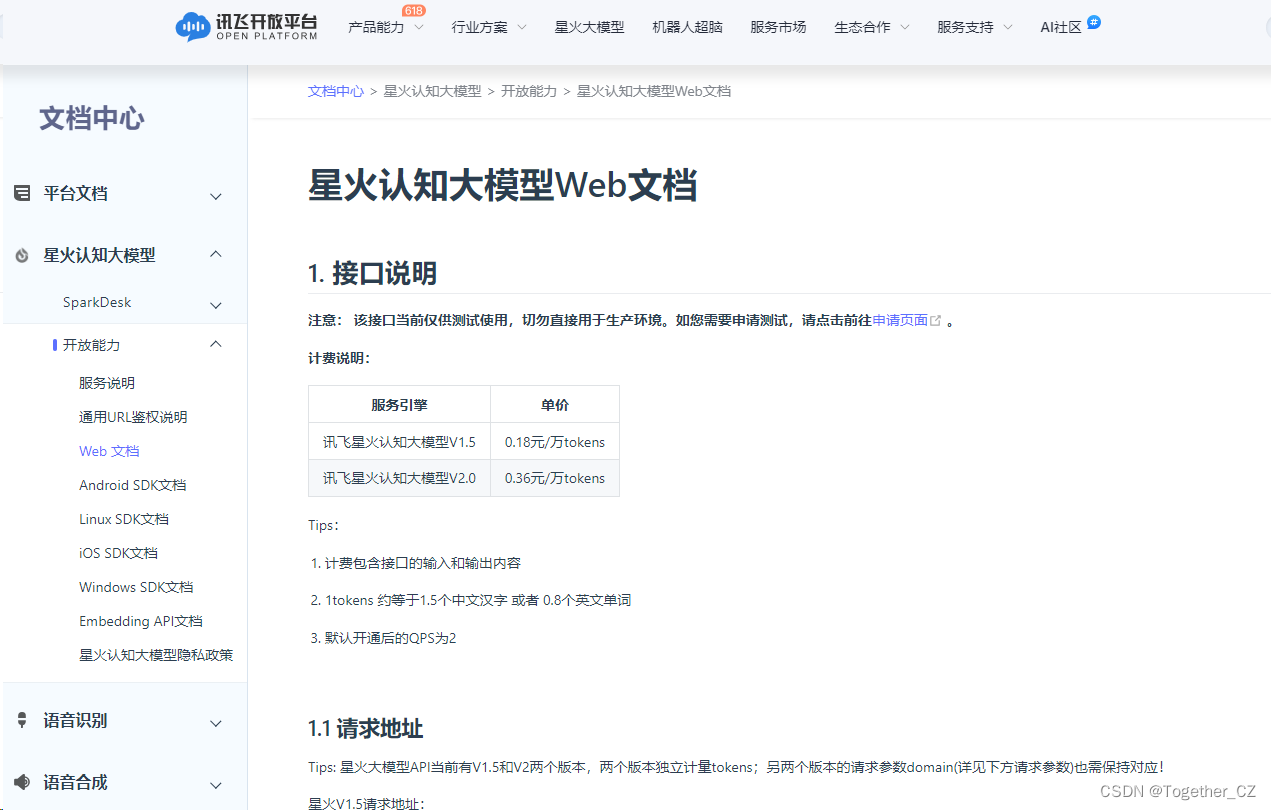
接下来就可以通过编写程序来调用接口进行大模型能力的调用了。这里程序其实也是不需要自己去重头开发的,官方的实例里面还是比较详细的。 文档地址在这里,如下所示:
请求参数构造实例如下所示:
# 参数构造示例如下
{
"header": {
"app_id": "12345",
"uid": "12345"
},
"parameter": {
"chat": {
"domain": "general",
"temperature": 0.5,
"max_tokens": 1024,
}
},
"payload": {
"message": {
# 如果想获取结合上下文的回答,需要开发者每次将历史问答信息一起传给服务端,如下示例
# 注意:text里面的所有content内容加一起的tokens需要控制在8192以内,开发者如有较长对话需求,需要适当裁剪历史信息
"text": [
{"role": "user", "content": "你是谁"} # 用户的历史问题
{"role": "assistant", "content": "....."} # AI的历史回答结果
# ....... 省略的历史对话
{"role": "user", "content": "你会做什么"} # 最新的一条问题,如无需上下文,可只传最新一条问题
]
}
}
}接口请求字段由三个部分组成:header,parameter, payload。 字段解释如下
header部分
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| app_id | string | 是 | 应用appid,从开放平台控制台创建的应用中获取 | |
| uid | string | 否 | 最大长度32 | 每个用户的id,用于区分不同用户 |
parameter.chat部分
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| domain | string | 是 | 取值为[general,generalv2] | 指定访问的领域,general指向V1.5版本 generalv2指向V2版本。注意:不同的取值对应的url也不一样! |
| temperature | float | 否 | 取值为[0,1],默认为0.5 | 核采样阈值。用于决定结果随机性,取值越高随机性越强即相同的问题得到的不同答案的可能性越高 |
| max_tokens | int | 否 | 取值为[1,4096],默认为2048 | 模型回答的tokens的最大长度 |
| top_k | int | 否 | 取值为[1,6],默认为4 | 从k个候选中随机选择⼀个(⾮等概率) |
| chat_id | string | 否 | 需要保障用户下的唯一性 | 用于关联用户会话 |
payload.message.text部分
注:text下所有content累计内容 tokens需要控制在8192内
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| role | string | 是 | 取值为[user,assistant] | user表示是用户的问题,assistant表示AI的回复 |
| content | string | 是 | 所有content的累计tokens需控制8192以内 | 用户和AI的对话内容 |
接口响应实例如下所示:
# 接口为流式返回,此示例为最后一次返回结果,开发者需要将接口多次返回的结果进行拼接展示
{
"header":{
"code":0,
"message":"Success",
"sid":"cht000cb087@dx18793cd421fb894542",
"status":2
},
"payload":{
"choices":{
"status":2,
"seq":0,
"text":[
{
"content":"我可以帮助你的吗?",
"role":"assistant",
"index":0
}
]
},
"usage":{
"text":{
"question_tokens":4,
"prompt_tokens":5,
"completion_tokens":9,
"total_tokens":14
}
}
}
}接口返回字段分为两个部分,header,payload。字段解释如下
header部分
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| code | int | 错误码,0表示正常,非0表示出错;详细释义可在接口说明文档最后的错误码说明了解 |
| message | string | 会话是否成功的描述信息 |
| sid | string | 会话的唯一id,用于讯飞技术人员查询服务端会话日志使用,出现调用错误时建议留存该字段 |
| status | int | 会话状态,取值为[0,1,2];0代表首次结果;1代表中间结果;2代表最后一个结果 |
payload.choices部分
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| status | int | 文本响应状态,取值为[0,1,2]; 0代表首个文本结果;1代表中间文本结果;2代表最后一个文本结果 |
| seq | int | 返回的数据序号,取值为[0,9999999] |
| content | string | AI的回答内容 |
| role | string | 角色标识,固定为assistant,标识角色为AI |
| index | int | 结果序号,取值为[0,10]; 当前为保留字段,开发者可忽略 |
payload.usage部分(在最后一次结果返回)
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| question_tokens | int | 保留字段,可忽略 |
| prompt_tokens | int | 包含历史问题的总tokens大小 |
| completion_tokens | int | 回答的tokens大小 |
| total_tokens | int | prompt_tokens和completion_tokens的和,也是本次交互计费的tokens大小 |
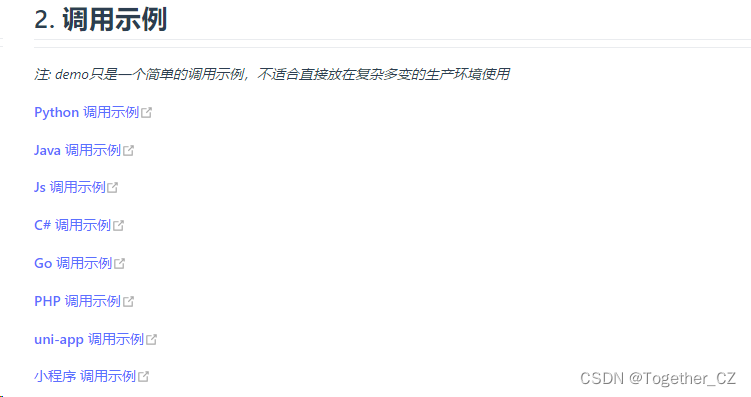
这里官方给出来很多语言版本的调用实例方便大家直接上手使用,不需要完全从零开始开发,可能需要根据自己的实际业务场景进行调整接口。
我这里选择的是Python版本的调用程序。
SparkApi.py模块是核心调用请求实现模块
test.py模块主要需要自己填写对应的APPID、API_SECRET和API_KEY三个字段,即可直接启动。
我在本地做了简单的测试如下所示:
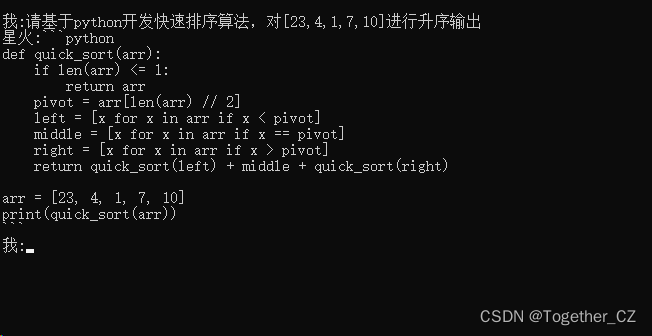




最后还是老样子,问一下这个数学问题,感觉模型回答得依旧是不行的,我还特意在问题最后写了一句提醒的话【要考虑实际情况】,结果模型回答还是不尽人意。
不过这些不是开发者一时半会能去改善的,这里主要的目的是为了基于API接口请求来走通大模型调用的流程,为后面可能使用到的场景做一点铺垫,感兴趣的话都可以自行尝试一下!



















 3592
3592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











