



这篇文章介绍了一种名为VCoder的多功能视觉编码器,旨在提升多模态大语言模型(MLLM)在物体感知任务中的表现。主要内容包括:
-
问题背景:现有的MLLM在复杂的视觉-语言任务(如视觉问答、图像生成)中表现出色,但在简单的物体感知任务(如计数和识别物体)中表现不佳,尤其是在复杂场景中。
-
解决方案:提出了VCoder,通过引入额外的感知模态(如分割图和深度图)作为控制输入,增强MLLM的物体感知能力。VCoder将这些感知模态的信息投影到LLM的嵌入空间中,帮助模型更好地理解图像中的物体。
-
数据集:创建了**COCO Segmentation Text (COST)**数据集,用于训练和评估MLLM在物体识别、计数和顺序预测任务中的表现。该数据集基于COCO图像和现成的分割模型输出生成。
-
评估指标:引入了计数分数(CS)、幻觉分数(HS)和深度分数(DS),用于量化MLLM在物体感知任务中的表现。
-
实验结果:实验表明,VCoder在物体感知任务中显著优于现有的MLLM(包括GPT-4V),尤其是在物体计数和识别方面。
-
未来工作:文章还讨论了当前方法的局限性,如对分割图质量的依赖和同义词映射的手动定义,并提出了未来改进的方向。
VCoder通过引入额外的感知模态和新的数据集,显著提升了MLLM在物体感知任务中的表现,为未来的多模态研究提供了新的思路。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
摘要
人类拥有非凡的视觉感知能力,能够看到并理解所见之物,帮助他们理解视觉世界并进行推理。近年来,多模态大语言模型(MLLM)在视觉问答、图像描述、视觉推理和图像生成等视觉-语言任务中取得了令人印象深刻的性能。然而,当要求识别或计数(感知)给定图像中的实体时,现有的MLLM系统却表现不佳。为了开发一个能够准确感知和推理的MLLM系统,我们提出了使用多功能视觉编码器(VCoder)作为MLLM的感知“眼睛”。我们为VCoder提供分割图或深度图等感知模态,以提高MLLM的感知能力。其次,我们利用COCO数据集中的图像和现成的视觉感知模型的输出来创建COCO分割文本(COST)数据集,用于训练和评估MLLM在物体感知任务中的表现。第三,我们引入了评估MLLM在COST数据集上物体感知能力的指标。最后,我们提供了大量实验证据,证明VCoder在物体级感知能力上优于现有的多模态大语言模型,包括GPT-4V。我们开源了数据集、代码和模型,以促进相关研究。

1 引言
“感知是土壤,推理是种子。没有肥沃的土壤,种子无法茁壮成长。” —— GPT-4 [51], 2023
思考和推理的能力是人类日常功能中最显著的特征之一。通常,理解环境是思考和推理的前提[30]。随着类似ChatGPT的指令跟随AI代理在语言理解和推理方面的成功[3, 11, 50, 51, 64],研究人员利用大语言模型(LLM)开发了能够理解视觉和语言输入的指令框架[14, 42, 72, 78],以模仿人类的感知和推理能力。我们将这类系统称为多模态大语言模型(MLLM)。尽管MLLM在复杂的视觉-语言任务(如图像描述[2, 4, 41]、图像生成[27, 29, 61]、视觉推理和定位[23, 54, 76])中表现出色,但在简单的任务(如计数物体)中表现却不尽如人意(图1)。如图2所示,当要求识别视觉输入中的实体时,MLLM输出了错误的物体计数(如“人”、“椅子”),并幻觉出某些物体的存在(如“手提包”、“沙发”)。感知性能在复杂场景中表现更差。
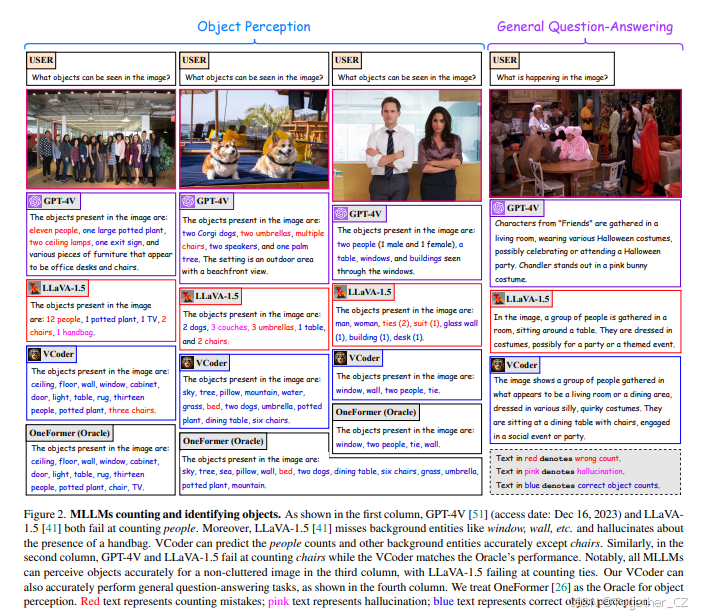
图2. MLLM在计数和识别物体中的表现。如第一列所示,GPT-4V [51](访问日期:2023年12月16日)和LLaVA-1.5 [41]在计数人数时都失败了。此外,LLaVA-1.5 [41]漏掉了背景实体(如窗户、墙壁等),并幻觉出一个手提包的存在。VCoder能够准确预测人数和其他背景实体,除了椅子。同样,在第二列中,GPT-4V和LLaVA-1.5在计数椅子时失败,而VCoder的表现与Oracle一致。值得注意的是,在第三列中,所有MLLM在非杂乱图像中都能准确感知物体,但LLaVA-1.5在计数领带时失败。我们的VCoder还能准确执行一般的问答任务,如第四列所示。我们将OneFormer [26]视为物体感知的Oracle。红色文本表示计数错误;粉色文本表示幻觉;蓝色文本表示正确的物体感知。
2 相关工作
视觉感知
视觉感知的基本性质使其成为MLLM系统中的关键组成部分。感知任务可以分为密集预测任务(如图像分割[25, 26, 44, 66]和深度估计[16, 18, 57])和稀疏预测任务(如物体检测[6, 67]和姿态估计[13, 62])。在深度学习时代,最初的方法使用基于CNN的方法[8, 9, 22, 31, 32, 58, 62]来处理感知任务,而最近的方法则转向使用基于视觉Transformer的架构[10, 18, 26, 57, 69, 79]。在本工作中,我们主要关注物体级感知任务,特别是预测图像中物体的名称、数量和顺序。
使用LLM进行视觉理解
使用LLM进行视觉应用并不是一个新概念。简而言之,开发多模态大语言模型涉及将视觉编码器[15, 56]的特征投影到语言模型(LLM)的嵌入空间[11, 63, 64],并在视觉-语言对话数据集上进行指令微调。
LLaVA [42]提出了一个将现有图像-文本数据转换为对话格式的流程,并在其收集的数据集上对CLIP [55]和LLaMA [63]模型进行端到端的微调,展示了视觉-语言指令微调的最早证据。与LLaVA同时,MiniGPT-4 [78]使用了BLIP2 [36]的视觉编码器,并使用线性层将视觉特征投影到Vicuna [11]的特征空间中。InstructBLIP [14]开源了包含16个不同数据集的集合,涵盖了视觉问答、推理、描述、分类等多种视觉任务,并在其数据集上对BLIP2模型进行了微调。mPLUG-Owl [72]提出了使用视觉抽象器并对视觉编码器进行微调。最近,LLaVA-1.5 [41]提出了使用MLP作为投影器,并在学术指令数据集上进行微调,以在各种基准测试中实现最先进的性能[12, 17, 24, 37]。在各种开源MLLM中[5, 23, 33, 34, 73],我们选择了LLaVA-1.5作为基线,因为其性能优越。
MLLM中的感知幻觉
自从LLM引入以来,NLP社区对其幻觉能力进行了广泛研究[75]。然而,多模态大语言模型中的幻觉现象受到的关注相对较少。LRV-Instruction [40]引入了一个包含40万条视觉指令的新指令微调数据集,以防止MLLM中的幻觉,并将GPT-4 [51]的响应作为真实值来衡量性能。最近,HallusionBench [39]基于逻辑一致性和推理,定量评估了MLLM中导致幻觉的各种失败模式。与这些主要针对视觉问答任务进行基准测试的工作不同,本文主要关注MLLM中的物体级幻觉。
与我们的目标最接近的两项工作是POPE [37]和CHAIR [59]。一方面,POPE [37]尝试通过基于图像中物体存在与否的“是”-“否”回答策略来衡量MLLM中的幻觉。另一方面,CHAIR [59]专注于基于图像描述中的词语(而非计数)来衡量幻觉。在我们的工作中,我们不仅考虑物体词语,还考虑相应的计数来计算物体级计数分数和幻觉分数。
3 使用MLLM进行物体识别
假设你被邀请参加一个万圣节派对,并想为派对上的每个人带糖果。你让朋友发一张派对房间的照片(图1),以便你估计人数和需要购买的糖果数量。匆忙中,你问GPT-4V [51]:“你能数一下照片中有多少人吗?”,它回答:“是的,照片中有十个人。”。你兴奋地带着十颗糖果到达派对,却发现有十四个人!你困惑地看着朋友发来的照片,发现照片中确实有十四个人,意识到GPT-4V在计数这个简单任务上失败了,尽管它能够准确描述照片中的万圣节派对场景(图1)。我们将多模态大语言模型在简单视觉感知任务上失败而在复杂视觉推理任务上成功的现象称为感知中的莫拉维克悖论[47]。

我们假设上述现象的主要原因之一是MLLM的指令微调数据中缺乏涵盖物体识别的对话,特别是背景中的物体。为了解决这个问题,我们使用COCO [38]图像和图像分割模型[26]的输出创建句子,准备COCO分割文本(COST)数据集,用于训练和评估MLLM在物体感知任务中的表现。此外,我们还引入了分割图作为MLLM的控制图像输入,以提高性能,并使用计数分数(CS)和幻觉分数(HS)量化物体感知性能。
3.1 使用COST数据集进行物体识别
我们发现图像分割方法[10, 26]能够准确识别场景中的显著物体(如“人”、“车”等前景物体)和背景物体(如“天空”、“墙壁”等)。基于这一发现,我们使用COCO [38]数据集中的图像,并通过OneFormer [26](一种最先进的图像分割模型)获得相应的分割输出。接下来,我们从分割输出中提取物体(类别)名称和数量,并将其转换为句子形式作为真实答案:“图像中的物体有:[CNT₁] [OBJ₁], [CNT₂] [OBJ₂], ..., [CNT_N] [OBJ_N]。”,其中[OBJ_i]表示第i个物体的名称,[CNT_i]表示第i个物体的数量(如果大于1)。我们使用GPT-4 [51]收集了三个不同物体识别任务(语义、实例和全景)的问题集,分别对应三种不同的图像分割任务。最后,如图3所示,我们将COCO图像、OneFormer的分割图、GPT-4生成的问题以及包含物体信息的句子组织成问答格式,构建了我们的**COCO分割文本(COST)**数据集,用于训练和评估MLLM在物体识别任务中的表现。
从统计上看,我们使用GPT-4 [51]为每个问题桶(全景、语义和实例)生成了20个问题。我们总共使用了COCO [38]数据集中train2017、test2017和unlabeled2017分区的28万张图像以及OneFormer [26]的相应分割输出来构建COST训练数据集的视觉部分。同样,我们使用COCO数据集中val2017分区的5000张图像准备了COST验证集。
需要注意的是,类似的方法可以扩展COST数据集以支持其他感知模态。在本工作中,我们将深度图模态纳入COST数据集,用于物体顺序感知任务。具体来说,我们利用公开的DINOv2 [52] DPT [57]模型获取COCO图像的深度图,并使用OneFormer [26]的全景掩码来估计图像中物体的深度顺序。我们将获得的物体顺序格式化为文本,模板为:“图像中物体的深度顺序为:[OBJ₁], [OBJ₂], ..., [OBJ_J]。”,其中[OBJ_j]表示第j个物体的名称。为了保持同一类别物体之间的相对顺序,我们在第二个及以后的物体名称后附加一个计数编号,如图3右下角的“person”和“person-2”所示。与之前的设置类似,我们使用GPT-4 [51]为物体顺序感知任务生成了20个问题。我们在附录中提供了获取真实物体顺序的详细流程。
3.2 用于多模态大语言模型的VCoder
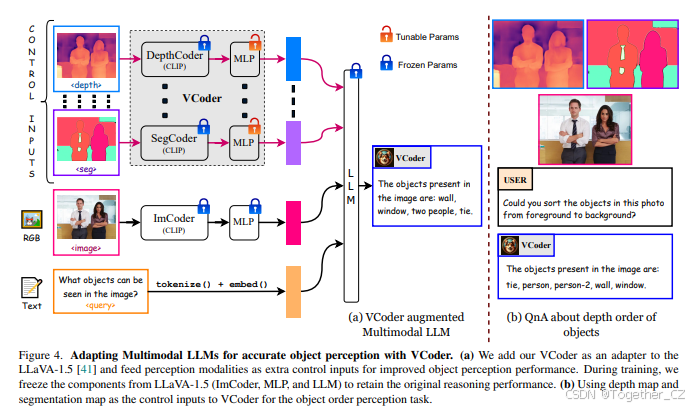
我们注意到,现有的开源多模态大语言模型通常在指令微调期间使用CLIP [56]中的ViT [15]作为图像编码器(ImCoder)。我们认为,ViT主要关注显著物体,因为它是根据描述性文本进行训练的,而这些文本通常忽略了背景区域的信息。我们认为,识别背景中的物体对于MLLM在感知任务中表现出色至关重要。为了克服这一限制,我们引入了分割图作为控制输入[48, 74]到我们的多模态大语言模型中。具体来说,我们使用OneFormer [26]的分割图,并通过预训练的ViT [15](来自CLIP [56])作为SegCoder和一个两层MLP [41]将其投影到LLM的嵌入空间中,我们将这两者统称为我们的多功能编码器(VCoder)。这种来自分割图的额外控制显著提高了物体识别任务的性能。
如图3(a)所示,我们的VCoder适配的MLLM接收三组输入:作为控制输入到VCoder的感知模态、输入到图像编码器(和MLP)的RGB图像以及用户的问题。RGB图像和文本分别被标记为<img>和<query> token。VCoder能够灵活处理各种感知模态,并为每种模态使用特殊token。例如,分割图和深度图输入分别被标记为<seg>和<depth> token。类似地,可以引入更多模态并使用特定模态的token。最后,所有标记化的嵌入被连接并输入到LLM中以获得最终答案。在物体识别任务中,我们仅使用<seg>输入。
我们将VCoder视为一个适配器,添加到我们的基础MLLM(LLaVA-1.5 [41])中,以获得最终的MLLM实验框架。需要注意的是,我们仅在COST数据集上训练VCoder中的MLP组件。我们决定在训练期间冻结所有其他参数,以保持推理能力不受影响,同时提高物体感知性能。
3.3 评估MLLM的物体识别能力
尽管有多种指标[37, 45, 59]可用于衡量视觉-语言模型中的物体幻觉现象,但现有的指标在计算幻觉分数时并未考虑显式的物体计数。我们认为,MLLM返回的物体计数是评估物体识别性能时不可忽视的关键组成部分。因此,我们提出了使用两个指标来评估MLLM的物体识别性能:计数分数(CS)和幻觉分数(HS)。
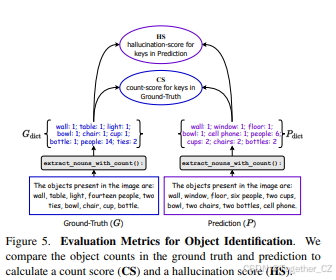

计数分数(CS):它表示MLLM预测的物体计数与真实句子相比的正确百分比。CS越高,性能越好。
幻觉分数(HS):它表示MLLM预测的额外物体计数在真实句子中不存在的百分比。HS越低,性能越好。
需要注意的是,由于我们评估的一对一词匹配性质,我们手动定义了COCO [38]类别及其同义词[46, 59]之间的映射。例如,在评估之前,我们将MLLM响应中的“man”、“woman”、“child”、“kid”、“boy”、“girl”等词语替换为“person”。
4 实验
我们使用LLaVA-1.5 [41]作为基础MLLM。LLaVA-1.5使用CLIP-ViT-L-336px [56]作为图像编码器(ImCoder),并使用两层MLP作为投影器,Vicuna-1.5 [77]作为LLM。在我们的VCoder中,我们还使用CLIP-ViT-L-336px对控制输入进行编码,并使用特定模态的两层MLP将特征投影到LLM的嵌入空间中。我们将视觉输入调整为336×336分辨率(对应576个token)以适应我们的MLLM。在训练过程中,我们加载LLaVA-1.5的指令微调权重并保持其冻结,仅微调VCoder中的MLP组件。我们使用公开的OneFormer [26]模型(基于DiNAT-L [19, 20]骨干网络)在COCO [38]数据集上训练以获得分割图。为了获得深度图,我们使用公开的ViT-L/14蒸馏变体DINOv2 [52] DPT [57]在NYUd [49]数据集上训练。在本节中,我们讨论了物体识别任务的结果。有关物体顺序感知任务的结果,请参见第5节。
实现细节
训练细节:我们在COST训练数据集上对VCoder适配的LLaVA-1.5框架进行了两个epoch的训练,批量大小为256,学习率为1e-3。对于其他训练超参数,我们遵循LLaVA-1.5 [41]在指令微调阶段使用的设置。根据[26],我们在训练期间均匀采样每个物体识别任务(语义、实例和全景)。我们还使用OneFormer [26]的相应分割图作为VCoder的输入进行训练和推理。在8个A100 GPU上,使用LLaVA-1.5的7b和13b变体作为基础MLLM训练VCoder分别需要8小时和14小时。
评估细节:我们在COST验证集上评估所有MLLM。我们分别评估语义、实例和全景物体识别任务,同时从相应任务的问题桶中随机采样问题。请注意,为了评估所有现成的MLLM,我们尝试了各种提示,最终使用提示:“[QUESTION]。以段落格式返回答案:‘图像中的物体有:...’,然后以单词格式列出物体及其计数(如果大于1),例如‘两个人’。”,其中[QUESTION]是从物体识别任务桶中随机采样的问题。

主要结果
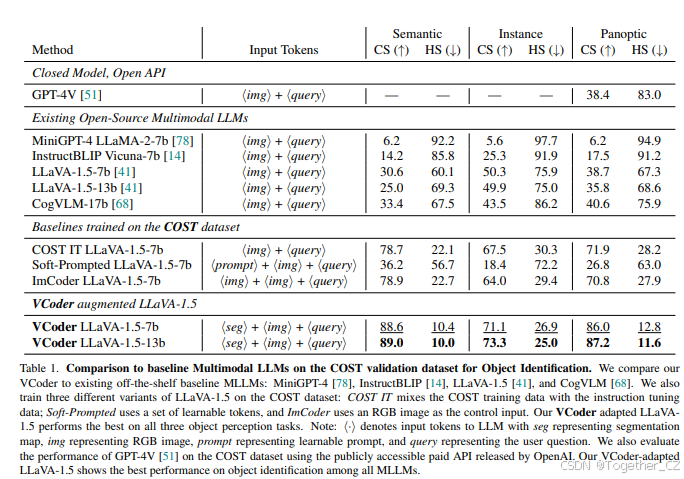
基线:我们在表1中比较了VCoder与开源多模态大语言模型(MiniGPT-4 [78]、InstructBLIP [14]、LLaVA-1.5 [41]和CogVLM [68])在COST验证集上的性能。此外,我们还提供了三个额外的基线,均训练了两个epoch:
-
COST IT LLaVA-1.5:我们将COST训练数据与LLaVA-1.5 [41]中使用的指令微调数据混合,并从头开始微调LLaVA-1.5模型,遵循Liu [41]的设置。
-
Soft-Prompted LLaVA-1.5:我们在LLM输入前添加576个可学习的token((prompt)),并仅在COST训练数据集上微调_(prompt)_参数。
-
ImCoder LLaVA-1.5:我们使用RGB图像作为控制输入,而不是分割图,并在COST训练数据集上训练VCoder。
如表1所示,我们注意到所有现有的MLLM在我们的COST验证集上表现不佳,表明它们在计数和识别物体方面的能力不足。请注意,现有的MLLM在实例物体识别上表现相对较好,这再次证实了我们的观点,即MLLM在检测显著物体方面比背景物体更好。尽管在COST数据集上训练的基线表现相对较好,但它们仍然落后于VCoder。值得注意的是,使用分割图作为控制输入比使用RGB图像表现更好,证明了分割图的重要性。
与GPT-4V [51]的比较:我们使用OpenAI新发布的gpt-4-vision-preview1 API获取GPT-4V的响应。我们的实验表明,GPT-4V的响应在所有物体识别任务中保持一致,与全景识别任务紧密对齐。因此,我们仅在全景物体识别任务上将VCoder与GPT-4V进行比较,以减少API请求(由于本项目期间每日API请求限制为500次)。如表1所示,GPT-4V [51]在性能上明显落后于我们的VCoder,这再次证实了我们的观点,即现有的MLLM无法准确执行物体级感知。
5 使用MLLM进行物体顺序感知
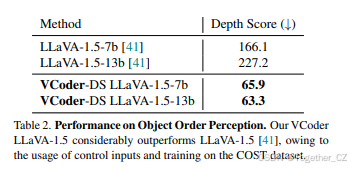
如图4所示,可以利用多种感知模态通过VCoder提高MLLM的物体感知能力。本节介绍了我们使用分割图和深度图作为控制输入的VCoder实验。我们将生成的MLLM称为VCoder-DS LLaVA-1.5。直观地说,预测物体顺序隐含地意味着识别图像中的物体。因此,对于物体顺序感知任务(图3(b)),我们同时使用<depth>和<seg>输入,而仅使用<seg>输入作为物体识别的额外控制。
在训练过程中,我们使用了包括COST数据集中的物体识别和物体顺序感知组件的混合数据集。我们还使用了从LLaVA-1.5 [41]中使用的指令微调数据中随机采样的约20万张图像-对话(以及使用OneFormer [26]获得的相应分割图)对。我们按照第4节中提到的相同超参数设置对VCoder进行了一个epoch的训练。
如表2所示,我们的VCoder-DS LLaVA-1.5在COST验证集上显著优于基础MLLM LLaVA-1.5 [41]。为了定量评估MLLM在深度顺序感知任务上的性能,我们使用物体在真实值和预测值中的位置绝对差计算深度分数(DS)。我们在附录中提供了计算深度分数的更多细节。
6 局限性
尽管在COST数据集上训练VCoder后,物体感知性能有所提高,但仍有一些局限性需要未来解决。首先,我们使用OneFormer [26]构建了COST数据集,由于它是在封闭词汇表数据集[38]上训练的,因此只能感知属于有限类别数量的物体。对于实际应用,开发一个涵盖更多类别和不同粒度的MLLM物体感知基准至关重要。其次,计数、幻觉和深度分数使用一对一词语匹配,这需要手动定义同义词之间的映射。探索克服手动定义同义词映射的方法将是有前景的。最后,如图6所示,分割图中的不准确性可能导致VCoder的失败。探索减少对控制输入的过度依赖以处理感知模态中的不准确上下文将是有趣的。
7 结论
本工作分析了多模态大语言模型(MLLM)的物体级感知能力。尽管MLLM是优秀的视觉推理者,但它们在简单但基本的物体感知任务上表现不佳。为了提高MLLM的物体感知能力,我们提出了COST数据集,用于训练和评估MLLM在物体感知任务中的表现。我们在COST数据集上对不同的现成MLLM和GPT-4V进行了基准测试,并观察到它们的糟糕表现。因此,我们提出了使用感知模态作为控制输入,并使用多功能视觉编码器(VCoder)作为将控制输入投影到LLM嵌入空间的适配器。我们的VCoder可以轻松扩展以利用各种模态作为控制输入,具体取决于任务。为了量化MLLM中的物体级感知能力,我们引入了计数分数(CS)、幻觉分数(HS)和深度分数(DS)。我们使用VCoder适配了LLaVA-1.5,仅在COST数据集上训练了VCoder,并展示了其在物体感知任务中的改进性能,同时保留了推理性能。我们希望我们的工作能够激励研究社区专注于开发MLLM的物体感知数据集,并开发在感知和推理方面同样出色的视觉系统。
致谢
我们感谢Eric Zhang和Kai Wang(JJ的实验室同事)在项目开始前的深入讨论以及对图2设计的宝贵反馈。我们还感谢Georgia Tech的ML中心对本工作的慷慨支持。



















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











