






kaggle的数据集
要求:
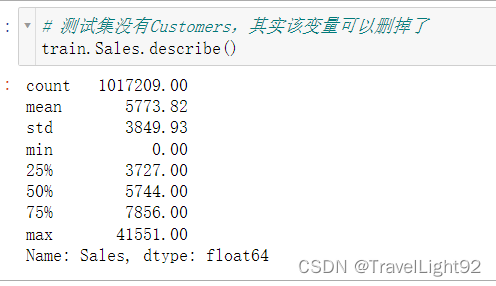
给了我们一个train,一个store数据集,同时要我们预测test数据集,即未来6周旗下1115个门店销售数据,注意test没有给我们顾客人数;
以前搞过的kaggle数据集,现在重写一遍,虽然数据集有点老了,但kaggle上面还是看到有人不停更新充分,不过高分的,都是加了天气、趋势、地理信息等额外数据集进去了,为了冲分果然方法层出不穷,同时不得不承认国外对一些信息获取的优势,本文在不额外添加数据集的情况下,逐步演示探索的步骤以及思考;
特色:
算法上面没什么亮点,主要在1.特征的新增 2.特征处理变换 3.逐步摸索的过程,即是没接触过这个数据,看完应该也基本懂了,堪称"手把手";
缺陷:很多代码直接截的图,发文快,感觉图片更能反映思想,而且注释较多,应该可以看吧,源码百度网盘链接在最下面:。
结论:
1.预测集里没有顾客数,而这个数值非常关键,导致我们只能想方设法"增加"特征列
2.金额列分布右偏,平滑对分数影响较大,在没怎么调参,随便写点参数的情况下,不平滑大约0.34的误差 ,平滑了就0.12左右,差距很大;
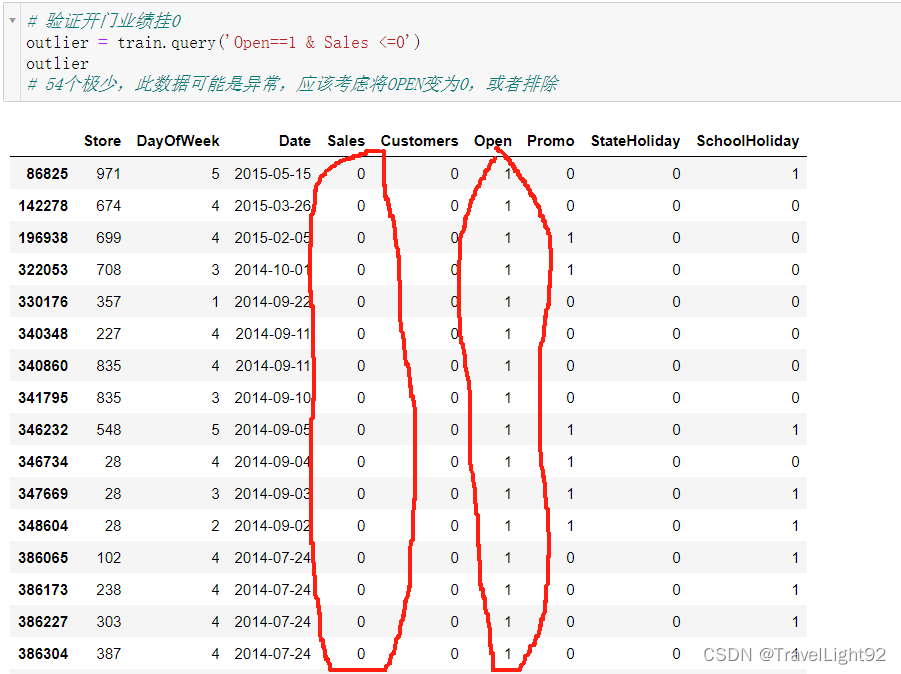
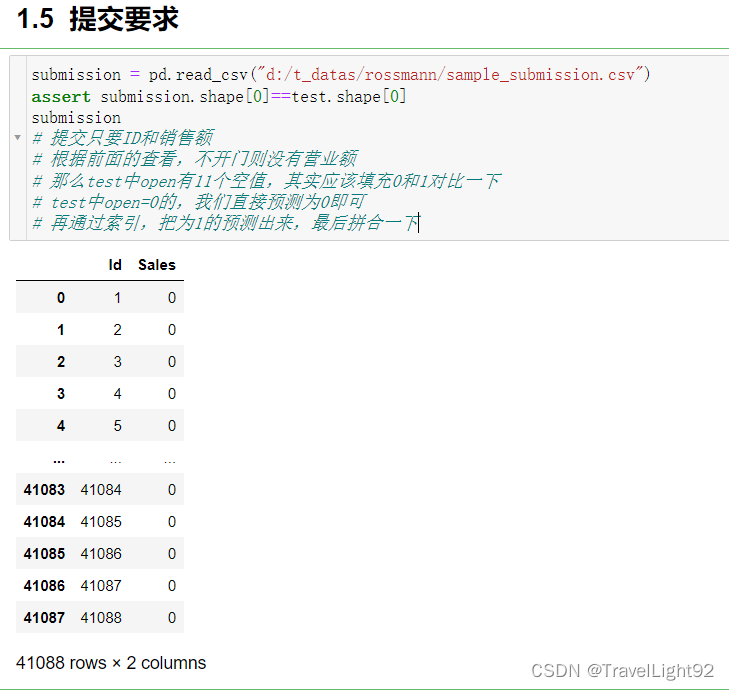
3.test中有11个open为空的,实际测试了一番,填充0和1都一样,但应该填充为0,估计是排除了该数值的影响,因为要除以实际销售额,除0就有问题,故排除了,如下图

一、数据认识和看一看
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error
import time
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
from datetime import datetime
from random import choice
import xgboost as xgb
import time
from xgboost import XGBRegressor
import scipy.stats as st
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV
import lightgbm as lgb
import os train = pd.read_csv("d:/t_datas/rossmann/train.csv"
, dtype={'StateHoliday': np.string_}
)
test = pd.read_csv("d:/t_datas/rossmann/test.csv"
# , dtype={'StateHoliday': np.string_}
)
store = pd.read_csv("d:/t_datas/rossmann/store.csv")1.1 警告处理
train的StateHoliday有个int 0和字符串0,会报个警告,添加这个即可解决,dtype={'StateHoliday': np.string_}
1.2 train、test查看
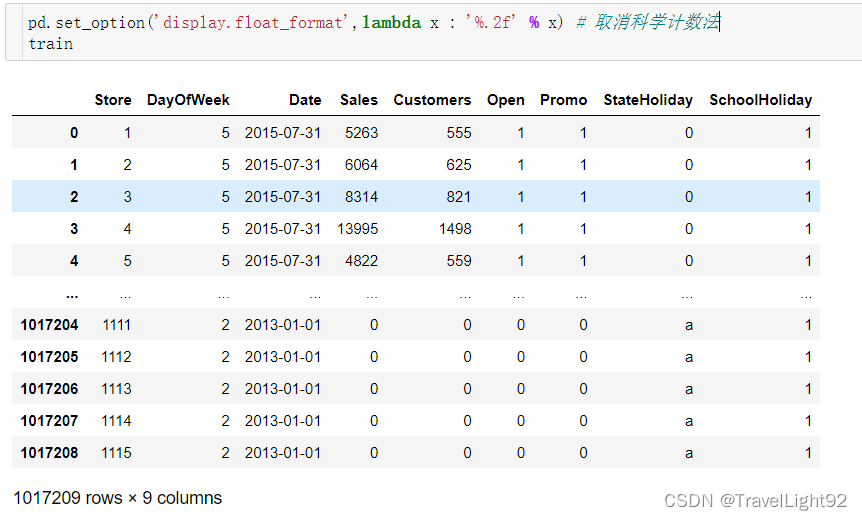
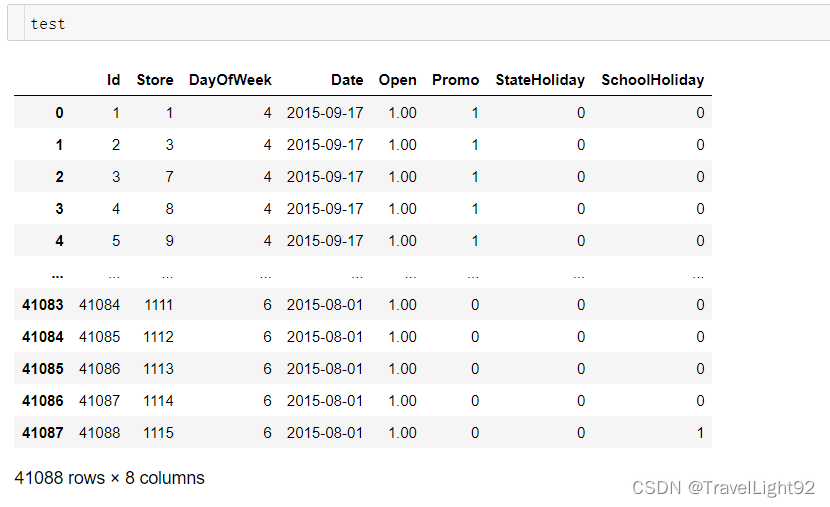
可以看到test少一个Customers和Sales,多了一列ID列;
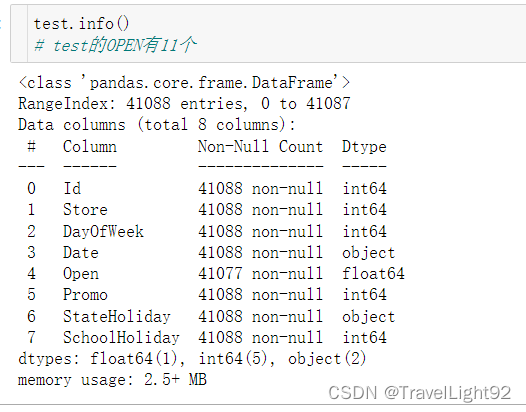
1.2.1 空值初步查看
train没有空值比较好

test有11个空值,待会看看
1.2.2 Open

# 看看每周星期几的开关门情况
sns.countplot(x = 'DayOfWeek', hue = 'Open', data = train)
plt.title('Store Daily Open Countplot')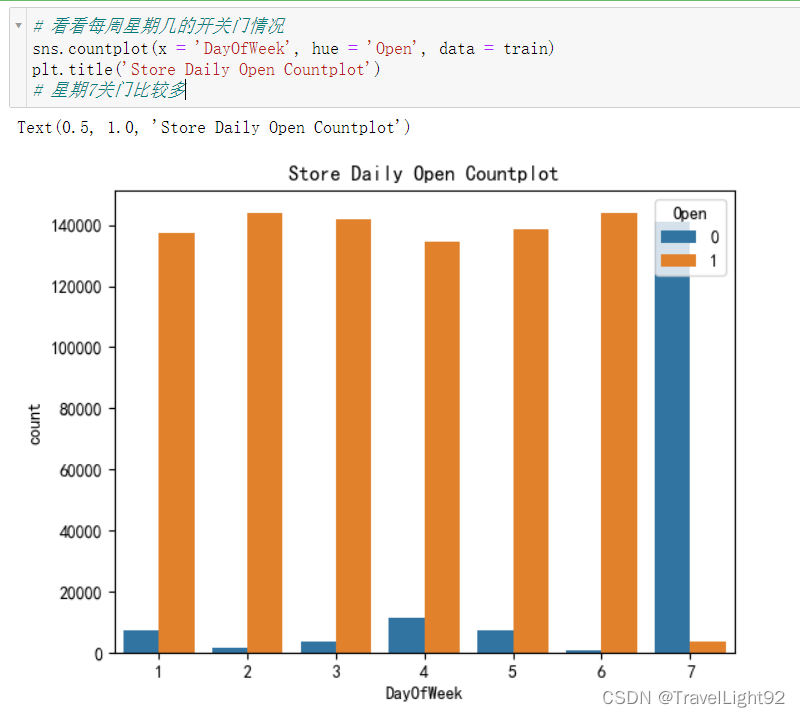
test中有11个OPEN为空,我们看看:

1.2.3 DayOfWeek
其实顾客数这一列拿到手就应该直接删掉,不过为了演示数据每一列什么意思,带着看一看;
# 看看周几对销售的影响
temp_weekday = train[(train.Open !=0)&(train.Sales >0)].groupby('DayOfWeek',as_index=False)[['Customers','Sales']].mean()
plt.figure(figsize=(10,5))
# 顾客数
plt.subplot(121)
bar1 = plt.bar(temp_weekday['DayOfWeek'],temp_weekday['Customers'])
plt.bar_label(bar1,label_type='edge',fmt='%.1f',padding=3)
plt.title('周几的顾客人数平均')
plt.ylabel('Customers')
# 销售额
plt.subplot(122)
bar1 = plt.bar(temp_weekday['DayOfWeek'],temp_weekday['Sales'],color='orange')
plt.bar_label(bar1,label_type='edge',fmt='%.1f',padding=3)
plt.title('周几的销售额平均')
plt.ylabel('Sales')
plt.tight_layout() 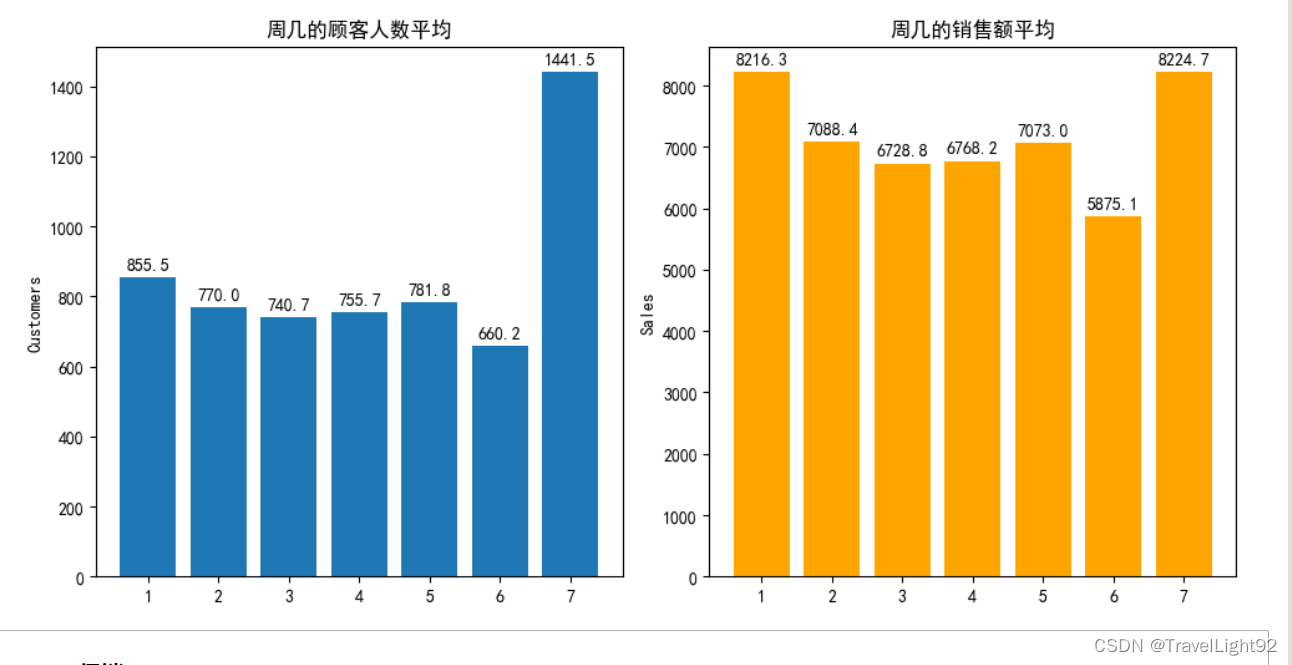
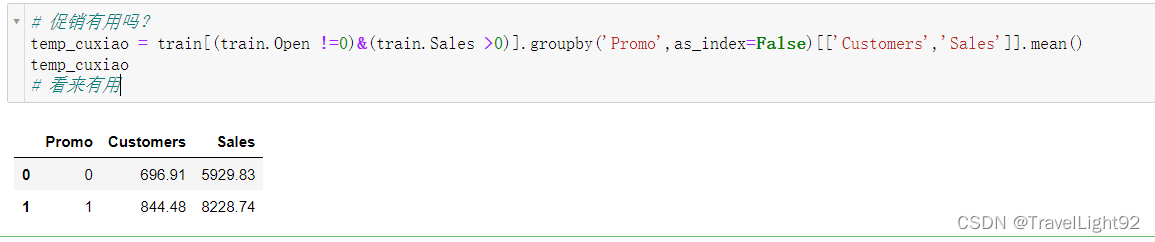
1.2.4促销Promo
发现促销=1的话,营业额多一些;

1.2.5 StateHoliday
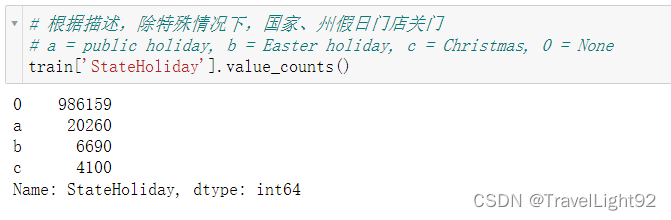
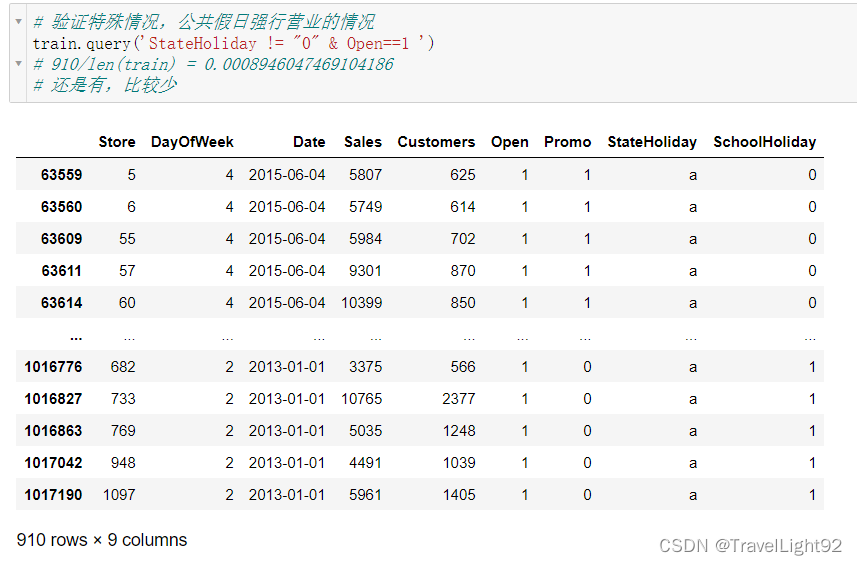
还是有一些公共假日强行开门的情况嘛,不过很少;
 假日开门,销售额更高,不过rierman看起来比较人性化,不该赚的钱不赚;
假日开门,销售额更高,不过rierman看起来比较人性化,不该赚的钱不赚;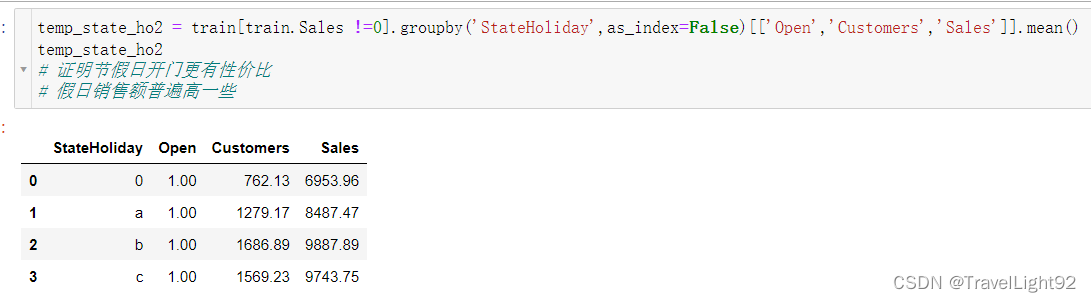
将上面的数字图形化展示;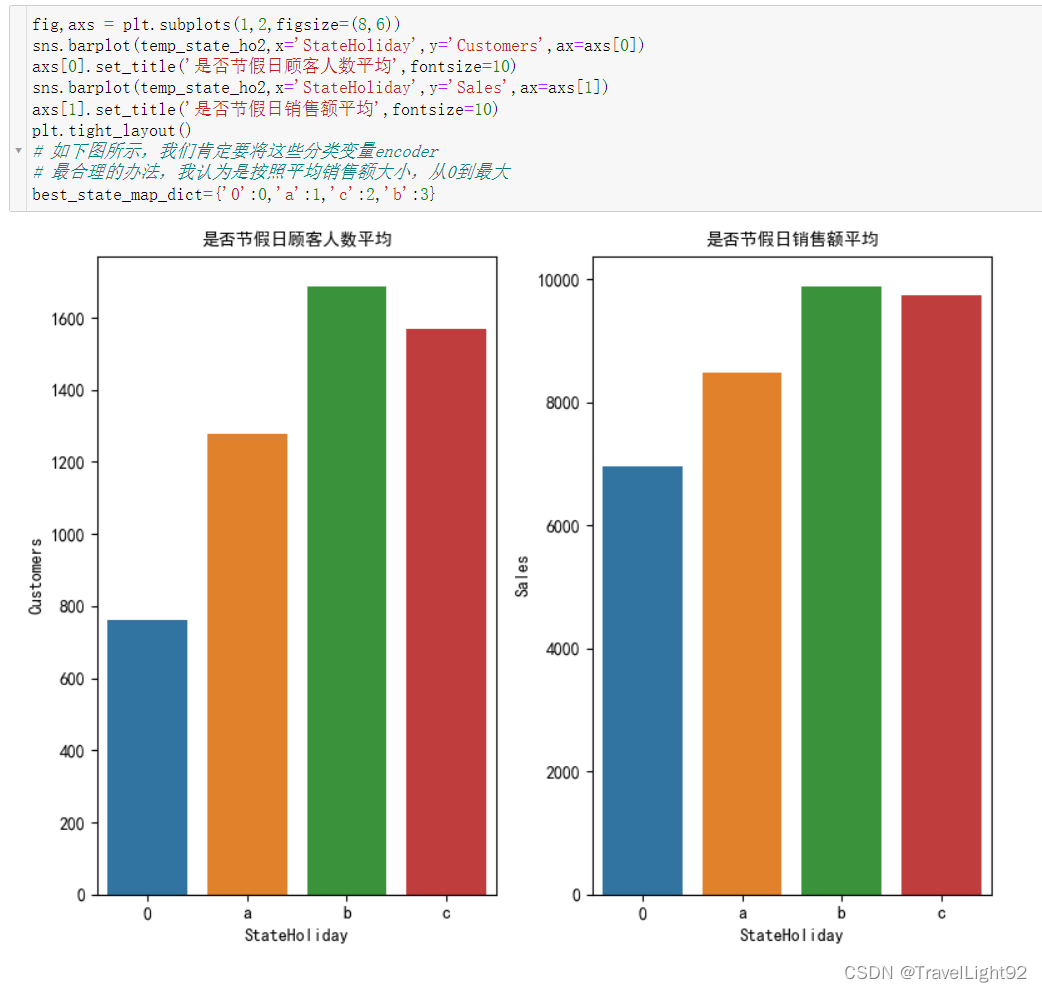
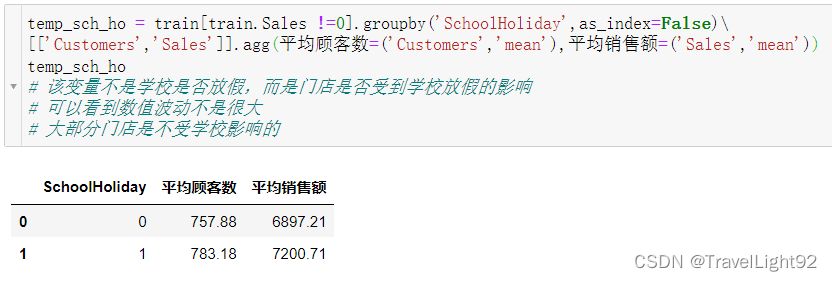
1.2.6 SchoolHoliday
这个特征并不是学校是否放假,而是学校放假对这个门店有没有影响,可能有的门店很靠近学校,吃的就是学校这门生意,门店销售额会受到学校影响较大,但是从数据看,8成店铺不受影响,也比较符合生活经验;

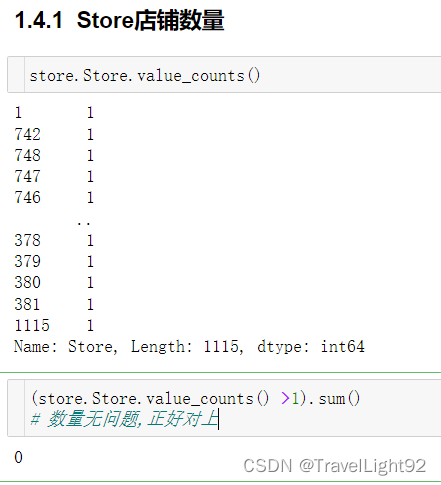
 1.2.7门店数Store
1.2.7门店数Store
还是要验证下,会不会有数据重复,看来没有;
1.2.8 日期Date
可以在read_csv里面,先设置将日期列解析(parse_dates)。
1.2.9 Customers& Sales
这里是带着质疑的眼光和目的来分析的,顾客数这个指标非常关键,而test中没有;
但就这个数据竞赛而言,的确不可能先知道未来的顾客数,相当于一刀砍在大动脉上;
实际做这个数据集,第一步就应该先把Customers删除掉!!!
# 挑选2个门店看看,顾客数和销售额关系如何
lucky_1 = choice(np.unique(train.Store)) # 随便挑一个门店看看
lucky_1_info = train.query(f'Store=={lucky_1} & Sales >0')
lucky_2 = choice(np.unique(train.Store)) # 再挑一个门店看看
lucky_2_info = train.query(f'Store=={lucky_2} & Sales >0')
fig = plt.figure(figsize=(8,8))
f1 = fig.add_subplot(211)
sns.regplot(lucky_1_info,x='Customers',y='Sales',fit_reg=True,scatter=True,ax=f1)
f1.set_title(f'Store={lucky_1}')
f2 = fig.add_subplot(212)
sns.regplot(lucky_2_info,x='Customers',y='Sales',fit_reg=True,scatter=True,ax=f2)
f2.set_title(f'Store={lucky_2}')
plt.tight_layout()果然符合常理,顾客越多,销售越好,但test中没有顾客人数,所以这份数据集,完全就是根据这个每家店铺旁边竞争对手情况、周边情况等进行预测,很有商业视角的感觉;
但后话是,这份数据集并没有特别大的意义,甚至有点shit,这个案例重要的是在于特征处理上。

重要!重要!重要!数据有偏态,不处理对结果影响很大!
# 需要知道的是,我们的销售额分布是右偏的
# log(0)数值是无限大的,我们考虑拉普拉斯平滑,就是x_new = log(x+1)
# 即便x=0,也可以是个0,不至于无限大
# 查看销售额分布
fig = plt.figure(figsize=(12,5))
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
g1 = sns.distplot(train['Sales'],hist = True,label='skewness:{:.2f}'.format(train['Sales'].skew()),ax = ax1)
g1.legend()
g1.set(xlabel = 'Sales', ylabel = 'Density', title = 'Sales Distribution')
g2 = sns.distplot(np.log1p(train['Sales']),hist = True,label='skewness:{:.2f}'.format(np.log1p(train['Sales']).skew()),ax=ax2)
g2.legend()
g2.set(xlabel = 'log(Sales+1)',ylabel = 'Density', title = 'log(Sales+1) Distribution') 
1.3 store数据集查看
目录不再详细写了,太费劲,本文和代码数字对不上,但顺序没问题,顺着往下看是没错的!
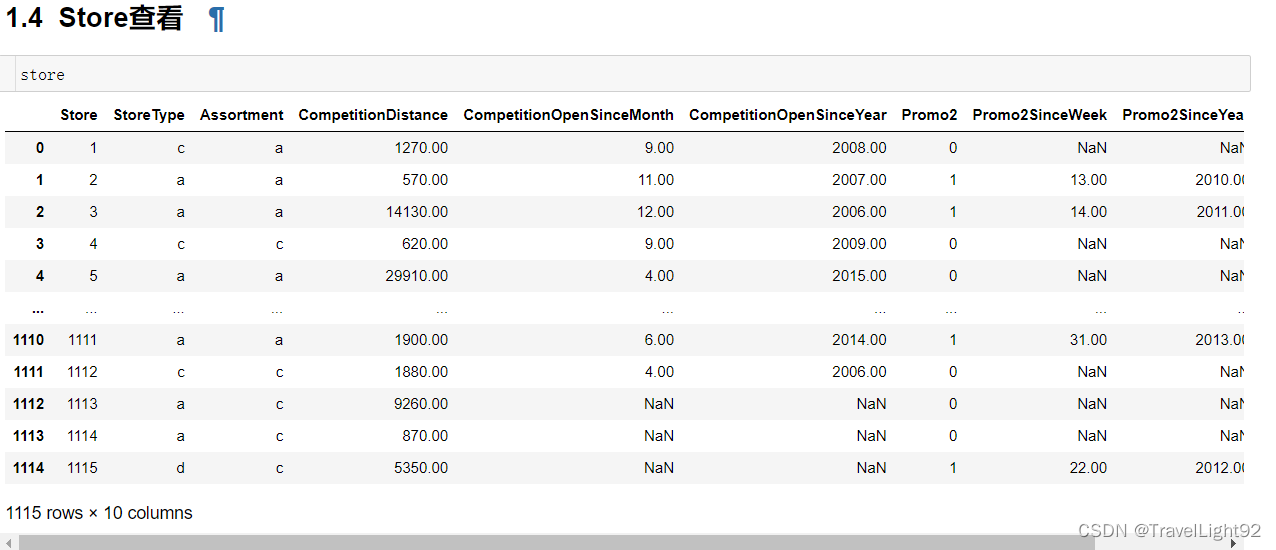
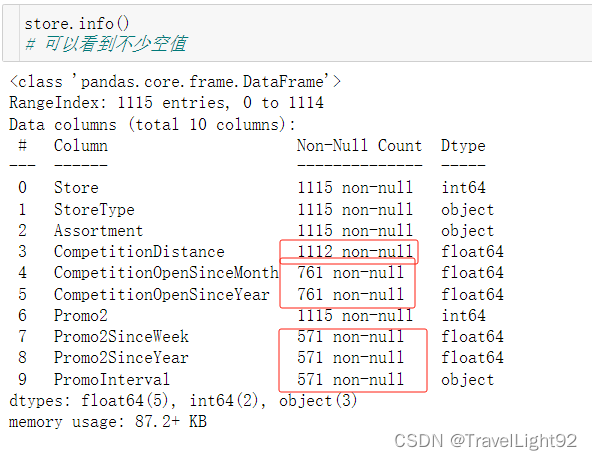


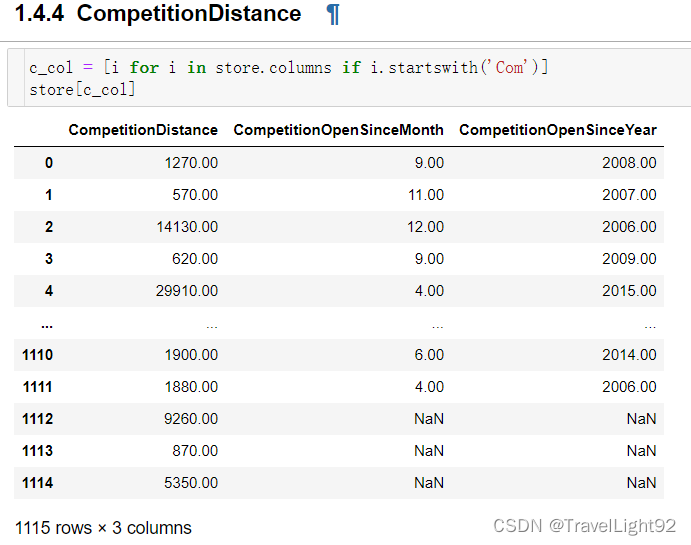
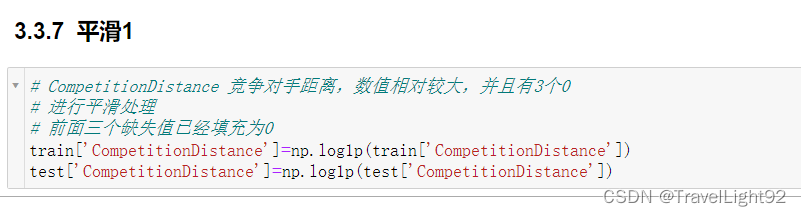
一开始看到这么多缺失值,以为很头疼,仔细看其实缺得很对称,竞争对手距离有3个为空,则对手开门起始年、月两列也是空的,后面看了一下这三家店的销售,情况不错,应该是没有值得称为对手的店铺;
# 有三个店铺,竞争对手距离是空值
# 对手距离为空,则另外2个变量,竞争对手--开门多少月、多少年也为空
fig,axs = plt.subplots(1,3,figsize=(12,6))
sns.histplot(store.CompetitionDistance,kde=True,ax=axs[0])
axs[0].set_title('对手距离分布')
sns.histplot(store.CompetitionDistance,kde=True,ax=axs[1],log_scale=True)
axs[1].set_title('距离分布-log10')
sns.histplot(np.log1p(store.CompetitionDistance),kde=True,ax=axs[2])
axs[2].set_title('距离分布--log1p')
# 比较好的办法,空值先填充0
# 再用log(x+1),这样这三个为0的还是0
# 同时距离这个量跨度比较大,log后也比较正态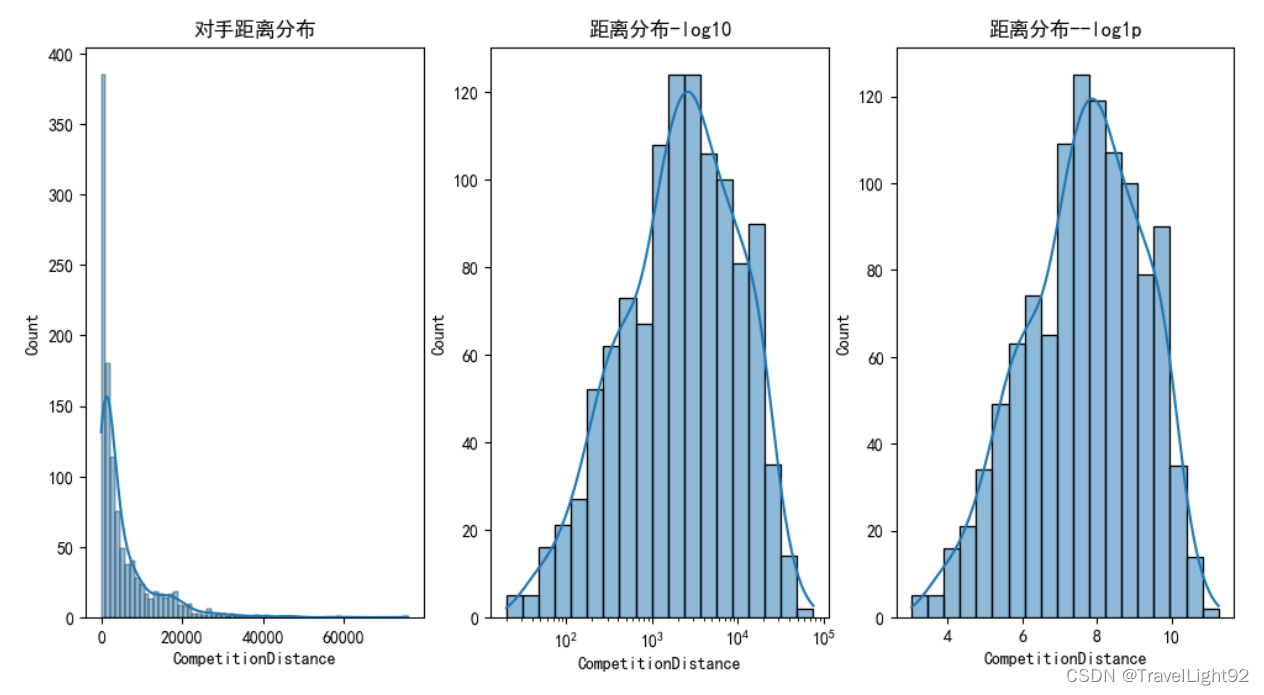
对手起止年、月,缺失是同步的,要么都有要么都缺,证明store这1115家店的统计情况,是比较干净正确的数据;

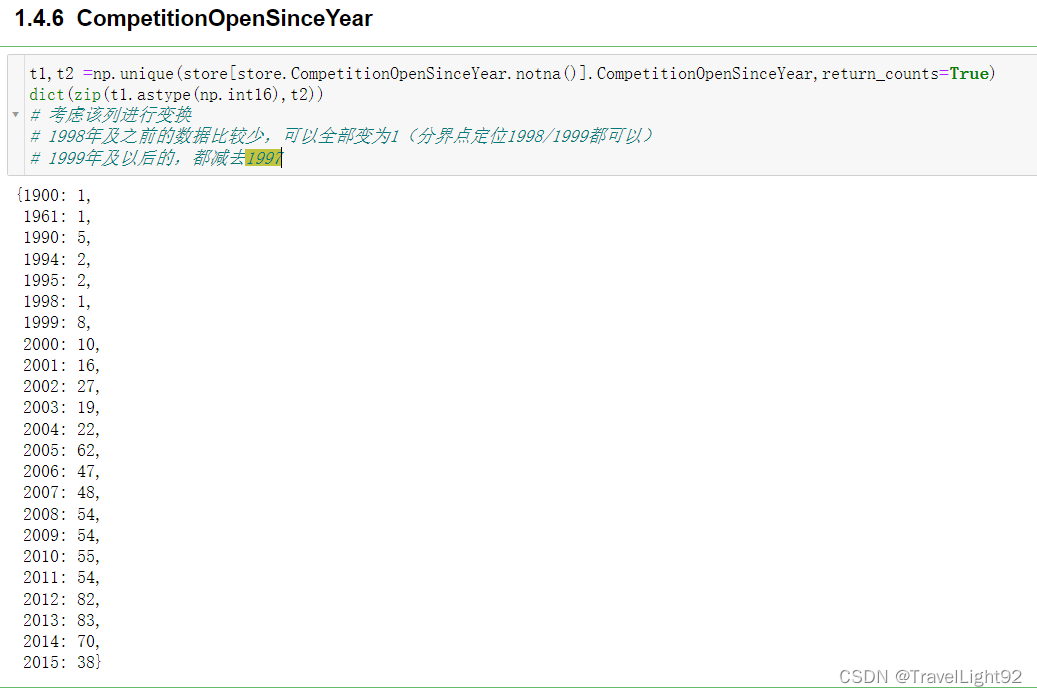

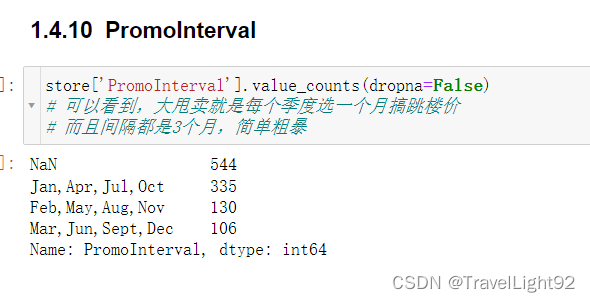
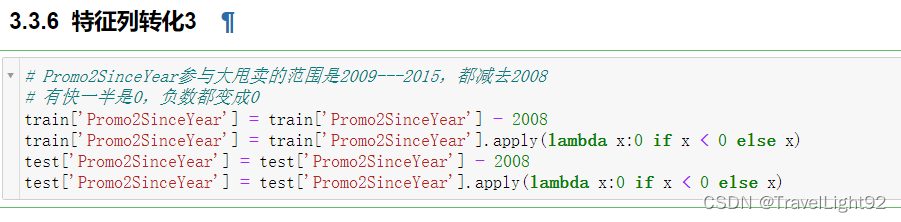
Promo2这列,本文通俗称为跳楼大甩卖,每个季度一个月,搞特价,为0的和为1的基本对半开,如果为0,则衍生的两列,since_week,since_year都为空,为1则这两列都有值,数据干净漂亮;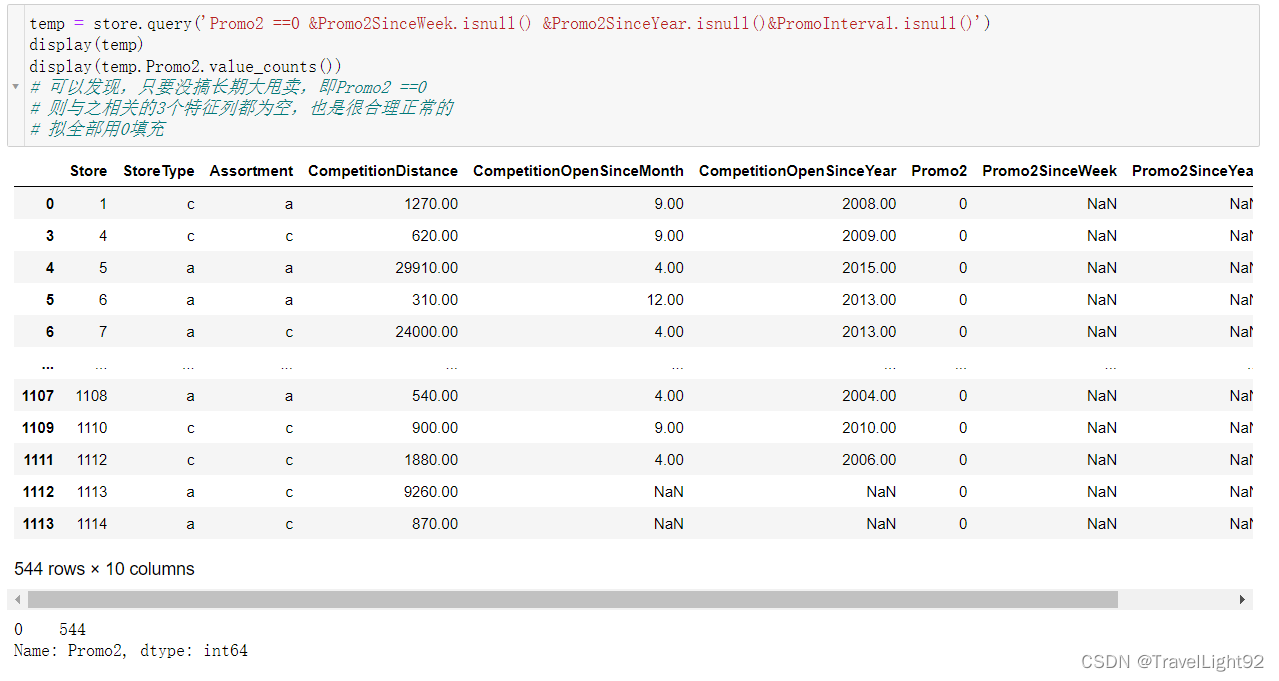


参加大甩卖,则1,4,7,10月大甩卖,或者2,5,8,11月,或者3,6,9,12月,就这三种情况;
二、画图看看
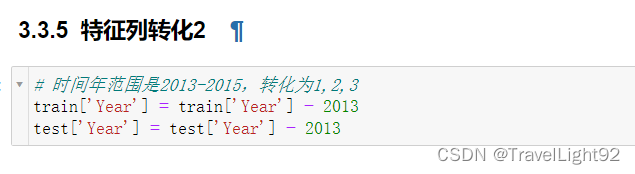
Date这玩意不能比较,只能转化出年、月、日、周来给模型,转化后要丢掉;
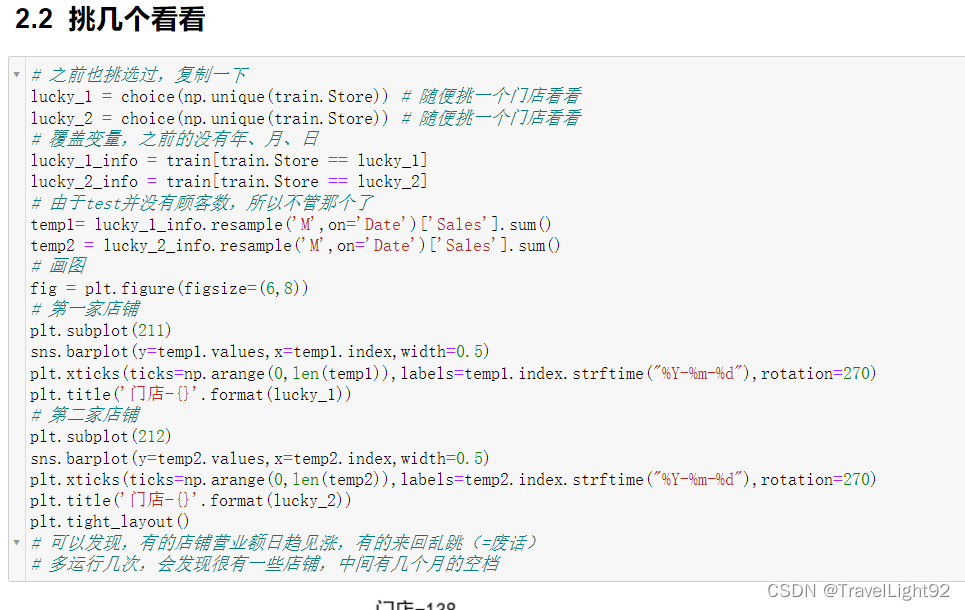
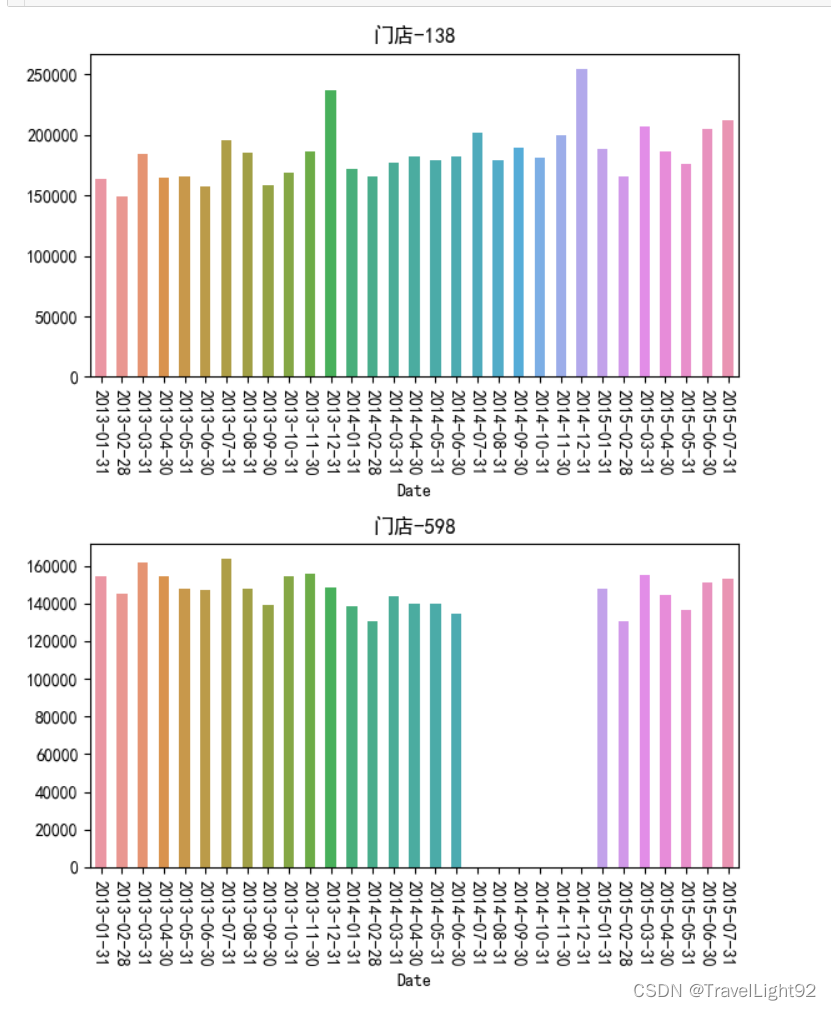
我们发现了奇怪的空缺,经过一番研究查看,发现有的店铺记录有900多条,有的是700多条,少一百多条,缺几个月很正常;

仔细查看还可发现,有些店铺当月有记录,但是当月销售额为0,总共有20条;
不深究这东西也没关系,因为我们训练数据,只要当天销量大于0的;
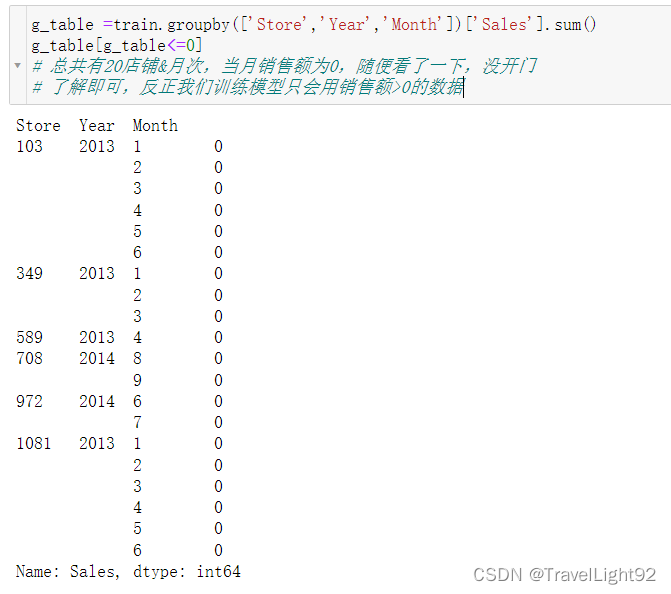
三、特征工程
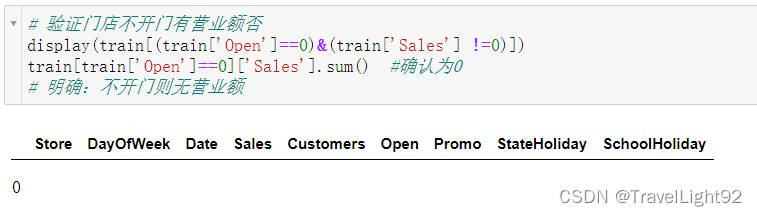
# 对 train\test的查看总结
# 1.train中明确了不开门则无营业额
# 2.train中有54个开门但是无营业额的数据,很可能有问题,但是我们只用sales>0的
# 3.test中622号店铺,有11条数据OPEN = NULL,但时间是最新的,填充0和1对比(实际结果填充0和1都一样,但应该填充为0,因为除以0会报错,所以在算分的时候,这11条应该被剔除了)
# 4.test中有不少OPEN=0的,预测直接写为0
# 对 store总结
# 1.CompetitionDistance 有3个缺失,同时其SinceMonth,SinceYear亦缺失
# 判断该店铺经营不错,拟将这3个店铺的三列缺失都填充为0
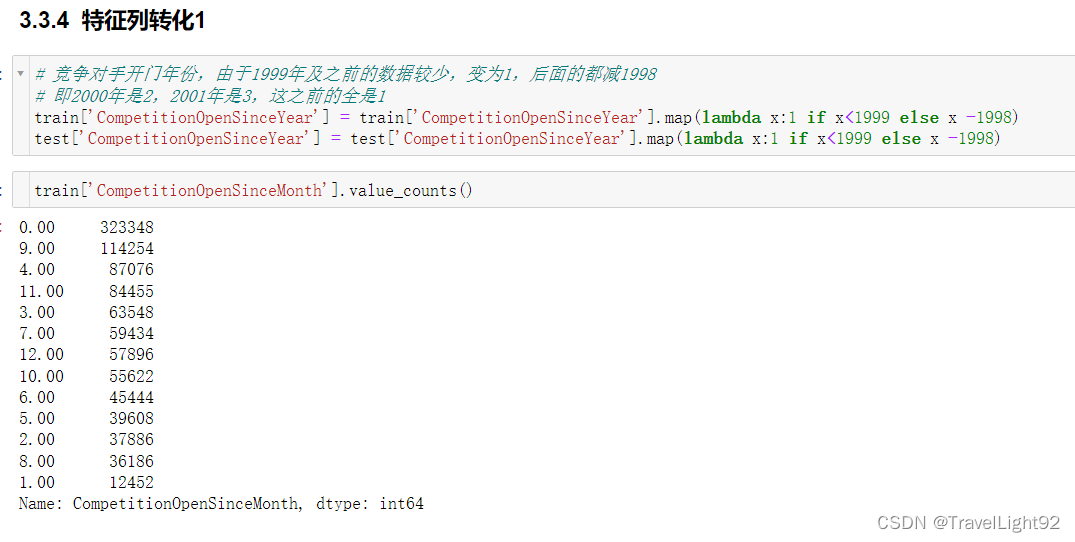
# 2.CompetitionOpenSinceMonth,SinceYear缺失较多,但好消息是两者缺失是同时缺失的,都用0填充
# 3.Promo2SinceWeek,SinceYear,PromoInterval缺失较多,只要promo2为0,
# 即不参与大甩卖的,后面这三个列都是空值
# 4.如果参加大甩卖,则后面都非空(已验证)



要对分类变量进行映射,转为数字,我根据销量的大小排了序;

PromoInterval是个空或者字符串,根据这个字段,转变为判断当月是否跳楼大甩卖,转完删掉,中间利用了一个临时变量;
# 同时新增字段,判断该月是否为跳楼大甩卖的开始月
# 需要利用一个临时字段,用完删掉
for data in [train,test]:
# 1.新增临时字段monthname,判断该月是否为促销月
map_dict = {1: 'Jan', 2: 'Feb', 3: 'Mar', 4: 'Apr', 5: 'May', 6: 'Jun', 7: 'Jul', 8: 'Aug', 9: 'Sep', 10: 'Oct',
11: 'Nov', 12: 'Dec'}
data['monthname'] = data['Month'].map(map_dict)
# 因为把促销间隔空值填充为0,故要把情况写全,不然报错
# TypeError: argument of type 'float' is not iterable
data['IsPromoMonth'] = data.apply(lambda x:0 if x['PromoInterval']==0 else 1 if x['monthname'] in x['PromoInterval'] else 0,axis=1)
# 3.将几个其他object字段映射
data['StoreType'] = data['StoreType'].map(best_type_map_dict)
data['StateHoliday'] = data['StateHoliday'].map(best_state_map_dict)
data['Assortment'] = data['Assortment'].map(best_assort_map_dict)
# 4.用完删掉
data.drop('monthname',inplace=True,axis=1)这数据集拼的完全就是数据集的多少,在不添加额外数据集的情况下,新增字段对上分大大滴好

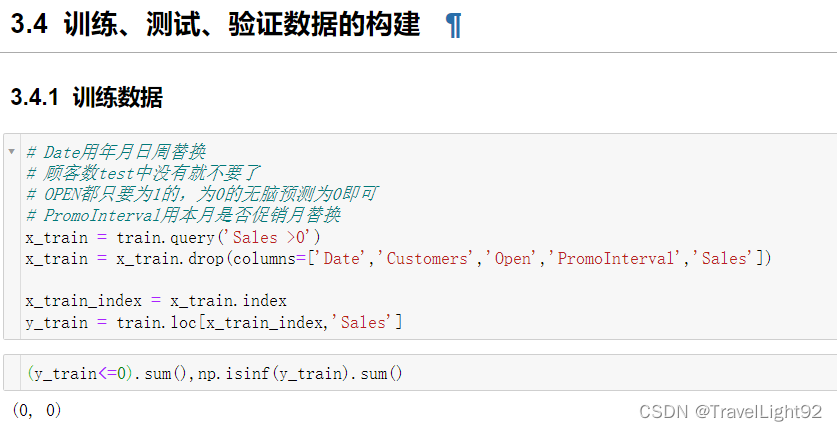
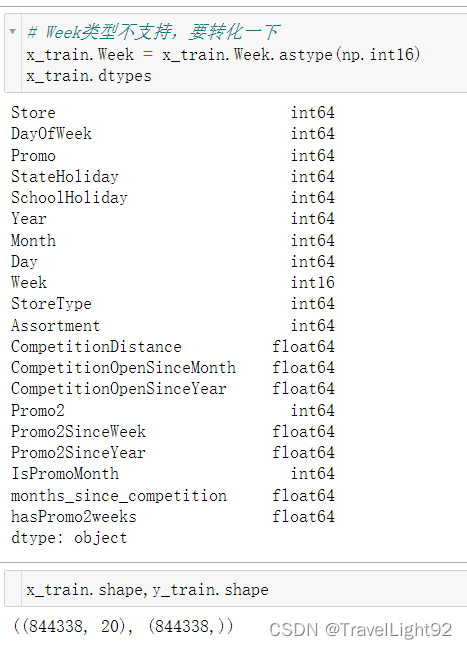
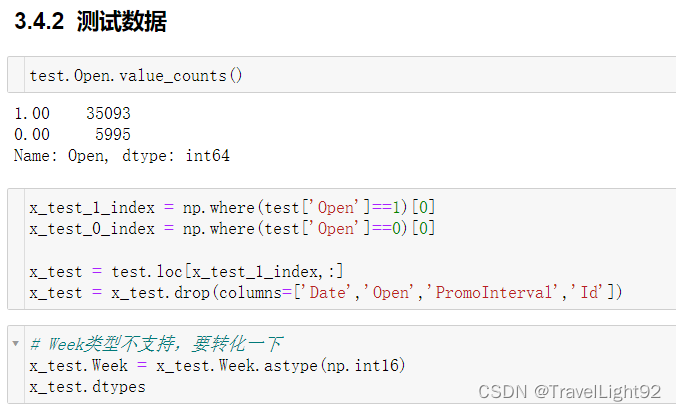
四、模型计算
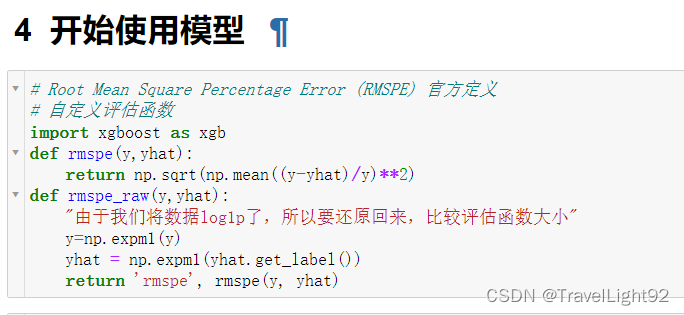 一开始用了3000轮CPU计算,没想到还没停止,直接用GPU一万轮,懒得等了;
一开始用了3000轮CPU计算,没想到还没停止,直接用GPU一万轮,懒得等了;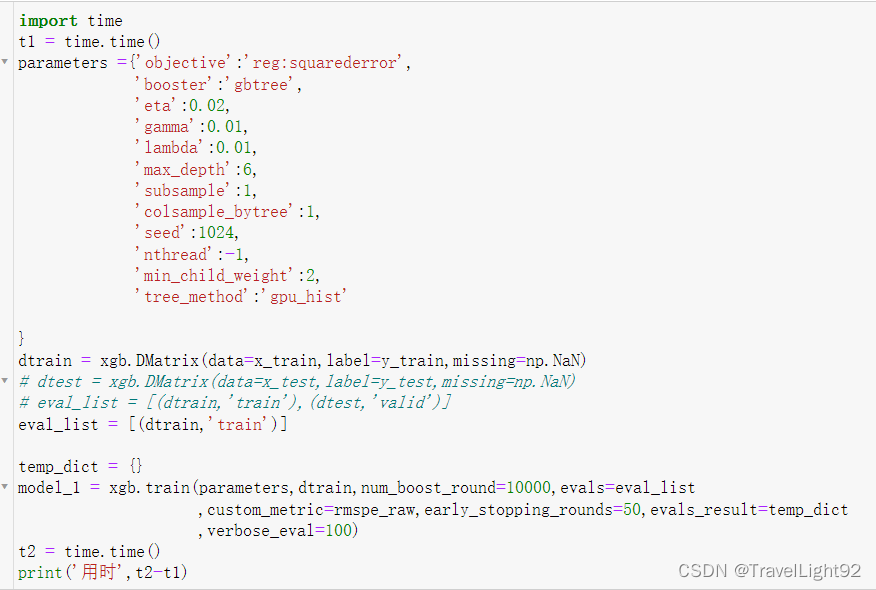
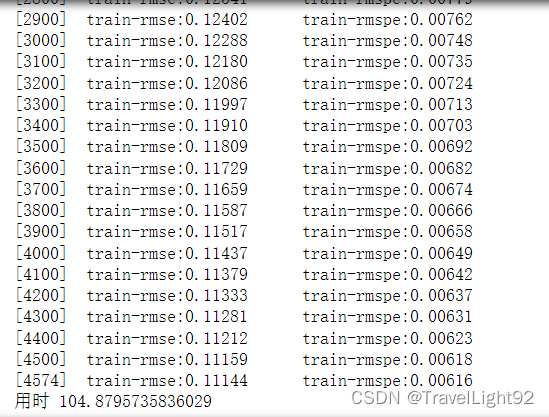


leaderboard的顶是0.10021,我们没有调参,没有用额外数据集,0.124其实不错了,调一下参数,0.1开头应该没什么问题,而且gpu_hist直方图,效果略微差一点,主要是快;
sklearn调参,要稍微修改下自定义评估函数,先log1p(sales_true),再np.expm1(sales_predict);
源代码:
用jupyter notebook的,如果用其他IDE可能在某些print中要稍微改改!
文章稍微精简了一点点内容,不影响主体和分数!
链接:https://pan.baidu.com/s/1_X2JfMS0bqxAn7OfYmoSbw
提取码:1999















 4562
4562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









