






这篇文章的主要内容可以总结如下:
-
FP8浮点格式的提出:文章提出了一种新的8位浮点(FP8)格式,用于加速深度学习训练和推理。FP8格式包含两种编码:E4M3(4位指数和3位尾数)和E5M2(5位指数和2位尾数)。E5M2遵循IEEE 754规范,而E4M3通过减少特殊值的表示来扩展动态范围。
-
FP8的优势:FP8格式在保持模型精度的同时,显著减少了计算和内存带宽的需求。相比于16位浮点格式(如FP16和bfloat16),FP8在训练和推理中表现出色,尤其是在大规模语言模型和图像分类任务中。
-
实验验证:文章通过大量实验验证了FP8格式的有效性。实验涵盖了多种神经网络架构(如CNN、RNN和Transformer),并在图像分类、语言翻译和语言模型等任务上进行了测试。结果表明,FP8训练的结果与16位训练的结果相当,且在某些情况下优于int8量化。
-
训练和推理的简化:使用FP8进行训练和推理可以简化部署流程,因为训练和推理使用相同的数据类型。相比之下,传统的int8推理需要额外的训练后量化(PTQ)或量化感知训练(QAT)来保持模型精度。
-
每张量缩放因子:文章指出,某些网络需要为每个张量设置单独的缩放因子,以保持FP8训练的精度。这种灵活性通过软件实现,而不是通过硬件中的可编程指数偏差来实现。
-
未来工作:文章提到,未来的研究将探索将更多张量转换为FP8格式,以进一步优化训练和推理的性能。
这篇文章展示了FP8格式在深度学习中的潜力,特别是在大规模模型训练和推理中的高效性和准确性。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
FP8 是加速深度学习训练和推理的自然进展,超越了现代处理器中常见的 16 位格式。本文提出了一种 8 位浮点数(FP8)二进制交换格式,包含两种编码:E4M3(4 位指数和 3 位尾数)和 E5M2(5 位指数和 2 位尾数)。E5M2 遵循 IEEE 754 的特殊值表示规范,而 E4M3 通过不表示无穷大且仅使用一个尾数位模式表示 NaN 来扩展动态范围。我们在各种图像和语言任务上展示了 FP8 格式的有效性,能够有效匹配 16 位训练会话的结果质量。我们的研究涵盖了主要的现代神经网络架构——CNN、RNN 和基于 Transformer 的模型,所有超参数均与 16 位基线训练会话保持一致。我们的训练实验包括高达 1750 亿参数的大型语言模型。我们还研究了使用 16 位格式训练的语言模型的 FP8 训练后量化,这些模型在固定点 int8 量化中表现不佳。
1. 引言
深度学习(DL)技术的不断进步要求神经网络模型规模和计算资源的持续增加。例如,像 GPT-3 [2]、Turing-Megatron [18]、PaLM [4] 和 OPT [25] 这样的大型自然语言模型需要在数千个处理器上训练数周。减少数值表示的精度一直是深度学习训练和推理加速的基石。常见的训练浮点类型包括 IEEE 单精度、TF32 模式 [19]、IEEE 半精度 [14] 和 bfloat16 [9]。虽然一些研究出版物将比特减少到极致,即 1 位二进制网络 [5, 7, 26, 24, 17],但它们未能保持许多实际应用所需的结果质量。对于推理,固定点 int8 表示是一种流行的选择。在某些情况下,即使是 int8 推理也可能难以保持应用部署所需的精度 [1]。文献中还提出了其他数值表示,如对数格式 [15, 11]、posits 和对数与 posit 指数值 [8],但由于所展示的优势不足以证明新的数学管道硬件设计的合理性,这些方法尚未在实践中采用。
FP8 是 16 位浮点类型的自然进展,减少了神经网络训练的计算需求。此外,由于其非线性采样特性,FP8 在推理时相比 int8 也具有优势。Wang 等人 [22] 提出了使用 5 位指数格式训练神经网络,并在 CIFAR-10 和 ILSVRC12 数据集的卷积神经网络(CNN)上验证了其方法。Mellempudi 等人 [12] 研究了 5 位指数格式在更大规模的 CNN 以及基于循环和 Transformer 块的语言翻译网络上的训练。这两篇论文都研究了 16 位权重更新以及随机舍入。[20] 引入了两种 FP8 格式(4 位和 5 位指数字段)用于训练,研究了更广泛的 CNN 以及语音和语言翻译模型。[20] 还研究了使用更高精度训练的网络的 FP8 推理,并引入了批量归一化统计的重新训练以提高结果准确性。Noune 等人 [16] 提出了一种改进的 FP8 表示,将单个编码专用于特殊值以增加表示的动态范围,并广泛研究了指数偏差对结果质量的影响。[10] 的重点是使用各种格式(包括 FP8)对使用更高精度训练的网络进行 8 位推理。
本文描述了一种用于浮点表示的 8 位二进制格式,使用两种 FP8 编码。第 2 节总结了使用 FP8 进行深度学习的基本原则。第 3 节描述了比特编码及其背后的原理。第 4 节展示了对各种任务和模型的训练和推理的实证评估。我们展示了 FP8 训练在多种任务和神经网络模型架构及规模上匹配 FP16 或 bfloat16 训练结果,且无需更改任何模型或优化器超参数。我们的研究包括训练高达 1750 亿参数的非常大的语言模型。考虑广泛的模型规模非常重要,因为已经表明不同规模的模型可能具有不同的数值行为(例如,[12] 中观察到的 Resnet-18 和 Resnet-50 的不同行为)。
2. FP8 在深度学习中的应用
FP8 使用的某些方面影响了二进制交换格式的选择。例如,各种网络所需的动态范围决定了对两种格式的需求,以及对通过软件而不是指数偏差处理缩放因子的偏好。其他方面,如类型转换细节,与二进制格式正交。本节简要回顾了这两个方面。
预计对 FP8 输入的数学运算将产生更高精度的输出,可选择在将结果写入内存之前将其转换为 FP8。这是当今 CPU、GPU 和 TPU 上常见的 16 位浮点格式(FP16 和 bfloat16)的常见做法 [3, 14]。例如,矩阵乘法或点积指令产生单精度输出,但算术密集度较低的操作通常在将 16 位输入转换为单精度后执行。因此,FP8 张量将通过从更宽的类型(如单精度浮点)转换为 FP8 生成。
在将更高精度的值转换为 FP8 之前,需要将其乘以缩放因子,以将其移动到与相应 FP8 格式的可表示范围更好地重叠的范围内。这与混合精度训练中 FP16 的损失缩放非常相似,其中梯度被移动到 FP16 可表示的范围内 [14],[13](幻灯片 13-16)。然而,某些网络需要每个张量的缩放因子,因为 FP8 动态范围不足以覆盖所有张量重要值的联合(见第 3.2 节)。选择缩放因子的启发式方法的细节超出了本文的范围,但总体思路是选择一个缩放因子,使得张量中的最大幅度接近相应格式中的最大可表示幅度。溢出的值随后饱和为最大可表示值。由于 FP8 的动态范围较窄,溢出更有可能发生,因此跳过权重更新(并减少缩放因子),如 FP16 自动混合精度训练 [13] 中所使用的,对于 FP8 来说不是一个好的选择,因为会导致太多跳过的更新。在从 FP8 转换后或线性运算的算术指令产生更高精度输出后,通过乘以缩放因子的倒数来取消缩放更高精度的值。在这两种情况下,只需要最少的额外算术运算。对于矩阵乘法,取消缩放每次点积应用一次,因此通过许多 FP8 输入的乘加运算摊销。算术密集度较低的操作(如非线性、归一化或优化器的权重更新)通常受内存带宽限制,对每个值的额外算术指令不敏感。
虽然类型转换的机制与二进制格式正交,但为了完整起见,我们简要介绍一些 DL 使用的方面。将特殊值从更宽的精度转换为 FP8 会生成 FP8 中的相应特殊值。对于转换为 E4M3,这意味着更宽类型(例如单精度)中的无穷大和 NaN 都会转换为 FP8 中的 NaN。当涉及 FP8 和 FP16 类型的混合精度训练时,需要这种特殊值的处理,因为自动混合精度 [13] 运行时调整损失缩放依赖于引起和检测溢出。此外,可以为可能需要严格处理溢出的用例提供非饱和模式的转换。舍入模式(舍入到最近的偶数、随机等)的选择与交换格式正交,留给实现(软件和可能的硬件)以最大灵活性。
3. FP8 二进制交换格式
FP8 由两种编码组成——E4M3 和 E5M2,其中名称明确指出了指数(E)和尾数(M)的位数。我们使用通用术语“尾数”作为 IEEE 754 标准中尾数字段的同义词(即不包括正常浮点数隐含前导 1 位的位)。FP8 编码的推荐用法是 E4M3 用于权重和激活张量,E5M2 用于梯度张量。虽然某些网络可以仅使用 E4M3 或 E5M2 类型进行训练,但有些网络需要两种类型(或必须在 FP8 中维护更少的张量)。这与 [20, 16] 中的发现一致,其中推理和训练的前向传递使用 E4M3 的变体,训练的反向传递中的梯度使用 E5M2 的变体。
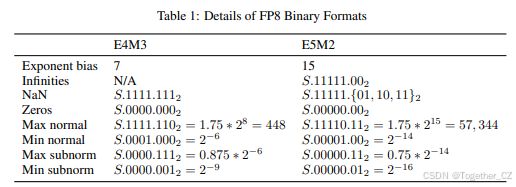
FP8 编码的详细信息在表 1 中指定。我们使用 SS.E.M 符号来描述表中的二进制编码,其中 SS 是符号位,E 是指数字段(4 或 5 位,包含偏置指数),M 是 3 位或 2 位尾数。下标为 2 的值为二进制,否则为十进制。
这些 FP8 格式的设计遵循了与 IEEE-754 规范保持一致的原则,仅在预期对 DL 应用精度有显著好处时才偏离。因此,E5M2 格式遵循 IEEE 754 的指数和特殊值规范,可以视为具有较少尾数位的 IEEE 半精度(类似于 bfloat16 和 TF32 可以视为具有较少位的 IEEE 单精度)。这允许在 E5M2 和 IEEE FP16 格式之间进行直接转换。相比之下,E4M3 的动态范围通过回收用于特殊值的大部分位模式而扩展,因为在这种情况下,实现的更大范围比支持特殊值的多种编码更有用。
特殊值表示
我们通过表示较少的特殊值来扩展 E4M3 格式的窄动态范围,采用它们的位模式用于正常值。不表示无穷大(见第 2 节中的溢出处理细节),并且我们仅保留一个尾数位模式用于 NaN。此修改将动态范围扩展了一个额外的 2 次方,从 17 个 binade 增加到 18 个。我们获得了七个更多幅度的表示(256, 288, 320, 352, 384, 416, 448),对应于偏置指数值 1111211112。没有此修改的最大可表示幅度为 240。为了与 IEEE 754 规范保持一致,我们保留了零和 NaN 的正负表示。虽然我们可以通过仅对零和 NaN 使用一个编码来获得一个额外的可表示幅度 480,但这将打破 IEEE 754 格式中固有的正负表示对称性,使依赖此属性的算法实现复杂化或无效。例如,IEEE 浮点格式允许使用整数操作比较和排序浮点值。将最大值从 448 增加到 480 对 DL 的好处不足以证明偏离 IEEE 规范并失去依赖它的软件实现的合理性。
如前所述,E5M2 表示所有特殊值(无穷大、NaN 和零)与 IEEE 规范一致。我们广泛的实证研究(第 4 节)表明,5 位指数为 DL 提供了足够的每张量动态范围(32 个 binade,包括次正规值)。此外,减少特殊值表示对 E5M2 的好处比 E4M3 小得多——由于较小的尾数,仅增加三个幅度值,一个额外的 binade 在 E5M2 已经提供 32 个(与 E4M3 的 17 个相比)时影响要小得多。
指数偏差
E4M3 和 E5M2 都保留了类似 IEEE 的指数偏差:E4M3 为 7,E5M2 为 15。指数偏差控制可表示范围在实数线上的位置。当保持每张量缩放因子时,可以实现相同的效果。我们的实验表明,某些神经网络不能对给定类型的所有张量使用相同的指数偏差,需要每张量调整。第 4.3 节讨论了一个这样的例子。因此,我们选择不偏离 IEEE 的指数偏差规范。将每张量缩放留给软件实现,比可编程指数偏差方法提供了更大的灵活性——缩放因子可以采用任何实数值(通常以更高精度表示),而可编程偏差仅允许 2 的幂作为缩放因子。
4. 实证结果
训练实验使用模拟的 FP8 进行——张量值被裁剪为仅可在 FP8 中表示的值(包括缩放因子应用和饱和)。例如,在全连接层的矩阵乘法之前,传入的激活和权重张量都转换为 FP8 并返回到更宽的表示(FP16 或 bfloat16)。算术运算使用更宽的表示进行,原因有两个:交换格式是本文的重点,因为不同的处理器可能选择不同的向量和矩阵指令实现,不支持硬件的算术仿真对于大型模型的训练来说太慢。获得大型模型的结果是必要的,因为之前的研究已经确定了不同规模模型的不同数值行为(例如,[12] 中的 R18 和 R50)。
训练
在 FP8 训练实验中,我们保留了与更高精度基线训练会话相同的模型架构、权重初始化和优化器超参数。基线在 FP16 或 bfloat16 中训练,这些基线已被证明与单精度训练会话的结果相匹配 [14, 9]。在本研究中,我们专注于数学密集型操作的输入张量——卷积和矩阵乘法,我们将其称为 GEMM 操作,因为它们涉及点积计算。因此,除非另有说明,我们将激活、权重和激活梯度张量裁剪为 FP8 可表示的值,这些张量是 GEMM 的输入。输出张量保留在更高精度,因为它们通常由非 GEMM 操作(如非线性或归一化)消耗,并且在许多情况下与前面的 GEMM 操作融合。将更多张量移动到 FP8 是未来研究的主题。
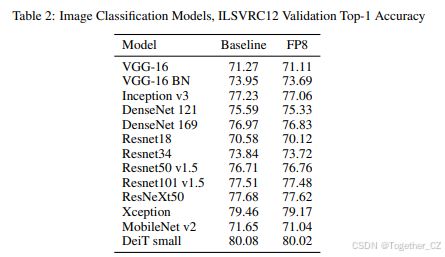
图像分类任务的结果列在表 2 中。所有网络都在 ImageNet ILSVRC12 数据集上训练,top-1 准确率在验证数据集上计算。所有 GEMM 操作的输入都被裁剪为 FP8,包括第一个卷积和最后一个全连接层,这些层在之前的研究 [12, 22] 中保留在更高精度。DeiT [21] 是基于 Transformer 的架构,其余模型是 CNN。除了 MobileNet v2,FP8 训练达到的准确率在更高精度训练的运行间变化范围内(当使用不同随机种子初始化训练会话时,观察到的准确率运行间变化)。我们继续努力恢复 MobileNet v2 的剩余准确率。
语言翻译
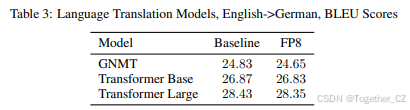
语言翻译任务使用 Transformer 和基于 LSTM 的循环 GNMT 神经网络进行测试。尽管基于 Transformer 的翻译模型在实践中已经取代了 RNN,但我们包括 GNMT 以更全面地覆盖模型架构类型,并作为其他仍使用循环网络的任务的代理。模型在 WMT 2016 英语->德语数据集上训练,使用 sacreBLEU 在 newstest2014 数据上评估(更高的 BLEU 分数更好)。FP8 训练模型的评估分数在基线训练会话的运行间变化范围内。
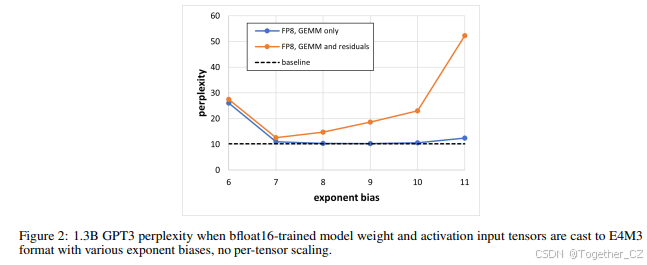
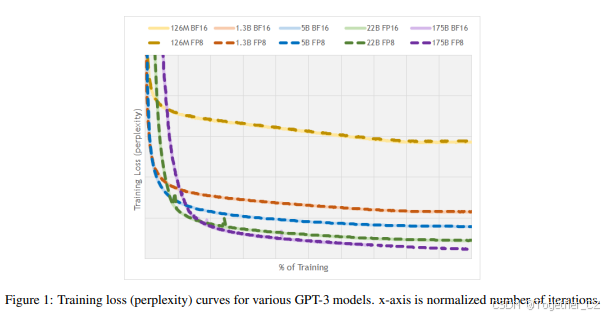
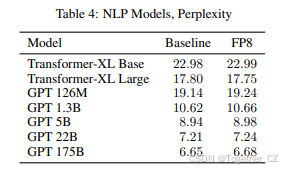
表 4 列出了各种语言模型的训练损失(困惑度,越低越好)。Transformer 模型在 Wikipedia 数据集上训练。GPT 模型在 The Pile 数据集 [6] 的变体上训练,并增加了 Common Crawl 和 Common Crawl 派生数据集,如 [18] 第 3 节所述。与图像网络一样,FP8 会话的训练结果在 16 位训练会话的运行间噪声范围内。请注意,1750 亿参数模型的困惑度在 75% 训练时报告,因为 bfloat16 基线运行尚未完成。FP8 训练会话已完成,其损失曲线与成功训练一致,如图 1 所示。与视觉和语言翻译模型一样,我们得出结论,FP8 训练结果与 16 位训练会话的结果相匹配。
推理
FP8 训练大大简化了 8 位推理部署,因为推理和训练使用相同的数据类型。这与使用 32 位或 16 位浮点训练的网络进行 int8 推理形成对比,后者需要训练后量化(PTQ)校准,有时还需要量化感知训练(QAT)以保持模型准确性。此外,即使使用量化感知训练,某些 int8 量化模型也可能无法完全恢复浮点实现的准确性 [1]。
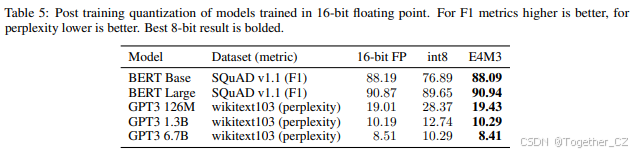
我们评估了使用 16 位浮点训练的模型的 FP8 训练后量化。表 5 列出了 FP16 训练模型量化为 int8 或 E4M3 进行推理的推理准确性。两种量化都使用每通道缩放因子进行权重,每张量缩放因子进行激活,这是 int8 固定点的常见做法。所有矩阵乘法操作的输入张量(包括注意力批量矩阵乘法)都被量化。权重使用最大校准(选择缩放因子以使张量中的最大幅度被表示),激活张量使用从最大、百分位和 MSE 方法中选择的最佳校准进行校准。BERT 语言模型在斯坦福问答数据集上的评估显示,FP8 PTQ 保持了准确性,而 int8 PTQ 导致模型准确性显著下降。我们还尝试在不应用缩放因子的情况下将张量转换为 FP8,这导致准确性显著下降,困惑度增加到 11.0。GPT 模型在 wikitext103 数据集上的评估显示,FP8 PTQ 在保持模型准确性方面比 int8 好得多。
每张量缩放因子
虽然许多网络的训练和推理可以成功地在 FP8 中使用相同类型的张量的相同缩放因子进行(换句话说,选择单个指数偏差是可能的),但在某些情况下需要每张量缩放因子以保持准确性。当我们将更多张量存储在 FP8 中,而不仅仅是 GEMM 操作的输入时,这种需求变得更加明显。图 2 显示了在 wikitext103 数据集上测量的 FP8 推理困惑度,当使用 bfloat16 训练网络的训练后量化时。未进行校准,权重和激活张量从 bfloat16 转换为 E4M3 类型,并具有相应的指数偏差。正如我们所看到的,当仅将 GEMM 操作的输入(包括加权 GEMM 以及仅涉及激活的两个注意力批量矩阵乘法)转换为 FP8 时,在 [7,10] 范围内的几个指数偏差选择导致结果与 bfloat16 基线匹配。然而,如果我们还将残差连接(Add 操作的输入张量,进一步减少存储和内存带宽的压力)量化为 FP8,则没有单个指数偏差值能够达到足够的准确性——即使指数偏差为 7,困惑度为 12.59,显著高于(更差)bfloat16 基线的 10.19。然而,如果我们改为校准张量以具有自己的缩放因子(遵循 int8 量化的惯例,对权重使用每通道缩放因子,对激活使用每张量缩放因子 [23]),我们实现了 GEMM-only 和 GEMM+residuals FP8 推理的 10.29 和 10.44 困惑度。
5. 结论
在本文中,我们提出了一种 FP8 二进制交换格式,由 E4M3 和 E5M2 编码组成。通过最小化偏离 IEEE-754 浮点值二进制编码规范,我们确保软件实现可以继续依赖 IEEE FP 属性,如使用整数操作比较和排序值的能力。该格式的主要动机是通过启用更小、更节能的数学管道以及减少内存带宽压力来加速深度学习训练和推理。我们展示了各种图像和语言任务的神经网络模型可以在 FP8 中训练,以匹配使用 16 位训练会话实现的模型准确性,使用相同的模型、优化器和训练超参数。使用 FP8 不仅加速并减少了训练所需的资源,还通过使用相同的数据类型进行训练和推理简化了 8 位推理部署。在 FP8 之前,8 位推理需要对使用浮点训练的 int8 模型进行校准或微调,这增加了部署过程的复杂性,并且在某些情况下未能保持准确性。



















 9800
9800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











