






这篇文章提出了一种新的可变形注意力Transformer(Deformable Attention Transformer, DAT),用于解决现有视觉Transformer模型中的注意力冗余问题。主要内容总结如下:
-
问题背景:
-
现有的视觉Transformer(如ViT、Swin Transformer)在建模长距离依赖时,存在计算成本高、信息冗余等问题。
-
密集注意力(如ViT)导致高计算开销,而稀疏注意力(如Swin Transformer)是数据无关的,可能丢弃重要信息。
-
-
核心贡献:
-
提出了可变形自注意力模块,通过数据依赖的方式选择键值对的位置,使注意力模块能够聚焦于相关区域,捕捉更多信息丰富的特征。
-
设计了可变形注意力Transformer(DAT),作为通用的视觉骨干网络,适用于图像分类和密集预测任务。
-
-
方法细节:
-
可变形注意力机制:通过偏移网络从查询中学习参考点的偏移量,生成可变形键和值,增强注意力的灵活性和效率。
-
相对位置偏差:引入可变形相对位置偏差,增强空间信息的建模能力。
-
模型架构:DAT采用金字塔结构,结合局部注意力和可变形注意力,逐步提取多尺度特征。
-
-
实验验证:
-
在ImageNet-1K分类、COCO目标检测和ADE20K语义分割任务上进行了实验,DAT在多个基准测试中均取得了优于现有模型(如Swin Transformer、PVT)的性能。
-
消融实验验证了可变形注意力和相对位置偏差的有效性。
-
-
主要优势:
-
灵活性:数据依赖的注意力机制能够自适应地关注重要区域。
-
高效性:通过共享偏移量,减少了计算开销,同时保持了线性空间复杂度。
-
通用性:DAT可作为通用骨干网络,适用于多种视觉任务。
-
这篇文章通过引入可变形注意力机制,提出了一种高效且灵活的视觉Transformer模型,显著提升了视觉任务中的性能表现。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里。
摘要
Transformer 最近在各种视觉任务中表现出卓越的性能。其较大的、有时甚至是全局的感受野赋予了 Transformer 模型比 CNN 模型更高的表示能力。然而,简单地扩大感受野也带来了一些问题。一方面,使用密集注意力(如在 ViT 中)会导致过高的内存和计算成本,并且特征可能会受到超出感兴趣区域的不相关部分的影响。另一方面,PVT 或 Swin Transformer 中采用的稀疏注意力是数据无关的,可能会限制建模长距离关系的能力。为了缓解这些问题,我们提出了一种新颖的可变形自注意力模块,其中自注意力中的键值对位置以数据依赖的方式选择。这种灵活的方案使自注意力模块能够专注于相关区域并捕捉更多信息丰富的特征。在此基础上,我们提出了可变形注意力Transformer(Deformable Attention Transformer),这是一种用于图像分类和密集预测任务的可变形注意力通用骨干模型。大量实验表明,我们的模型在多个基准测试中一致地取得了改进的结果。

图 1. DAT 与其他 Vision Transformer 模型以及 CNN 模型中的 DCN 的比较。红色星号和蓝色星号表示不同的查询,实线边界的掩码表示查询所关注的区域。在数据无关的方式中:(a) ViT [12] 对所有查询采用全注意力。(b) Swin Transformer [26] 使用分区的窗口注意力。在数据依赖的方式中:(c) DCN [9] 为每个查询学习不同的可变形点。(d) DAT 为所有查询学习共享的可变形点。
1 引言
Transformer [34] 最初是为解决自然语言处理任务而引入的。最近,它在计算机视觉领域展示了巨大的潜力 [36, 12, 26]。开创性工作 Vision Transformer [12](ViT)通过堆叠多个 Transformer 块来处理非重叠的图像块(即视觉 token)序列,从而构建了一个无卷积的图像分类模型。与 CNN 模型 [19, 18] 相比,基于 Transformer 的模型具有更大的感受野,并且在建模长距离依赖关系方面表现出色,这在大规模训练数据和模型参数的条件下被证明能够取得卓越的性能。然而,视觉识别中的冗余注意力是一把双刃剑,存在多个缺点。具体来说,每个查询 patch 需要关注过多的键,导致高计算成本和缓慢的收敛速度,并增加了过拟合的风险。
为了避免过多的注意力计算,现有工作 [6, 11, 43, 46, 36, 49] 利用精心设计的高效注意力模式来降低计算复杂度。其中两个代表性方法是 Swin Transformer [26] 采用的基于窗口的局部注意力和 Pyramid Vision Transformer (PVT) [36] 通过对键和值特征图进行下采样来节省计算。尽管有效,但这些手工设计的注意力模式是数据无关的,可能不是最优的。很可能相关的键/值被丢弃,而不太重要的键/值仍然保留。
理想情况下,我们希望给定查询的候选键/值集是灵活的,并且能够适应每个输入,从而缓解手工设计的稀疏注意力模式中的问题。事实上,在 CNN 的文献中,学习卷积滤波器的可变形感受野已被证明在数据依赖的基础上选择性地关注更具信息量的区域是有效的 [9]。最著名的工作 Deformable Convolution Networks [9] 在许多具有挑战性的视觉任务中取得了令人印象深刻的结果。这激励我们探索在 Vision Transformers 中引入可变形注意力模式。然而,直接实现这一想法会导致不合理的高内存/计算复杂度:可变形偏移引入的开销与 patch 数量的平方成正比。因此,尽管最近的一些工作 [7, 46, 54] 研究了 Transformer 中的可变形机制,但由于高计算成本,它们都没有将其作为构建强大骨干网络的基本构建块。相反,它们的可变形机制要么在检测头中采用 [54],要么作为预处理层用于为后续骨干网络采样 patch [7]。
在本文中,我们提出了一种简单高效的可变形自注意力模块,并构建了一个强大的金字塔骨干网络,称为可变形注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集预测任务。与 DCN 不同,DCN 为整个特征图中的不同像素学习不同的偏移量,我们提出学习几组查询无关的偏移量,将键和值移动到重要区域(如图 1(d) 所示),基于 [3, 52] 中的观察,全局注意力通常会导致不同查询的注意力模式几乎相同。这种设计既保持了线性空间复杂度,又为 Transformer 骨干引入了可变形注意力模式。具体来说,对于每个注意力模块,首先生成均匀网格的参考点,这些参考点在输入数据中是相同的。然后,一个偏移网络以查询特征为输入,生成所有参考点的相应偏移量。通过这种方式,候选键/值被移动到重要区域,从而增强了原始自注意力模块的灵活性和效率,以捕捉更多信息丰富的特征。
总结来说,我们的贡献如下:我们提出了第一个用于视觉识别的可变形自注意力骨干网络,其中数据依赖的注意力模式赋予了更高的灵活性和效率。在 ImageNet [10]、ADE20K [51] 和 COCO [25] 上的大量实验表明,我们的模型在图像分类的 top-1 准确率上比 Swin Transformer 等竞争基线模型高出 0.7,在语义分割的 mIoU 上高出 1.2,在目标检测的 box AP 和 mask AP 上均高出 1.1。对于小目标和大目标的优势更为明显,分别高出 2.1。
2 相关工作
Transformer 视觉骨干网络。自 ViT [12] 提出以来,改进工作 [6, 11, 26, 28, 36, 43, 49] 主要集中在为密集预测任务学习多尺度特征和高效注意力机制。这些注意力机制包括窗口注意力 [11, 26]、全局 token [6, 21, 32]、焦点注意力 [43] 和动态 token 大小 [37]。最近,基于卷积的方法被引入到 Vision Transformer 模型中。其中一些研究专注于通过卷积操作补充 Transformer 模型,以引入额外的归纳偏差。CvT [39] 在 token 化过程中采用卷积,并利用步幅卷积来降低自注意力的计算复杂度。ViT with convolutional stem [41] 提出在早期阶段添加卷积以实现更稳定的训练。CSwin Transformer [11] 采用基于卷积的位置编码技术,并在下游任务中展示了改进。这些基于卷积的技术中的许多可以应用于 DAT 之上以进一步提高性能。
可变形 CNN 和注意力。可变形卷积 [9, 53] 是一种强大的机制,可以根据输入数据灵活地关注空间位置。最近,它被应用于 Vision Transformers [7, 46, 54]。Deformable DETR [54] 通过在 CNN 骨干网络上为每个查询选择少量键来改进 DETR [4] 的收敛性。其可变形注意力不适合作为视觉骨干网络进行特征提取,因为键的缺乏限制了表示能力。此外,Deformable DETR 中的注意力来自简单的线性投影,并且键在查询 token 之间不共享。DPT [7] 和 PS-ViT [46] 构建了可变形模块来优化视觉 token。具体来说,DPT 提出了一个可变形 patch 嵌入来跨阶段优化 patch,而 PS-ViT 在 ViT 骨干之前引入了一个空间采样模块来改进视觉 token。它们都没有将可变形注意力引入视觉骨干网络。相比之下,我们的可变形注意力采用了一种强大而简单的设计,学习一组在视觉 token 之间共享的全局键,并且可以作为各种视觉任务的通用骨干网络。我们的方法也可以被视为一种空间自适应机制,已在各种工作中被证明是有效的 [16, 38]。
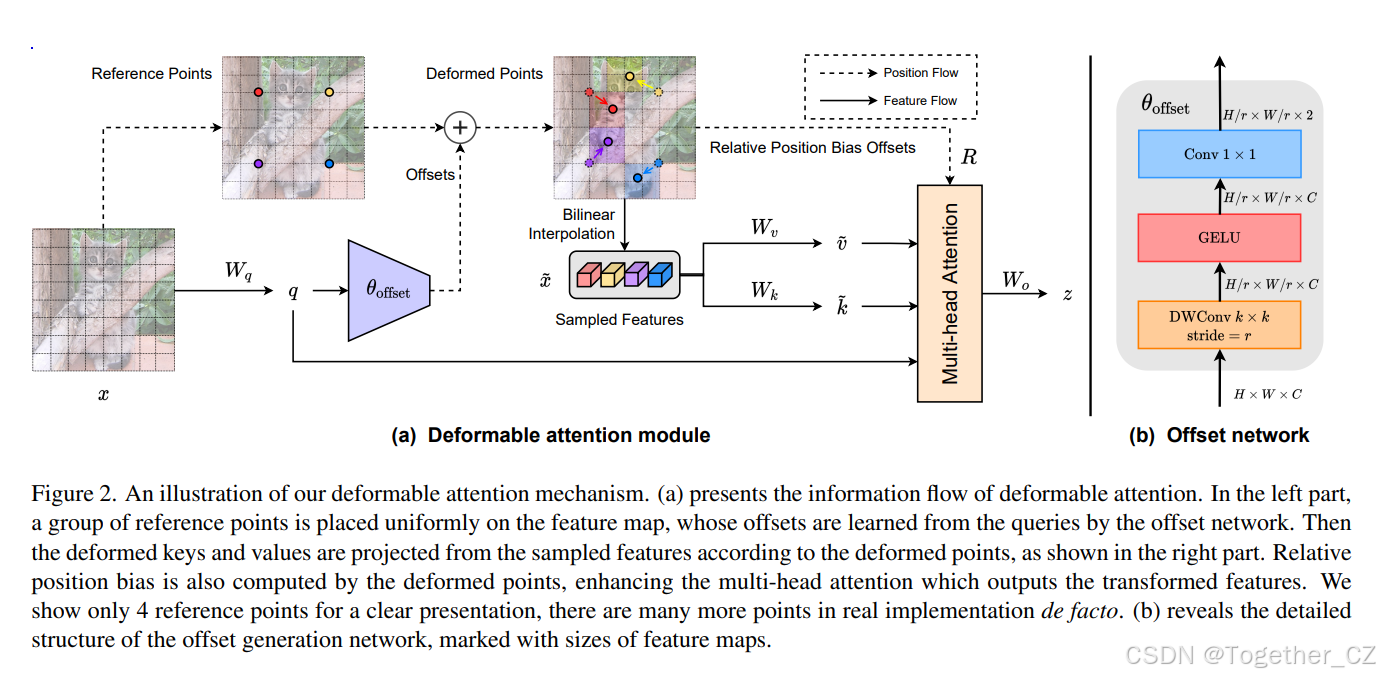
图 2. 我们提出的可变形注意力机制的示意图。(a) 展示了可变形注意力的信息流。在左侧部分,一组参考点均匀地放置在特征图上,其偏移量通过偏移网络从查询中学习得到。然后,根据可变形点从采样特征中投影出可变形键和值,如右侧部分所示。相对位置偏差也通过可变形点计算,增强了多头注意力,输出转换后的特征。为了清晰展示,我们仅显示了 4 个参考点,实际实现中有更多的点。(b) 展示了偏移生成网络的详细结构,并标注了特征图的大小。
3 可变形注意力Transformer
预备知识


可变形注意力

具体来说,我们提出了可变形注意力,以在特征图中重要区域的指导下有效地建模 token 之间的关系。这些关注区域由多组可变形采样点确定,这些采样点通过偏移网络从查询中学习。我们采用双线性插值从特征图中采样特征,然后将采样特征输入键和值投影以获得可变形键和值。最后,应用标准的多头注意力将查询与采样键进行注意力计算,并从可变形值中聚合特征。此外,可变形点的位置提供了更强大的相对位置偏差,以促进可变形注意力的学习,这将在后续部分中讨论。


偏移生成。如前所述,我们采用一个子网络来生成偏移量,该子网络消耗查询特征并分别输出参考点的偏移值。考虑到每个参考点覆盖一个局部 s×s 区域(s 是偏移量的最大值),生成网络还应具有局部特征的感知能力,以学习合理的偏移量。因此,我们将子网络实现为两个卷积模块,带有非线性激活,如图 2(b) 所示。输入特征首先通过一个 5×5 深度卷积来捕捉局部特征。然后,采用 GELU 激活和一个 1×1 卷积来获得 2D 偏移量。值得注意的是,1×1 卷积中的偏置被丢弃,以减轻对所有位置的强制偏移。
偏移组。为了促进可变形点的多样性,我们遵循 MHSA 中的类似范式,将特征通道分成 G 组。每个组的特征使用共享的子网络分别生成相应的偏移量。在实践中,注意力模块的头数 M 设置为偏移组 G 大小的倍数,确保多个注意力头分配给一组可变形键和值。


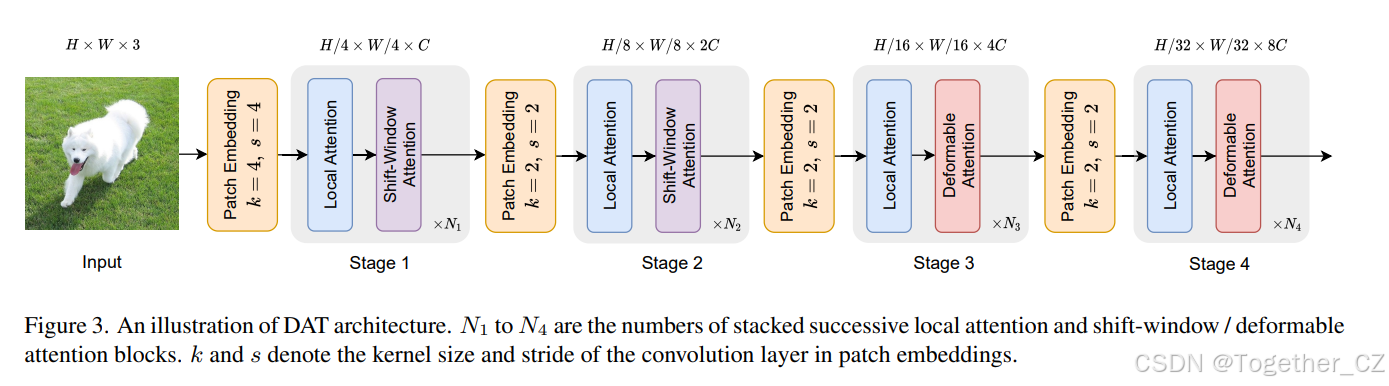
图 3. DAT 架构的示意图。N1 到 N4 表示堆叠的连续局部注意力和移位窗口/可变形注意力块的数量。k 和 s 表示 patch 嵌入中卷积层的核大小和步幅。
模型架构

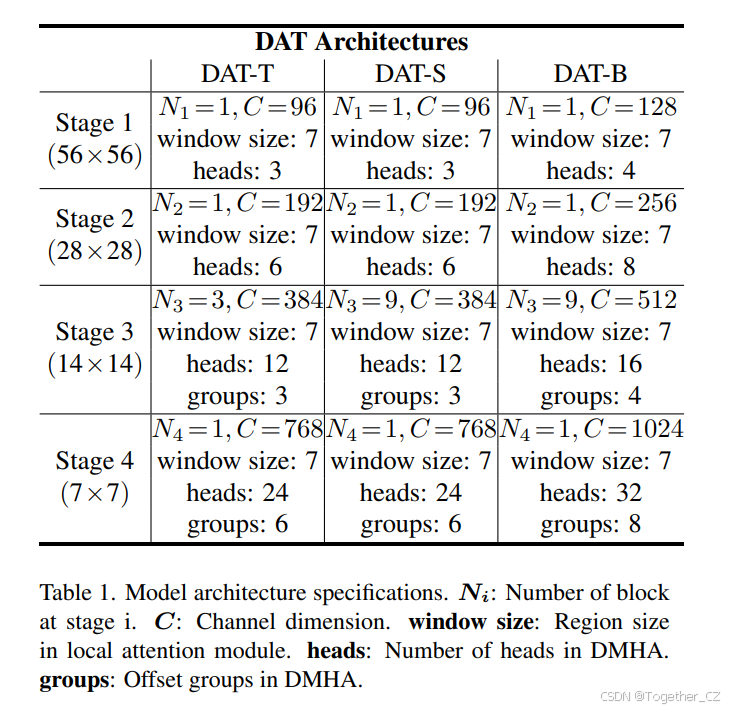
我们在 DAT 的第三和第四阶段引入了连续的局部注意力和可变形注意力块。特征图首先通过基于窗口的局部注意力进行局部信息聚合,然后通过可变形注意力块建模局部增强 token 之间的全局关系。这种局部和全局感受野交替设计的注意力块有助于模型学习强表示,类似于 GLiT [5]、TNT [15] 和 Pointformer [29] 中的模式。由于前两个阶段主要学习局部特征,因此在早期阶段使用可变形注意力的需求较少。此外,前两个阶段的键和值具有较大的空间大小,这大大增加了可变形注意力中点积和双线性插值的计算开销。因此,为了在模型容量和计算负担之间取得平衡,我们仅在第三和第四阶段放置可变形注意力,并在早期阶段采用 Swin Transformer [26] 的移位窗口注意力以获得更好的表示。我们构建了三种不同参数和 FLOPs 的 DAT 变体,以与其他 Vision Transformer 模型进行公平比较。我们通过在第三阶段堆叠更多块并增加隐藏维度来改变模型大小。详细的架构如表 1 所示。请注意,DAT 的前两个阶段还有其他设计选择,例如 PVT 中的 SRA 模块。我们在表 7 中展示了比较结果。
4 实验
我们在多个数据集上进行了实验,以验证我们提出的 DAT 的有效性。我们在 ImageNet-1K [10] 分类、COCO [25] 目标检测和 ADE20K [51] 语义分割任务上展示了我们的结果。此外,我们提供了消融研究和可视化,以进一步展示我们方法的有效性。
ImageNet-1K 分类
ImageNet-1K [10] 数据集包含 1.28M 训练图像和 50K 验证图像。我们在训练集上训练了三种 DAT 变体,并在验证集上报告了 Top-1 准确率,以与其他 Vision Transformer 模型进行比较。

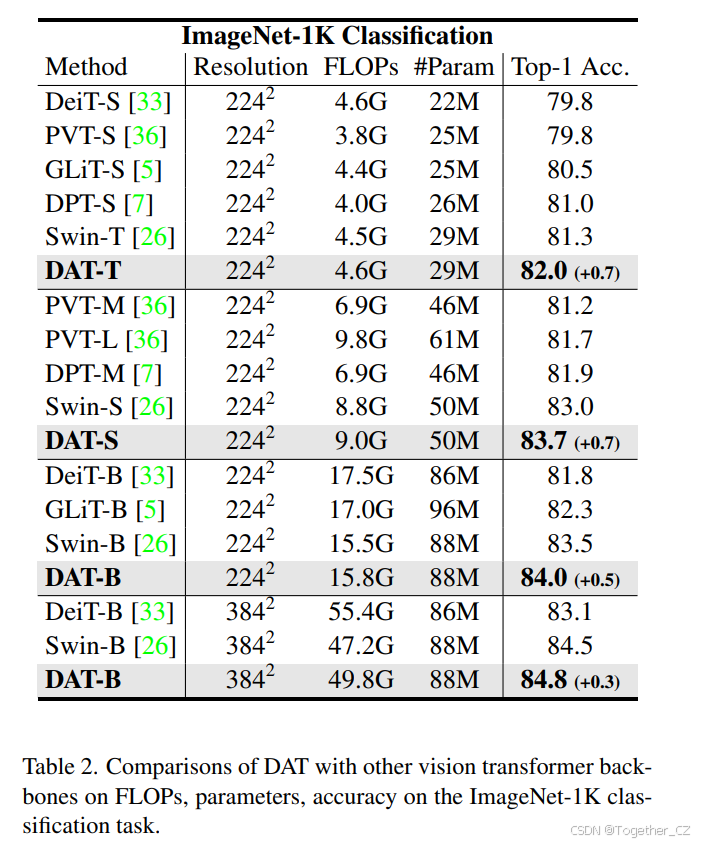
我们在表 2 中报告了 300 个训练 epoch 的结果。与其他最先进的 Vision Transformers 相比,我们的 DAT 在相似的计算复杂度下显著提高了 Top-1 准确率。我们的方法 DAT 在所有三个尺度上都优于 Swin Transformer [26]、PVT [36]、DPT [7] 和 DeiT [33]。在没有在 Transformer 块中插入卷积 [13, 14, 35] 或在 patch 嵌入中使用重叠卷积 [6, 11, 45] 的情况下,DAT 在 Swin Transformer [26] 对应模型上分别获得了 +0.7、+0.7 和 +0.5 的提升。在 384×384 分辨率下进行微调时,我们的模型继续比 Swin Transformer 表现更好,提升了 0.3。
COCO 目标检测
COCO [25] 目标检测和实例分割数据集包含 118K 训练图像和 5K 验证图像。我们使用 DAT 作为 RetinaNet [24]、Mask R-CNN [17] 和 Cascade Mask R-CNN [2] 框架中的骨干网络,以评估我们方法的有效性。我们在 ImageNet-1K 数据集上预训练我们的模型 300 个 epoch,并遵循 Swin Transformer [26] 中的类似训练策略以公平比较我们的方法。
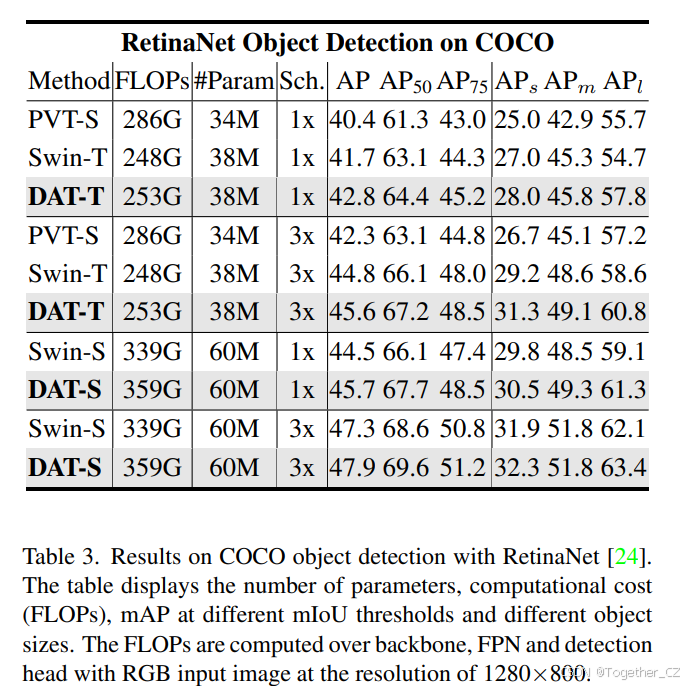
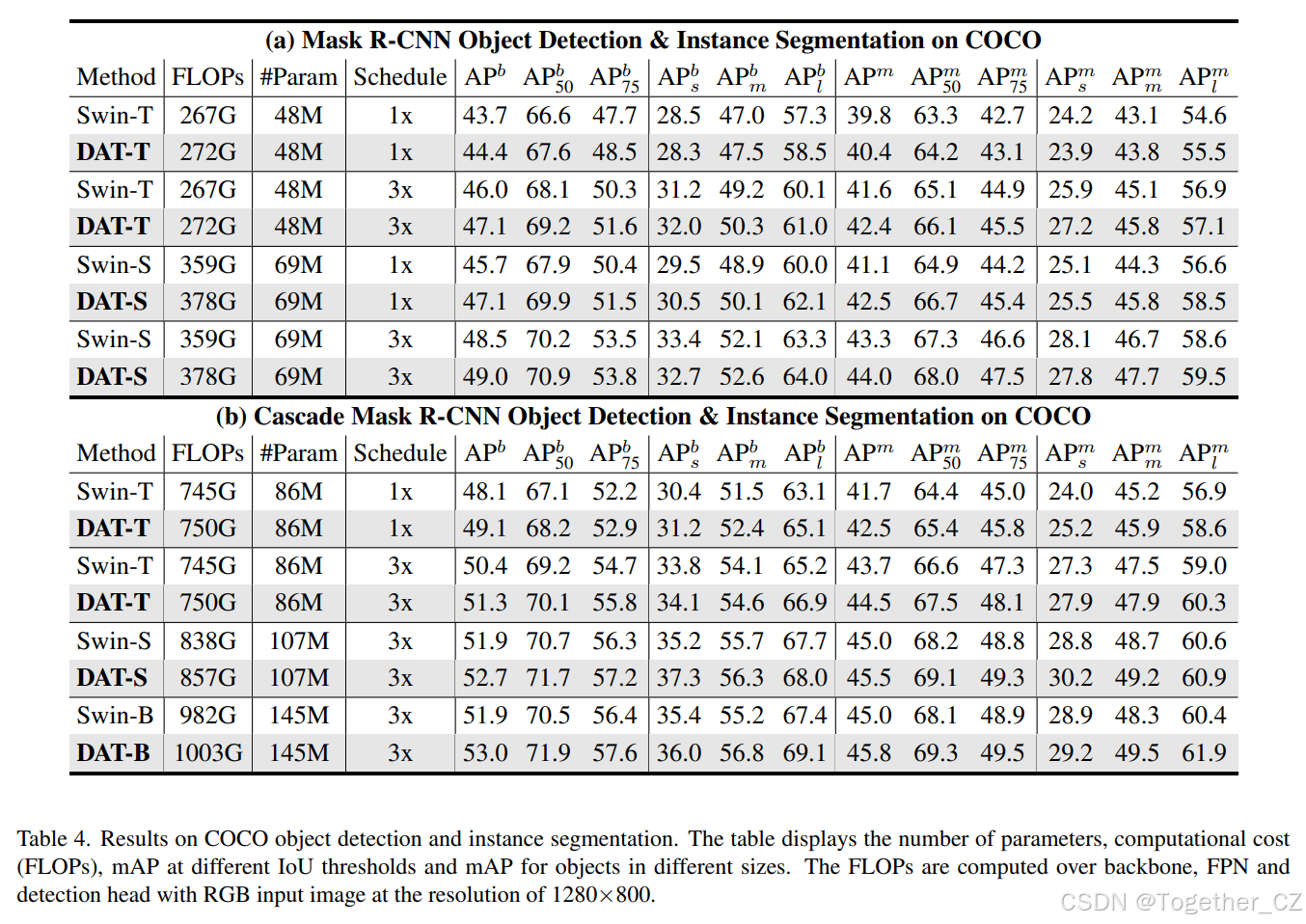
我们在 RetinaNet 模型上报告了 DAT 在 1x 和 3x 训练计划中的结果。如表 3 所示,DAT 在 tiny 和 small 模型上分别比 Swin Transformer 高出 1.1 和 1.2 mAP。当在两阶段检测器(如 Mask R-CNN 和 Cascade Mask R-CNN)中实现时,我们的模型在不同大小上比 Swin Transformer 模型一致地取得了改进,如表 4 所示。我们可以看到,DAT 在大目标上取得了最大的改进(高达 +2.1),这是由于在建模长距离依赖关系方面的灵活性。小目标检测和实例分割的差距也很明显(高达 +2.1),这表明 DAT 也具有建模局部区域关系的能力。
ADE20K 语义分割
ADE20K [51] 是一个流行的语义分割数据集,包含 20K 训练图像和 2K 验证图像。我们在两个广泛采用的分割模型 SemanticFPN [22] 和 UperNet [40] 上应用了 DAT。为了与 PVT [36] 和 Swin Transformer [26] 进行公平比较,我们遵循学习率计划和训练 epoch,除了随机深度程度,这是影响最终性能的关键超参数。我们为 DAT 的 tiny、small 和 base 变体分别设置为 0.3、0.3 和 0.5。使用在 ImageNet-1K 上预训练的模型,我们训练 SemanticFPN 40k 步,训练 UperNet 160k 步。在表 5 中,我们报告了所有方法在验证集上的最高 mIoU 分数。与 PVT [36] 相比,我们的 tiny 模型在 FLOPs 更少的情况下比 PVT-S 高出 +0.5 mIoU,并且在模型大小稍大的情况下分别实现了 +3.1 和 +2.5 的 mIoU 提升。我们的 DAT 在每个模型尺度上都比 Swin Transformer 有显著改进,分别提高了 +1.0、+0.7 和 +1.2 的 mIoU,展示了我们方法的有效性。
消融研究
在本节中,我们对 DAT 中的关键组件进行消融研究,以验证这些设计的有效性。我们基于 DAT-T 在 ImageNet-1K 分类上报告结果。

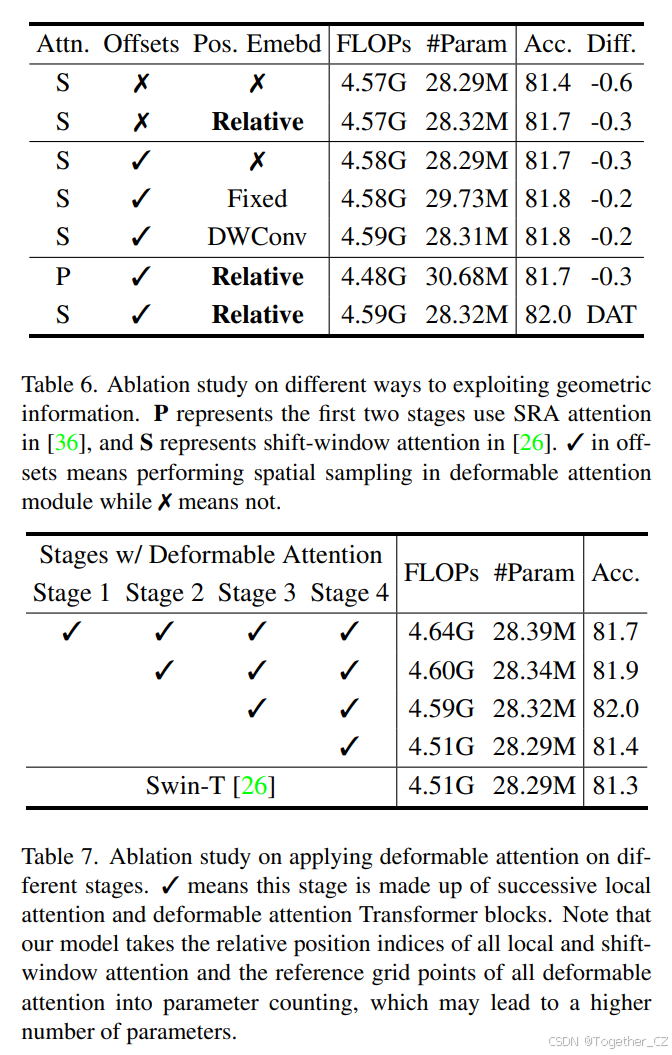
几何信息利用。我们首先评估了我们提出的可变形偏移和可变形相对位置嵌入的有效性,如表 6 所示。无论是在特征采样中采用偏移量还是使用可变形相对位置嵌入,都提供了 +0.3 的改进。我们还尝试了其他类型的位置嵌入,包括固定的可学习位置偏差和 [11] 中的深度卷积。但它们都没有有效,仅比没有位置嵌入的模型提高了 +0.1,这表明我们的可变形相对位置偏差与可变形注意力更兼容。从表 6 的第 6 行和第 7 行还可以观察到,我们的模型可以适应前两个阶段的不同注意力模块,并取得有竞争力的结果。我们的模型在前两个阶段使用 SRA [36] 注意力,比 PVT-M 高出 0.5,且 FLOPs 减少了 65%。
不同阶段的可变形注意力。我们用可变形注意力替换 Swin Transformer [26] 的移位窗口注意力,应用于不同阶段。如表 7 所示,仅替换最后阶段的注意力提高了 0.1,替换最后两个阶段导致性能提升 0.7(总体准确率达到 82.0)。然而,在早期阶段替换更多的可变形注意力会略微降低准确率。
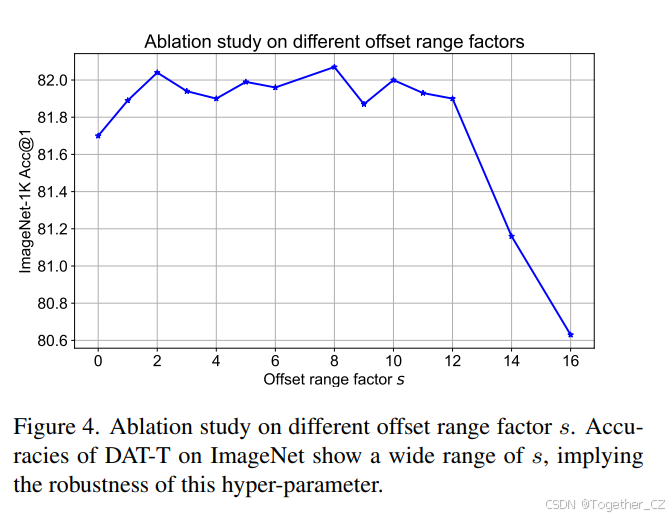
不同 s 的消融。我们进一步研究了不同最大偏移量的影响,即论文中的偏移范围比例因子 s。我们对 s 进行了消融实验,范围从 0 到 16,其中 14 对应于特征图大小(第三阶段为 14×14)的最大合理偏移量。如图 4 所示,s 的广泛选择范围显示了 DAT 对该超参数的鲁棒性。实际上,我们在论文中为所有模型选择了一个较小的 s=2,无需额外调整。
可视化
为了验证可变形注意力的有效性,我们使用类似于 DCN 的机制来可视化多个可变形注意力层中最重要的键,如图 5 所示。橙色圆圈显示了在多个头上具有最高传播注意力分数的关键点。半径越大表示分数越高。请注意,右下角的图像显示了一个人挥舞球拍击打网球。

附录 A DAT 与 Deformable DETR
在本节中,我们提供了我们提出的可变形注意力与从可变形卷积 [9] 直接适应的多尺度可变形注意力的详细比较,后者在 Deformable DETR [54] 中也被称为多尺度可变形注意力。
首先,我们的可变形注意力作为视觉骨干网络中的特征提取器,而 Deformable DETR 中的可变形注意力则替换了 DETR [4] 中的普通注意力,作为检测头。其次,Deformable DETR 中第 m 个头的查询 q 的注意力公式为:

第三,Deformable DETR 中的可变形注意力与点积注意力不兼容,因为其内存消耗巨大,如论文第 3.2 节所述。因此,使用线性预测的注意力来避免计算点积,并且采用较少的键 K=4 以减少内存开销。
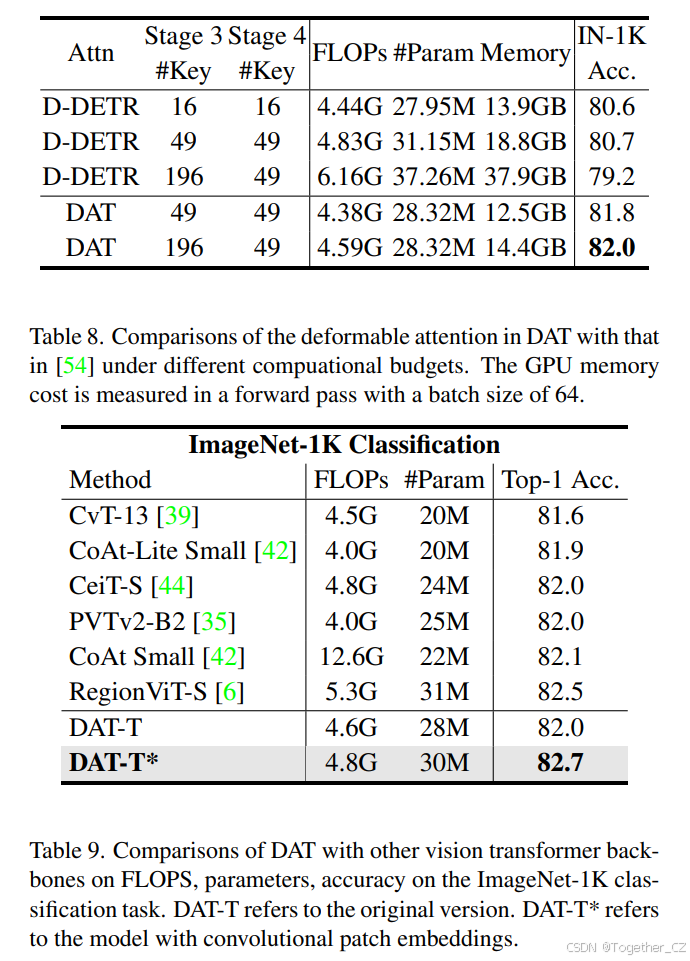
为了实验验证我们的主张,我们将 DAT 中的可变形注意力模块替换为 [54] 中的模块,以验证直接适应在视觉骨干网络中效果较差。比较结果如表 8 所示。比较第一行和最后一行,我们可以看到在较小的内存预算下,Deformable DETR 模型的键数设置为 16 以减少内存使用,并且性能降低了 1.4%。比较第三行和最后一行,我们可以看到,与 DAT 具有相同键数的 D-DETR 注意力消耗了 2.6 倍的内存和 1.3 倍的 FLOPs,而性能仍然低于 DAT。
附录 B 向 DAT 添加卷积
最近的工作 [6, 11, 35, 39] 已经证明,在 Vision Transformer 架构中采用卷积层可以进一步提高模型性能。例如,使用卷积 patch 嵌入通常可以将 ImageNet 分类任务的性能提高 0.5% 到 1.0%。值得注意的是,我们提出的 DAT 可以轻松结合这些技术,而我们在主论文中保持了无卷积架构,以便与基线进行公平比较。

为了充分探索 DAT 的能力,我们将原始模型中的 patch 嵌入层替换为步幅和重叠卷积。比较结果如表 9 所示,其中基线模型也有类似的修改。结果表明,我们的模型在添加卷积模块后比原始版本提高了 0.7%,并且始终优于其他基线。
附录 C 更多可视化
我们可视化 DAT 中学习到的可变形位置,以验证我们方法的有效性。如图 6 所示,采样点描绘在目标检测框和实例分割掩码的顶部,从中我们可以看到这些点被移动到目标对象。在左列中,可变形点收缩到两个目标长颈鹿,而其他点保持几乎均匀的网格,偏移量较小。在中间列中,可变形点在两个阶段中密集分布在人的身体和冲浪板上。右列显示可变形点很好地聚焦到每个甜甜圈上,这表明我们的模型能够更好地建模几何形状,即使有多个目标。上述可视化表明,DAT 学习有意义的偏移量以采样更好的键进行注意力计算,从而提高了在各种视觉任务上的性能。

我们还提供了特定查询 token 的注意力图的可视化结果,并与 Swin Transformer [26] 进行了比较,如图 7 所示。我们展示了具有最高注意力值的关键 token。可以观察到,我们的模型更关注相关部分。作为一个展示,我们的模型将大部分注意力分配给了前景对象,例如第一行中的两只长颈鹿。另一方面,Swin Transformer 中的感兴趣区域相对局部,无法区分前景和背景,如最后一个冲浪板所示。



















 2477
2477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











