







基本信息
标题:ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
简称:ESRGAN
时间:2018年初版,1 Sep 2018, ECCV2018 PIRM Workshop
作者:Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Chen Change Loy, Yu Qiao, Xiaoou Tang; CUHK-SenseTime Joint Lab, SIAT-SenseTime Joint Lab, The Chinese University of Hong Kong, Nanyang Technological University
论文:https://arxiv.org/abs/1809.00219
代码:https://github.com/xinntao/ESRGAN
主题内容
方法:
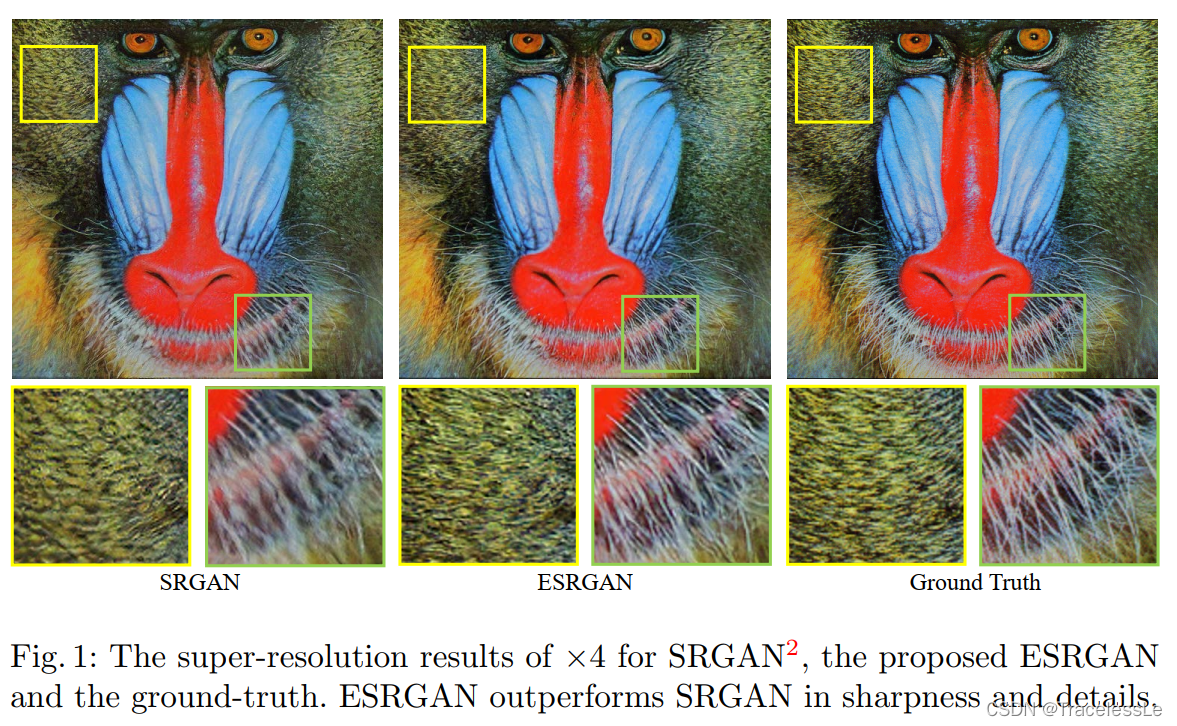
ESRGAN是基于SRGAN做出一系列的改进得到的,全称是Enhanced SRGAN。主要改进有以下几点:
(1)对于网络结构,①提出了Residual-in-Residual Dense Block(RDDB)结构,提升了网络容量,使得训练更容易。②去除了网络中的BN层,使用residual scaling和smaller initialization,能够促进训练一个非常深的网络。
(2)优化判别器,使用Relativistic average GAN(RaGAN),能够学习“一张图是否比其他图更真实”,而不仅仅是“一张图是真还是假”。实验表明这个改进能够帮助生成器恢复更多的真实纹理细节。
(3)不再像SRGAN一样使用那些激活层后的VGG特征来计算感知损失,而是使用激活层前的特征来计算。实验发现该改动能够提供更多sharper edges和更视觉效果好的结果。
(4)其他:为了平衡 visual quality 和 RMSE/PSNR,论文提出使用网络插值策略,能够得到连续性的重建风格和光滑程度。同时和常用的图像插值方式做了对比。网路插值方法其实就是训练一个PSNR指标导向的网络G_PSNR,然后微调出一个GAN-based网络G_GAN。对两个模型的参数进行插值:
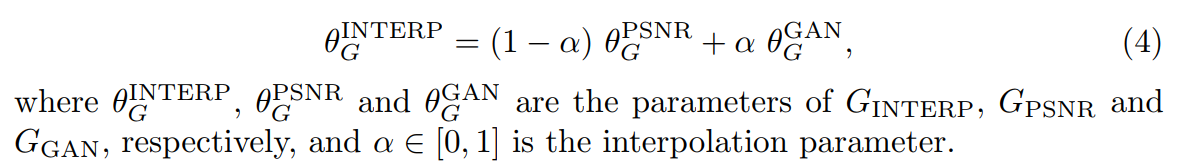
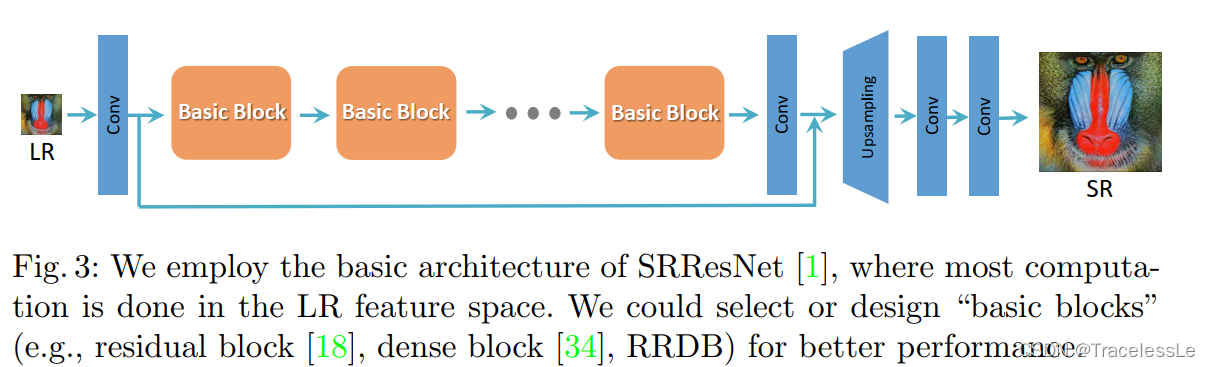
网络结构:
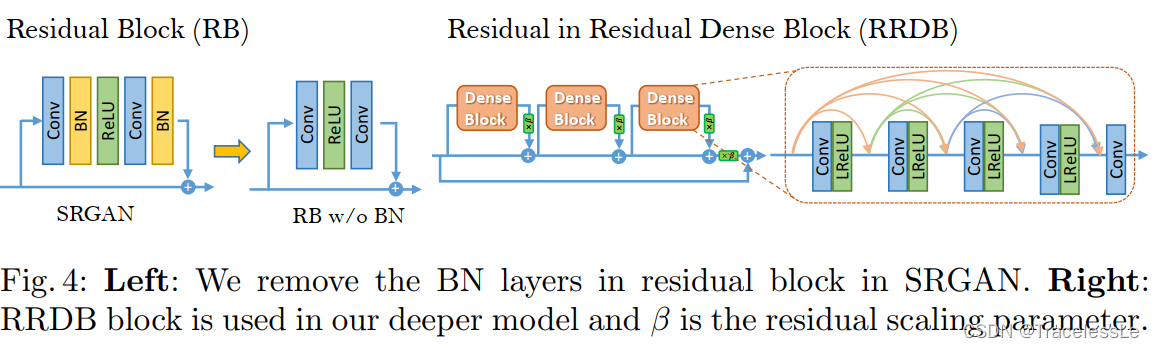
ESRGAN基于SRGAN的基础上,做出两大改动,其一是移除所有的BN层,其二是将原始的RB替换成RRDB。其次还是用了residual scaling和smaller initialization两个策略。
损失函数设计:
(1)将标准判别器替换为Relativistic average Discriminator RaD,标记为D_Ra。
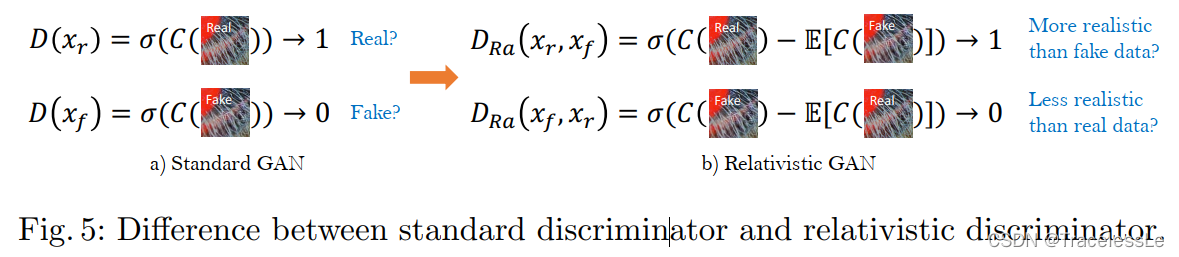
SRGAN中使用的标准判别器:
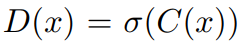
ESRGAN中使用的RaD:
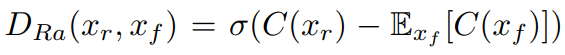
其中
E
x
f
[
⋅
]
\Bbb{E}_{x_f}[·]
Exf[⋅]表示使用小批量中的所有假数据的均值。
判别器损失函数:
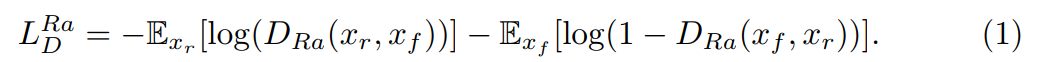
生成器的对抗损失(与判别器是对称形式):
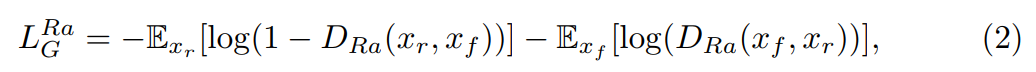
其中 x f = G ( x i ) x_f = G(x_i) xf=G(xi), x i x_i xi是输入的LR图。
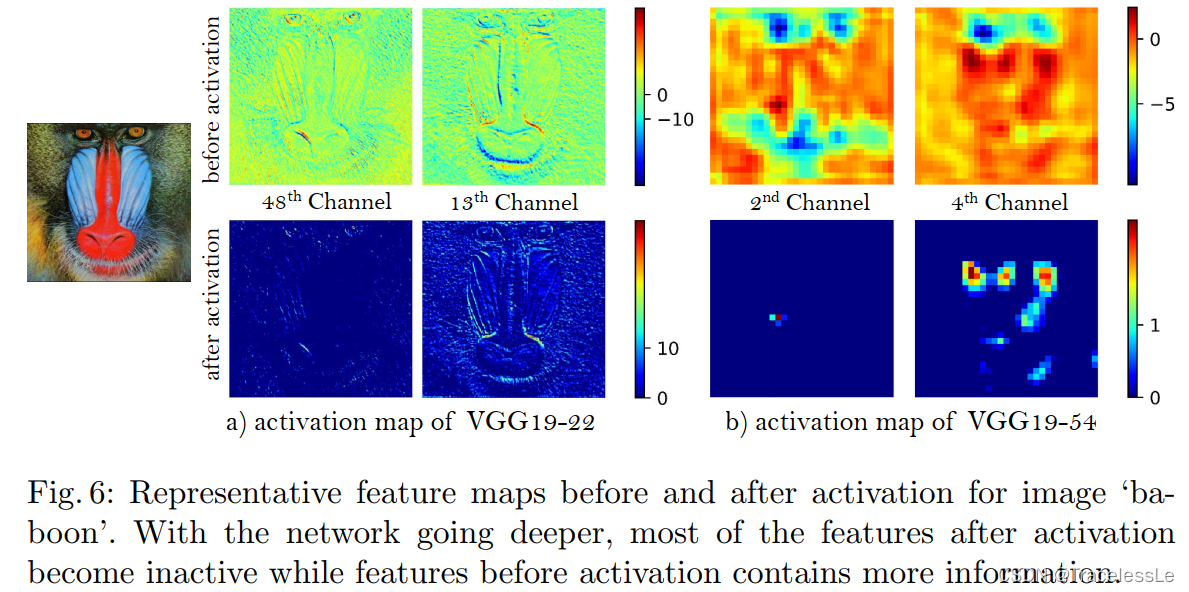
(2)感知损失 Perceptual Loss
论文发现使用SRGAN中的激活层后的VGG特征来计算感知损失,会有两个问题:
①激活层后的特征比较稀疏,只能提供弱监督,会导致较差的表现。
②会造成与GT不一致的重构光照。
(3)总损失函数
生成器的总损失函数:
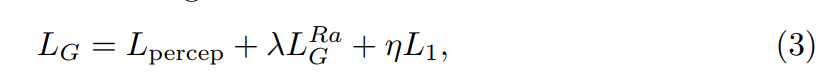
其中 L 1 = E x i ∣ ∣ G ( x i ) − y ∣ ∣ 1 L_1=\Bbb{E_{x_i}}||G(x_i)-y||_1 L1=Exi∣∣G(xi)−y∣∣1是content loss,用于评估恢复图 G ( x i ) G(x_i) G(xi)与GT之间的1范式距离。 λ , η \lambda,\eta λ,η是平衡不同损失函数的系数。
训练细节:
(1)通过使用MATLAB的bicubic核方法对HR进行下采样得到LR。小批量尺寸设置为16,裁剪得到的HR patch尺寸为128*128。
(2)训练分为两个阶段,第一阶段先用L1 loss训练一个PSNR导向的模型,学习率初始化为2e-4,衰减系数为每2e5个mini-batch折半。第二阶段使用得到的模型作为初始化的生成器,使用式(3)中的损失函数进行微调,权重 λ = 5 ∗ 1 0 − 3 , η = 1 ∗ 1 0 − 2 \lambda=5*10^{-3}, \eta=1*10^{-2} λ=5∗10−3,η=1∗10−2,学习率设为1e-4,在[50k, 100k, 200k, 300k] 迭代数处学习率折半。
分阶段训练的好处在于①能够避免生成器陷入局部最优,②通过预训练,判别器能够在每次开始时得到相对好的图而不是极端假的图。
(3)使用
β
1
=
0.9
,
β
2
=
0.999
\beta_1=0.9, \beta_2=0.999
β1=0.9,β2=0.999的Adam。使用23个RRDB模块。
(4)使用PyTorch框架,使用NVIDIA Titan Xp GPUs。
(5)数据使用DIV2K数据集、Flickr2K数据集、 OutdoorSceneTraining (OST)数据集。实验表明使用过拥有更多纹理的更大的数据集,能够使生成器生成更自然的结果。数据增强方案有随机水平翻转和90度旋转。评估数据集选用Set5、Set14、BSD100、Urban100、PIRM自验证集。
评估标准:
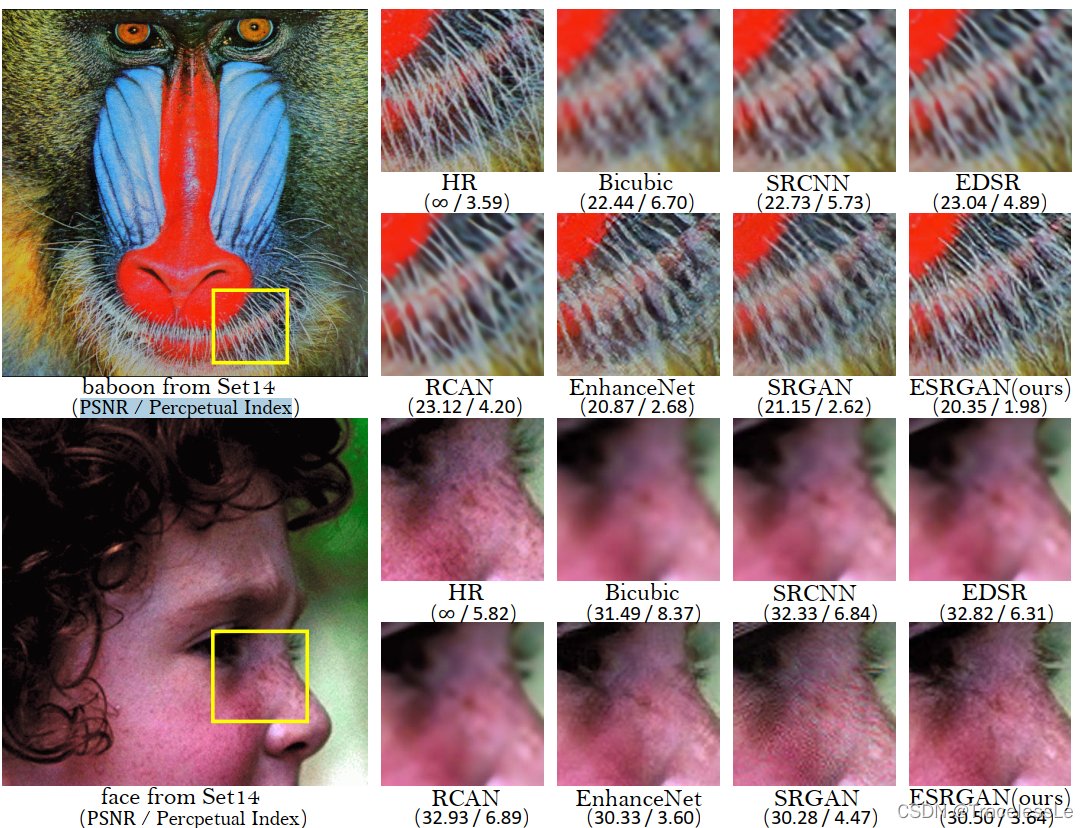
(1)PSNR
(2)Percpetual Index
亮点:
(1)移除BN层
(2)设计得到RDDB模块
(3)使用relativistic GAN作为判别器
(4)使用residual scaling和smaller initialization策略
(5)修改感知损失计算方法,使用激活层前特征计算
(5)网络插值
应用场景:
未提及
不足:
未提及
其他补充:
(1) PIRM-SR Challenge比赛中用到的评估标准perceptual quality(感知质量)是non-reference measures of Ma’s score and NIQE,
例如perceptual index = 12((10-Ma)+NIQE),更低的perceptual index代表更好的感知质量。
(2) 感知损失提出是为了通过最小化特征空间而非像素空间的误差来增强视觉质量的。
(3) 失真度量PSNR和SSIM本质上与人眼主观感觉不一致。
(4) BN层在训练时使用一个batch的均值和方差对特征进行归一化,在测试时使用整个训练集上得到的均值和方差进行计算。当训练集和测试集在统计特性上有很大出入时,BN层将引入瑕疵并限制泛化能力。
版权说明
本文为原创文章,独家发布在blog.csdn.net/TracelessLe。未经个人允许不得转载。如需帮助请email至tracelessle@163.com。

参考资料
[1] 论文《ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks》
[2] 代码 ESRGAN

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











