






这篇文章提出了一种名为 NoProp(No Propagation)的新型神经网络训练方法,该方法不依赖于传统的前向传播或反向传播,而是基于去噪得分匹配(denoising score matching)和扩散模型(diffusion models)的思想,使每一层独立学习对噪声目标进行去噪。研究的核心目标是探索一种无梯度的学习方法,以克服传统反向传播方法在生物学合理性、内存开销和并行计算效率等方面的局限性。
主要研究内容
-
NoProp 方法的核心思想
NoProp 方法的核心是将每一层的训练目标设定为从噪声标签中恢复出真实的标签。具体来说,每一层接收输入图像和前一层产生的噪声标签,通过一个去噪过程逐步接近真实标签。这种方法避免了传统的前向和反向传播,直接在每一层上独立进行训练。 -
离散时间和连续时间的实现
-
离散时间扩散模型(NoProp-DT):通过固定的时间步数 T,每一层独立学习去噪过程。在训练时,每一层的目标是最小化其去噪输出与真实标签嵌入之间的差异。
-
连续时间扩散模型(NoProp-CT):将时间步数 T 趋向于无穷大,通过连续时间的扩散过程来学习。这种方法允许更灵活的时间步采样,提高了训练效率。
-
流匹配方法(NoProp-FM):通过学习一个连续的向量场,直接将噪声映射到标签嵌入,进一步提高了模型的灵活性和效率。
-
-
实验验证
-
数据集:在 MNIST、CIFAR-10 和 CIFAR-100 数据集上进行了广泛的实验。
-
性能对比:NoProp 方法在这些基准测试中表现出色,显著优于其他无反向传播方法,如前向-前向算法、差异目标传播等。具体来说:
-
NoProp-DT 在 MNIST 上达到了 99.47% 的准确率,在 CIFAR-10 上达到了 80.54% 的准确率,在 CIFAR-100 上达到了 46.06% 的准确率。
-
NoProp-CT 和 NoProp-FM 在连续时间设置中也表现出色,尽管在 CIFAR-100 上的 one-hot 嵌入情况下 NoProp-FM 的表现稍差,但通过联合学习标签嵌入,其性能得到了显著提升。
-
-
计算效率:NoProp 方法在训练时的 GPU 内存消耗显著低于传统的反向传播方法,例如在 CIFAR-100 上,NoProp-DT 的内存消耗仅为 1.23 GB,而传统的反向传播方法需要 1.73 GB。
-
-
创新点和贡献
-
提出了一种全新的无梯度学习方法,不依赖于传统的前向或反向传播。
-
通过去噪得分匹配和扩散模型的思想,使每一层能够独立学习,提高了训练的灵活性和效率。
-
在多个图像分类基准测试中验证了该方法的有效性,证明了其在准确率和计算效率方面的优势。
-
为无反向传播训练深度学习模型提供了新的视角,可能对分布式学习和其他学习特性产生深远影响。
-
NoProp 方法通过去噪得分匹配和扩散模型的思想,成功地实现了一种无需前向和反向传播的神经网络训练方法。该方法在多个基准测试中表现出色,不仅在准确率上优于其他无反向传播方法,还在计算效率上具有显著优势。这项工作为无梯度学习方法的研究提供了新的方向,并可能对深度学习的未来发展方向产生重要影响。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
传统的深度学习训练方法依赖于反向传播,通过从输出层向每个可学习参数反向传播误差信号来计算每一层的梯度项。由于神经网络的堆叠结构,每一层都在其下一层的表示基础上构建,从而形成层次化的表示。更抽象的特征位于模型的顶层,而底层的特征则相对不那么抽象。与之相对,我们提出了一种新的学习方法——NoProp,它不依赖于前向传播或反向传播。相反,NoProp 从扩散和流匹配方法中汲取灵感,每一层独立地学习对噪声目标进行去噪。我们相信这项工作迈出了引入一种新的无梯度学习方法的第一步,这种方法并不学习层次化的表示——至少不是通常意义上的。NoProp 需要事先将每一层的表示固定为目标的噪声版本,学习一个局部去噪过程,然后在推理时加以利用。我们在 MNIST、CIFAR-10 和 CIFAR-100 图像分类基准测试中验证了该方法的有效性。结果表明,NoProp 是一种可行的学习算法,其准确率优于其他现有的无反向传播方法,使用起来更简单,计算效率也更高。通过脱离传统的基于梯度的学习范式,NoProp 改变了网络内部的信用分配方式,使得分布式学习更加高效,并可能对学习过程的其他特性产生影响。
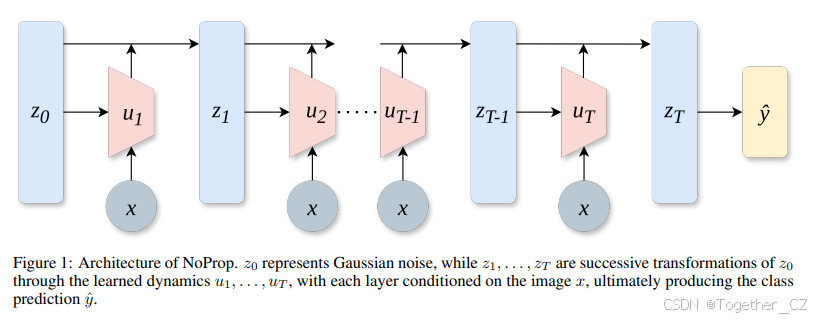
1 引言
反向传播(Rumelhart et al., 1986)长期以来一直是深度学习的基石,其应用使得深度学习技术在从科学到工业的各个领域都取得了显著的成功。简而言之,反向传播是一种迭代算法,它在每一步调整多层神经网络的参数,使其输出更接近期望的目标。反向传播的每一步首先将输入信号进行前向传播以生成预测,然后将预测与期望目标进行比较,最后将误差信号反向传播回网络,以确定每一层的权重应如何调整以减小误差。通过这种方式,每一层可以被看作是在学习如何将其从下一层接收到的表示改变为后续层可以用来进行更好预测的表示。反向传播的误差信号用于信用分配,即决定每个参数需要改变多少以最小化误差。
反向传播的简单性使其成为训练神经网络的默认方法。然而,多年来,人们一直对开发不依赖反向传播的替代方法感兴趣。这种兴趣源于几个因素。首先,反向传播在生物学上是不可行的,因为它需要在前向和反向传播之间进行同步交替(例如 Lee et al., 2015)。其次,反向传播需要在前向传播过程中存储中间激活值,以便在反向传播过程中计算梯度,这可能会带来显著的内存开销(Rumelhart et al., 1986)。最后,梯度的顺序传播引入了依赖性,阻碍了并行计算,使得在大规模机器学习中难以有效利用多个设备和服务器(Carreira-Perpinan & Wang, 2014)。这种信用分配的顺序计算方式还对学习产生了额外的影响,导致了干扰(Schaul et al., 2019)并在灾难性遗忘中发挥了作用(Hadsell et al., 2020)。
反向传播的替代优化方法包括无梯度方法(例如直接搜索方法(Fermi, 1952; Torczon, 1991)和基于模型的方法(Bortz & Kelley, 1997; Conn et al., 2000)),零阶梯度方法(Flaxman et al., 2004; Duchi et al., 2015; Nesterov & Spokoiny, 2015; Liu et al., 2020; Ren et al., 2022),这些方法使用有限差分来近似梯度,进化策略(Wierstra et al., 2014; Salimans et al., 2017; Such et al., 2017; Khadka & Tumer, 2018),以及依赖于局部损失的方法,如差异目标传播(Lee et al., 2015)和前向-前向算法(Hinton, 2022)。然而,由于这些方法在准确性、计算效率、可靠性和可扩展性方面的限制,它们并未被广泛用于训练神经网络。
在本文中,我们提出了一种无反向传播的训练方法。该方法基于扩散模型(Sohl-Dickstein et al., 2015; Chen et al., 2018; Ho et al., 2020; Song et al., 2021)背后的去噪得分匹配方法,使得神经网络的每一层都可以独立训练。具体来说,在训练时,每一层都被训练为在给定噪声标签和训练输入的情况下预测目标标签,而在推理时,每一层则取前一层产生的噪声标签,并通过向其预测的标签方向迈出一步来进行去噪。特别值得注意的是,该方法在训练时甚至不需要前向传播,因此我们将其称为 NoProp。我们在 MNIST、CIFAR-10 和 CIFAR-100 基准测试中进行了实验,结果表明 NoProp 显著优于之前的无反向传播方法,同时更加简单、稳健和计算高效。
2 方法论
在本节中,我们将描述 NoProp 方法,用于无反向传播的学习。尽管技术思想与变分扩散模型(Sohl-Dickstein et al., 2015; Kingma et al., 2021; Gulrajani & Hashimoto, 2024)密切相关,但我们在不同的上下文中应用它们,并对其进行不同的解释。
2.1 NoProp




2.2 变体
2.2.1 固定和可学习的 WEmbed
类别嵌入矩阵 WEmbed 可以是固定的,也可以与模型一起学习。在固定的情况下,我们将 WEmbed 设置为单位矩阵,其中每个类别嵌入是一个 one-hot 向量。在学习的情况下,如果可能的话,WEmbed 被初始化为一个正交矩阵,否则随机初始化。当嵌入维度与图像维度匹配时,我们将其解释为学习一个“图像原型”。在这种特殊情况下,类别嵌入被初始化为同一类别中与其他图像距离中位数最小的图像,作为训练前的粗略原型。
2.2.2 连续时间扩散模型和神经常微分方程

神经常微分方程的训练通常依赖于通过 ODE 求解器反向传播以优化特定于任务的损失函数(例如分类中的交叉熵),或者使用伴随灵敏度方法(Chen et al., 2018),它通过求解另一个反向时间的 ODE 来估计梯度。连续时间扩散模型则学习一个 ODE 动力学,以反转一个预定义的噪声过程。训练通过独立采样时间步进行,而不需要通过时间进行完整的前向或反向传播。这使得训练更加高效,同时仍然能够实现富有表现力的 ODE 动力学。
2.2.3 流匹配


2.3 实现细节
2.3.1 架构

2.3.2 训练过程


噪声时间表:对于离散时间扩散,我们使用一个固定的余弦噪声时间表。对于连续时间扩散,我们与模型一起联合训练噪声时间表。关于可训练噪声时间表的进一步细节在附录 B 中提供。
3 相关工作
3.1 无反向传播方法
前向-前向算法(Hinton, 2022)用两个前向传递取代了传统的前向和反向传递,用于图像分类:一个使用与正确标签配对的图像,另一个使用与错误标签配对的图像。
目标传播及其变体(例如 Lee et al., 2015; Lillicrap et al., 2016)通过学习从输出层到隐藏层的逆映射来工作,为权重更新产生局部目标,无需反向传播。然而,它们的性能严重依赖于所学习的逆映射的质量,自编码器中的不准确之处可能导致次优更新,限制了它们在深度网络中的有效性。
零阶方法(Flaxman et al., 2004; Duchi et al., 2015; Ren et al., 2022)是一类广泛的算法,它们在没有明确微分的情况下估计梯度,使其适用于黑箱和非可微函数。
进化策略(Wierstra et al., 2014; Salimans et al., 2017; Khadka & Tumer, 2018)受到自然进化的启发,通过使用基于种群的优化方法,用随机噪声扰动参数,并在奖励更高的方向上进行更新。然而,它们需要大量的函数评估,导致样本复杂度高,对于高维参数空间,有效的探索仍然是一个关键挑战。
3.2 扩散和流匹配
一些与扩散和流匹配密切相关的工作与我们的方法有关。Han et al. (2022) 引入了分类和回归扩散模型,Kim et al. (2025) 提出了用于配对数据的流匹配,Hu et al. (2024) 将流匹配应用于条件文本生成。相比之下,我们的论文在无反向传播学习的框架内探讨了这些想法的含义。
3.3 表示学习
一般来说,大多数替代反向传播的方法,无论是简单地以不同的方式近似梯度,还是利用不同的搜索方案(如进化策略的情况)——仍然依赖于学习相互构建的中间表示(Bengio et al., 2013)。这使得模型能够在更深的层中学习更抽象的表示,并被认为对深度学习和表示认知过程至关重要(Markman & Dietrich, 2000)。事实上,深度学习的早期成功被归因于训练深度架构以学习层次化表示的能力(Hinton et al., 2006; Bengio et al., 2013),而早期的可解释性工作则集中在可视化这些越来越复杂的特征上(Zeiler & Fergus, 2014; Lee et al., 2009)。
通过让每一层学习对标签进行去噪,标签噪声分布由用户选择,我们可以认为 NoProp 不学习表示。相反,它依赖于用户设计的表示(具体来说,中间层的表示是目标标签的高斯噪声嵌入,用于扩散,以及高斯噪声和目标标签嵌入之间的插值,用于流匹配)。这也许并不令人惊讶:前向和反向传播可以被理解为信息在神经网络层之间的传播,以便使每一层的表示能够“适应”相邻层的表示,从而可以从最后一层的表示中轻松预测目标标签。因此,为了使 NoProp 在没有前向或反向传播的情况下工作,这些层的表示必须事先固定,即由用户设计。
NoProp 在没有表示学习的情况下取得良好性能的事实引发了关于表示学习是否实际上是深度学习所必需的问题,以及是否通过设计表示,我们可以启用具有不同特性的替代深度学习方法。具体来说,注意 NoProp 中固定的表示并不是人们可能认为的更抽象的表示在后面的层中,这为重新审视层次化表示在建模复杂行为中的作用打开了大门(Markman & Dietrich, 2000)。随着反向传播基础学习的核心假设,如独立同分布假设以及信息和误差信号通过网络的顺序传播,被证明是有限制的,这些问题可能变得越来越重要。
4 实验
我们在图像分类任务中将 NoProp 与离散时间情况下的反向传播进行了比较,并在连续时间情况下与伴随灵敏度方法(Chen et al., 2018)进行了比较。关于超参数的详细信息在附录中的表 3 中提供。
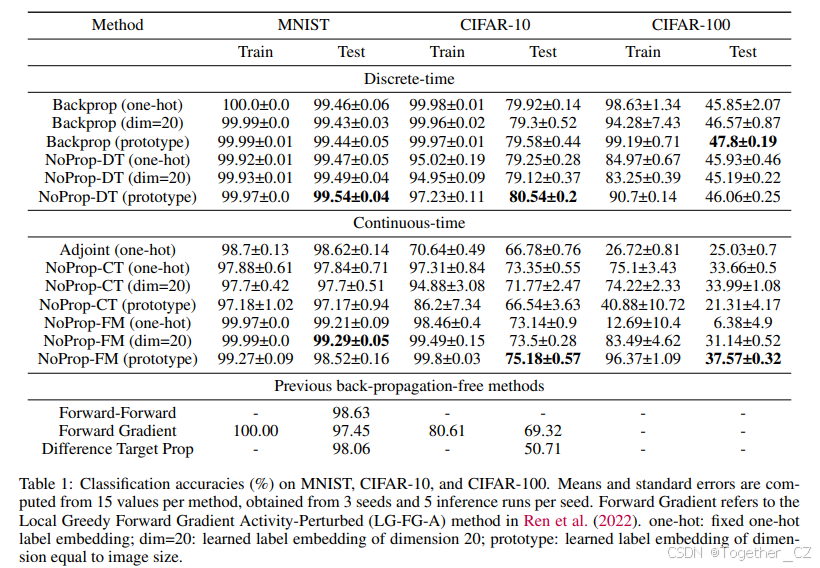
数据集
我们使用了三个基准数据集:MNIST、CIFAR-10 和 CIFAR-100。MNIST 数据集包含 70,000 张 28x28 像素的手写数字灰度图像,涵盖 10 个类别(数字 0-9)。CIFAR-10 包含 60,000 张 32x32 像素的彩色图像,分为 10 个不同的目标类别。CIFAR-100 与 CIFAR-10 结构相似,包含 60,000 张彩色图像,但分为 100 个细粒度类别。我们使用标准的训练/测试集划分。在我们的实验中,我们没有对这些数据集应用任何数据增强技术。
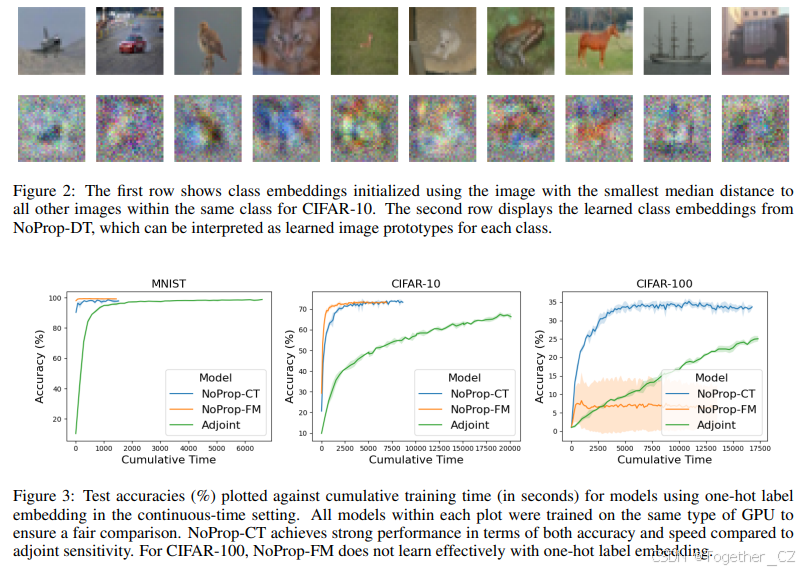
NoProp(离散时间)


主要结果
我们的结果总结在表 1 中,表明 NoProp-DT 在离散时间设置中实现了与反向传播相当或更好的性能,同时在 MNIST、CIFAR-10 和 CIFAR-100 上优于以前的无反向传播方法。此外,NoProp 在训练时的 GPU 内存消耗减少,如表 2 所示。为了说明学习到的类别嵌入,图 2 分别可视化了 CIFAR-10 的初始化和 NoProp-DT 学习到的最终类别嵌入,其中嵌入维度与图像维度匹配。
在连续设置中,NoProp-CT 和 NoProp-FM 的准确度低于 NoProp-DT,这可能是由于额外的时间 t 的条件。然而,它们通常在 CIFAR-10 和 CIFAR-100 上优于伴随灵敏度方法,无论是在准确度还是计算效率方面。尽管伴随方法在 MNIST 上实现了与 NoProp-CT 和 NoProp-FM 相似的准确度,但它完成的速度要慢得多,如图 3 所示。
对于 CIFAR-100 与 one-hot 嵌入,NoProp-FM 未能有效学习,导致准确度提高非常缓慢。相比之下,NoProp-CT 仍然优于伴随方法。然而,一旦标签嵌入是联合学习的,NoProp-FM 的性能显著提高。
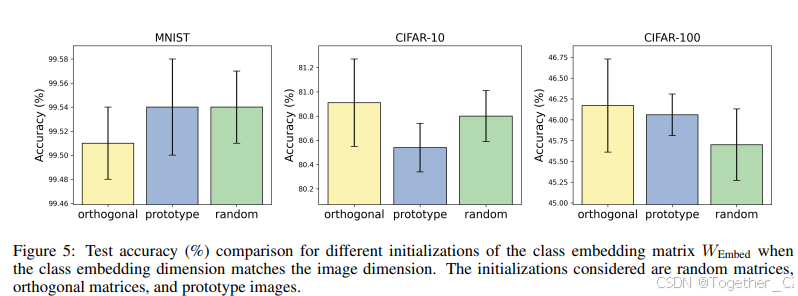
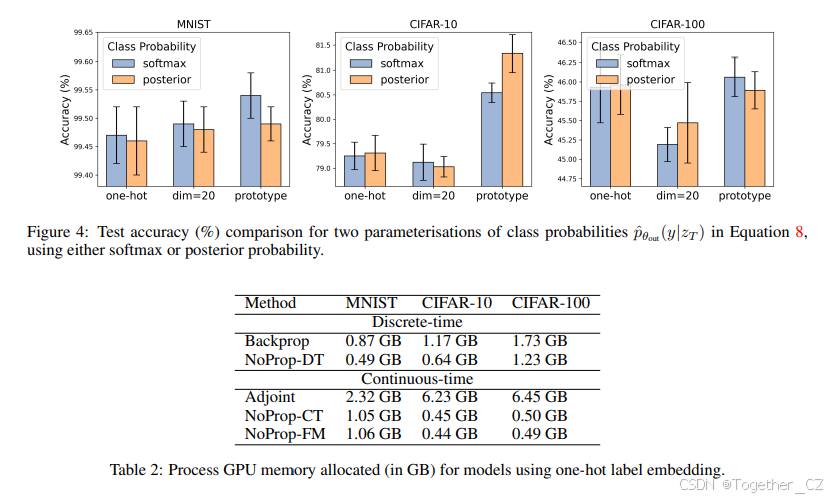
我们还在类别概率参数化 ![]() 和类别嵌入矩阵 WEmbed 的初始化方面进行了消融研究,结果分别如图 4 和图 5 所示。消融结果揭示了在类别概率参数化之间没有一致的优势,性能在不同数据集之间有所不同。对于类别嵌入初始化,正交和原型初始化通常与随机初始化相当或优于随机初始化。
和类别嵌入矩阵 WEmbed 的初始化方面进行了消融研究,结果分别如图 4 和图 5 所示。消融结果揭示了在类别概率参数化之间没有一致的优势,性能在不同数据集之间有所不同。对于类别嵌入初始化,正交和原型初始化通常与随机初始化相当或优于随机初始化。
5 结论
使用扩散模型背后的去噪得分匹配方法,我们提出了 NoProp,这是一种无需前向和反向传播的神经网络训练方法。该方法使神经网络的每一层都能够独立训练,以在给定噪声标签和训练输入的情况下预测目标标签,而在推理时,每一层则取前一层产生的噪声标签,并通过向其预测的标签方向迈出一步来进行去噪。我们通过实验表明,NoProp 显著优于以前的无反向传播方法,同时更加简单、稳健和计算高效。我们相信,通过去噪得分匹配训练神经网络的这种视角为无需反向传播训练深度学习模型开辟了新的可能性,我们希望我们的工作能够激发这一方向的进一步研究



















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











