






目录
1、Learning Implicit Fields for Generative Shape Modeling(CVPR2019)
2、Occupancy networks: Learning 3d reconstruction in function space(CVPR2019)
3、Convolutional occupancy networks(ECCV 2020)
4、Dynamic plane convolutional occupancy networks
5、Deepsdf: Learning continuous signed distance functions for shape representation
6、SAL: Sign Agnostic Learning of Shapes from Raw Data
7、Bsp-net: Generating compact meshes via binary space partitioning(CVPR20oral)
1、Learning Implicit Fields for Generative Shape Modeling(CVPR2019)
our work is the first to introduce a deep network for learning implicit fields for generative shape modeling
输入:it takes a point coordinate (x, y, z), along with a feature vector encoding a shape,
输出:outputs a value which indicates whether the point is outside the shape or not.
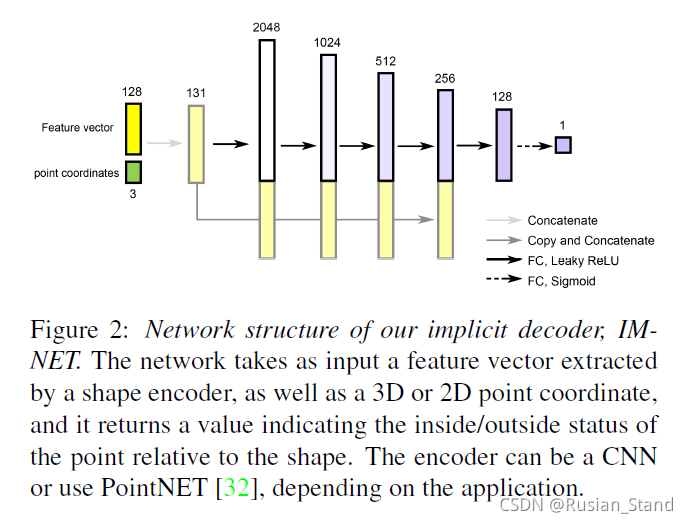
结果:

数据的获取:通过HSP算法得到在不同分辨率下的voxel model
模型的获取:通过mach cube 方法获得不同体素分辨率下的mesh
2、Occupancy networks: Learning 3d reconstruction in function space(CVPR2019)
输入:在对象的边界框内均匀地采样并使用额外的小填充得到的3D点
输出:这个3D点是否在模型内还是外
用一个隐式函数来表达占用概率,从而可以实现任意分辨率的表达
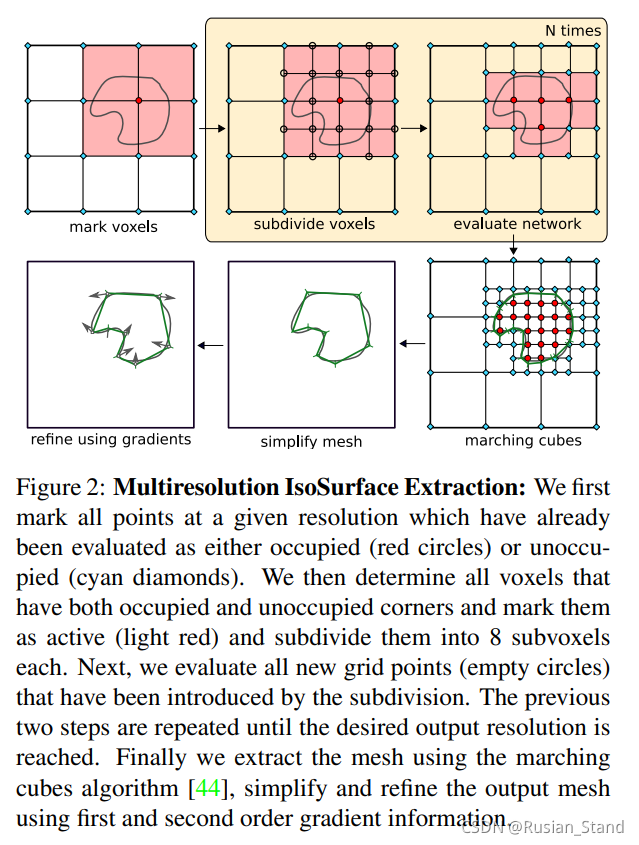
多分辨率等值面提取技术 [Multiresolution IsoSurface Extraction (MISE)]
3、Convolutional occupancy networks(ECCV 2020)
An ideal representation of 3D geometry should have the following properties: a) encode complex geometries and arbitrary topologies, b) scale to large scenes, c) encapsulate local and global information, and d) be tractable in terms of memory and computation.
Volumetric - resolution(memory and computation.)but is limited in terms of resolution due to its large memory consumption.
Point clouds-topological relations.points However, there are no topological relations among points, so extra post-processing steps are required
Mesh-based-hard to predict using neural networks.(应该还有其他的缺点) Meshes [14, 15, 18] emphasize topological relations by constructing vertices and faces
we seek to combine the complementary strengths of convolutional neural networks with those of implicit representations.
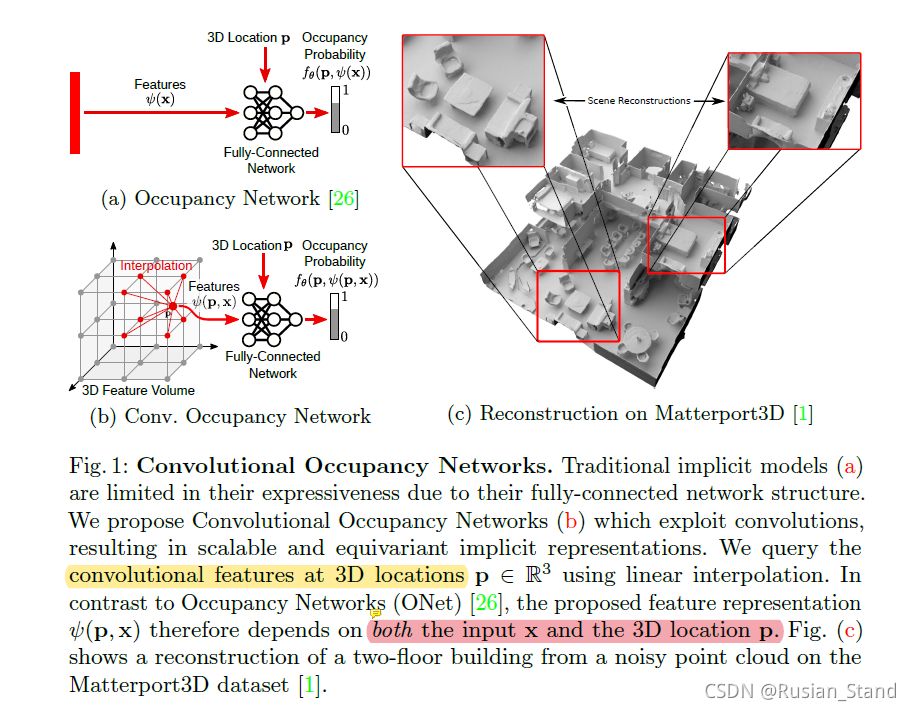
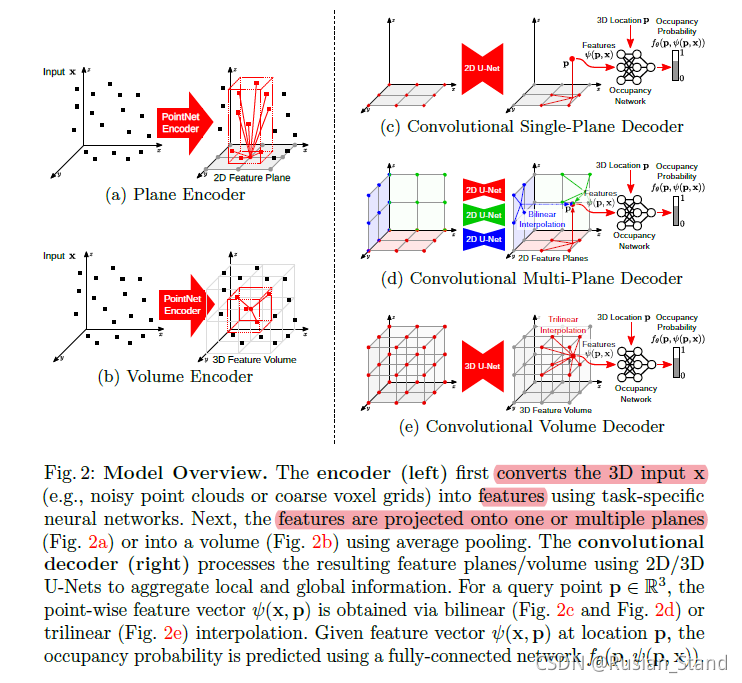
简单来说,就是先获得某个物体的点云,通过point++获得点云的feature voxelized features;,然后对输入的3Dlocation 局部特征聚合,判断P点是否被占据。
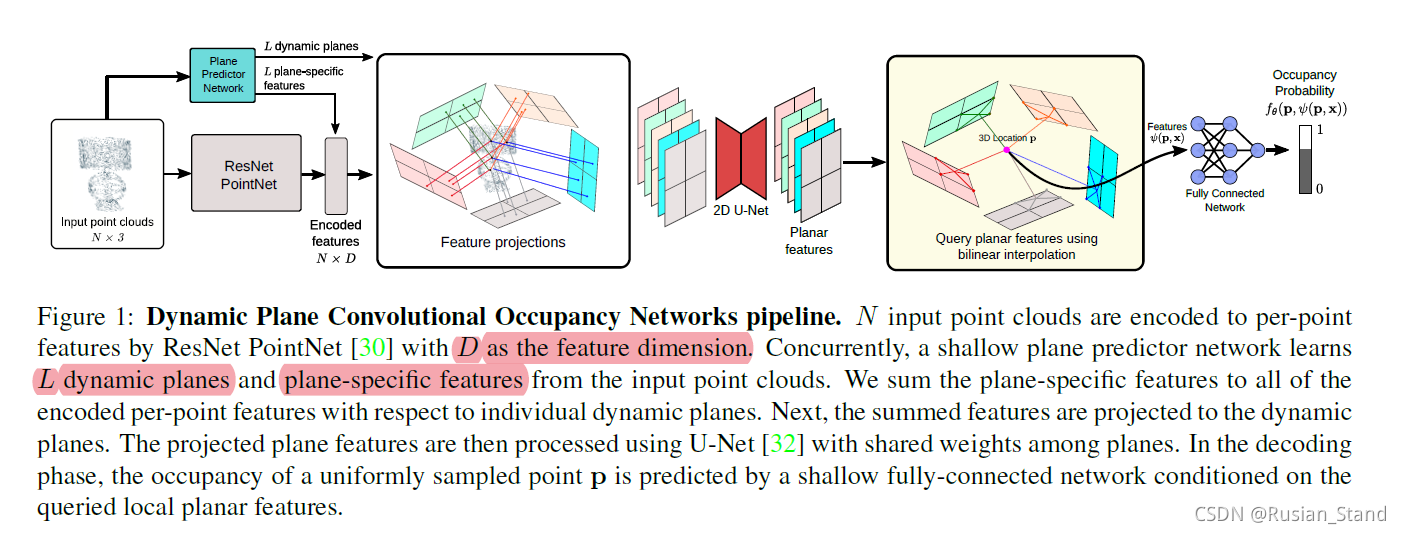
4、Dynamic plane convolutional occupancy networks
occupancy networks是continuous function;
convolutional occupancy networks是voxelized features;
本篇是动态平面组上的features
Our goal is to reconstruct 3D scenes with fine details from noisy point clouds. first encode the input point clouds into 2D feature planes, whose parameters are predicted by a fully-connected network. These feature planes are then processed using convolutional networks and decoded into occupancy probabilities via another shallow fully-connected network.
ResNet Point-Net [23, 28] to extract the per-point features
5、Deepsdf: Learning continuous signed distance functions for shape representation
SDF是CG领域又一个形状的表征;本篇是first to use deep SDF functions to model shapes
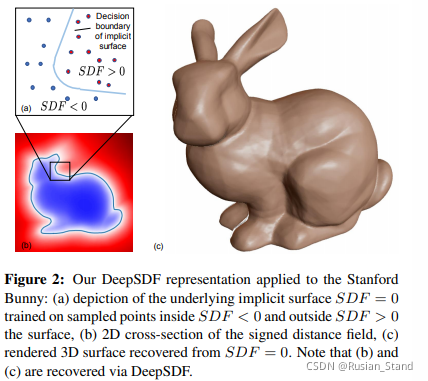
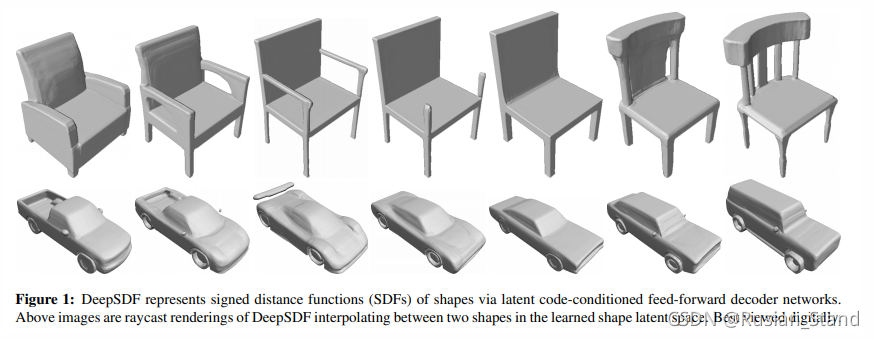
单个形状用单个SDF网络,一个category用code conditioned
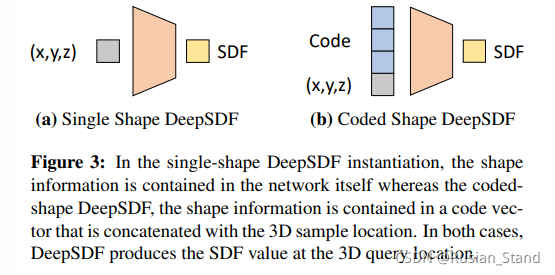
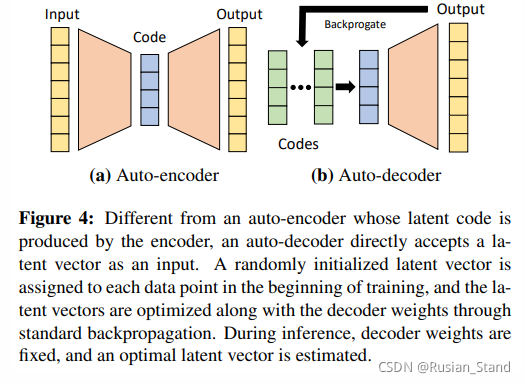
使用auto-decoder
6、SAL: Sign Agnostic Learning of Shapes from Raw Data
将网络初始化为球体的 方法的理论。
此方法可以将粗糙的点云变成mesh
简单来说:以往学习neural implicit representation需要在模型和点云上采样获得GT,但是这个过程是难计算,所以此方法就是直接在点云或者 triangle soups中学习NIR。即直接从原始 3D 数据中学习形状空间.
输入:未经过处理的点云或者triangle soups
学习的目标:优化网络模型的参数,使其表示三维模型。
小知识:
深度神经网络用于重建、学习和生成 3D 表面。主要有两种方法:参数化和隐式。在参数化方法中,神经网络用作参数化映射,represents a 3D shape as a collection of parametric surface elements,而隐式方法将表面表示为神经网络的零级集。zero level-sets of
neural network(sdf or occupancy function)
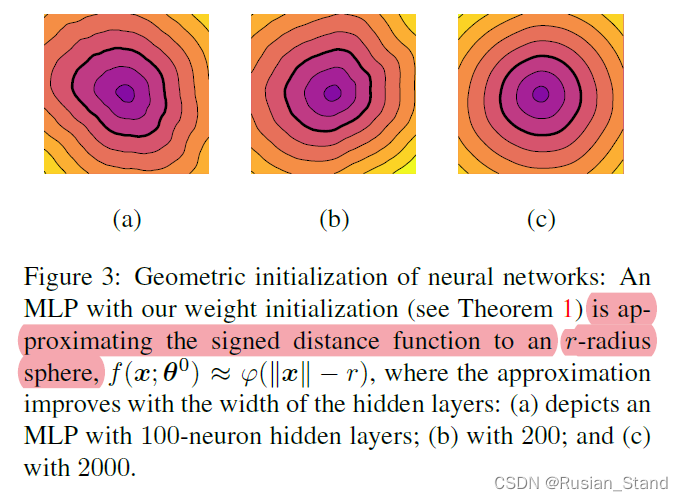
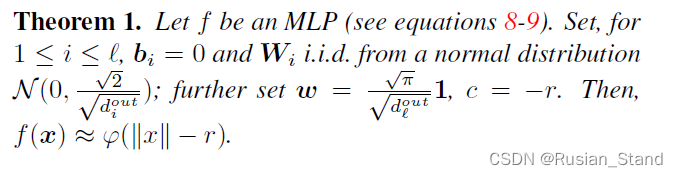
为单个隐藏层网络选择初始权重:

![]()
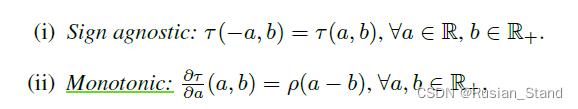
7、Bsp-net: Generating compact meshes via binary space partitioning(CVPR20oral)
We present BSP-Net, a network that generates compact meshes via binary space partitioning. Recently, several methods have been proposed to represent 3D shapes within neural networks. These approaches mainly fall into two categories. One is to warp a template mesh into the target shape. Another is to represent geometry via implicit functions. However, implicit methods require marching cubes to extract a surface mesh. The extracted meshes are not compact and contain too many polygons.
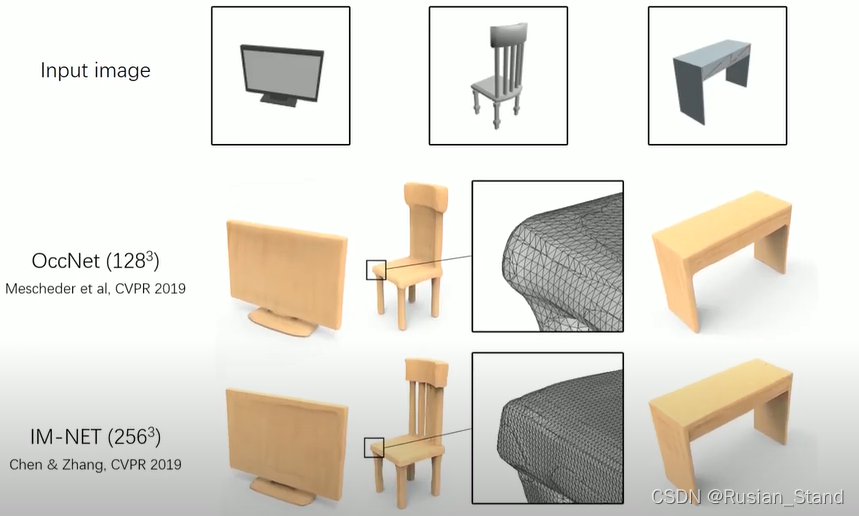
In this example we show a 3D object generated by IM-NET .The mesh is obtained by running marching cubes at a resolution of 256. And it contains hundreds of thousands of vertices and triangles. We would prefer to have a compact output mesh, with a few hundred vertices and retain the ability to represent complex structures. To address these problems, we propose a neural network which outputs meshes natively .Our generated meshes are low-poly and guaranteed to be watertight.The edges can reproduce sharp details, yet can still approximate curved boundaries. Overall, we attain high visual quality with very few primitives as reflected by the wireframe.
Our key idea is derived from binary space partitioning trees. Given a set of oriented planes. And the connections to group them. We can compute the intersection within each group to obtain convex shapes. And then take their union to construct the final output. The entire process is based on CSG operations. Hence, the output shape is a polygonal mesh .
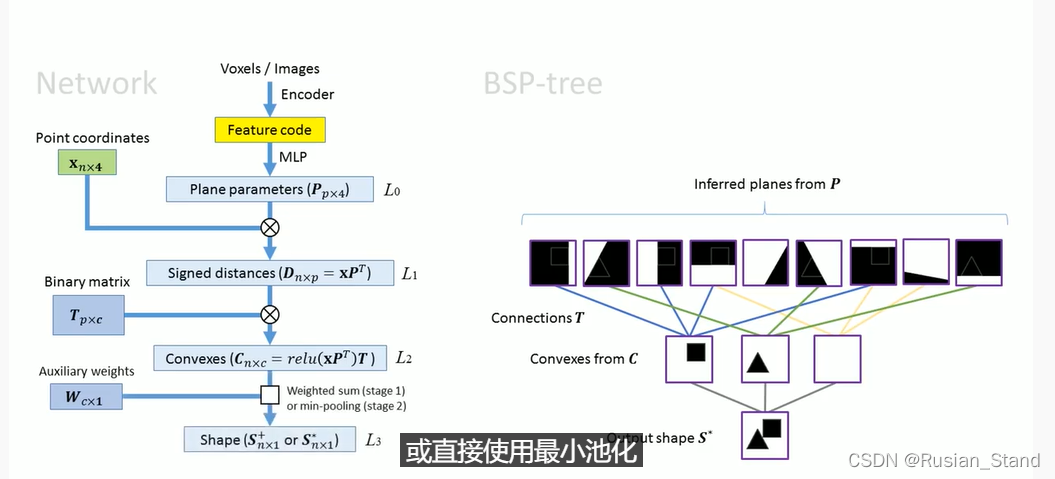
We designed the network in such way that each component represents a part of the BSP-tree .Given a voxel model or an image as input we use an encoder to get the corresponding feature code. And then use an MLP to map the feature code to plane parameters .The planes are the leaf nodes in the BSP-tree Similar to the training of other implicit models we sample a set of points in space The product of the plane parameters and the point coordinates will give us the signed distances which are visualized in the first layer of the right figure. To represent the connections in the BSP-tree we employ a trainable binary matrix .The product of this matrix with the distances represents convex shapes. Finally, we introduce some auxiliary weights and use the weighted sum to approximate the min-pooling operation or use min-pooling directly to obtain the final output shape.
Here we visualize the training process for a 2D toy example. We initialize the network with random weights before training Including the binary matrix that connects planes to convexes. And the auxiliary weights that aggregate the convexes to form the outpu All weights are float numbers, so that the gradients can easily propagate In stage one, we train the network with reconstruction loss and two other losses to help structure the tree.
Note how the connections are changed in the bottom level.The first stage gives a reconstruction of the target shape,but it might not be accurate due to the continuous weights.Therefore in the second stage ,we binarize the connection weights via thresholding and replace the weighted sum with min-pooling.Here we show the input shapes in our toy 2D experiment.The task of the network is to reconstruct each image as a combination of convex parts.And here are the outputs.Since all shapes share the same set of convexes and tree connections,we find shape segmentations and correspondences in the convex level.Here we show that the n-th convex consistently represents the same part.We compare our method with several other methods that perform shape decomposition via reconstruction.Our method not only achieves better reconstruction quality,but also has better segmentation results.Similar to the 2D case, we can find natural correspondences between convexes,Here, we manually group convexes into semantic parts,and visualize correspondences using different colors.Finally, since our BSP-Net is a differentiable 3D decoder,we can easily pair it with an image encoder to achieve single view reconstruction.We compare with several state-of-the-art methods to show the representation ability of our network and the compactness of the outputs.Please pay attention to the close-ups of mesh tessellations in the middle.Our method achieves comparable performance to the state-of-the-arts while using fewer amount of vertices and triangles.There is a recent work, CvxNet, that also performs convex decomposition .Our method differs from theirs, as we target low-poly reconstruction,and our network has a dymanic number of convexes for different shapes.The source code of our work is available on Github
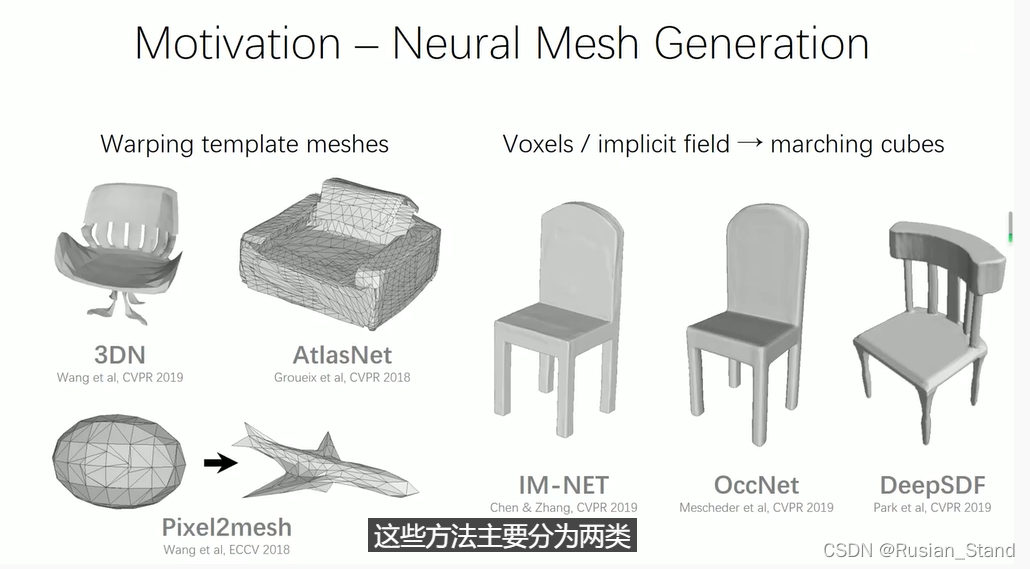
我们提出了 BSP-Net,这是一种通过二进制空间分区生成紧凑网格的网络。最近,已经提出了几种方法来表示神经网络中的 3D 形状。这些方法主要分为两类。一种是将模板网格扭曲成目标形状。另一种是通过隐函数来表示几何。然而,隐式方法需要移动立方体来提取表面网格。提取的网格不紧凑并且包含太多多边形。
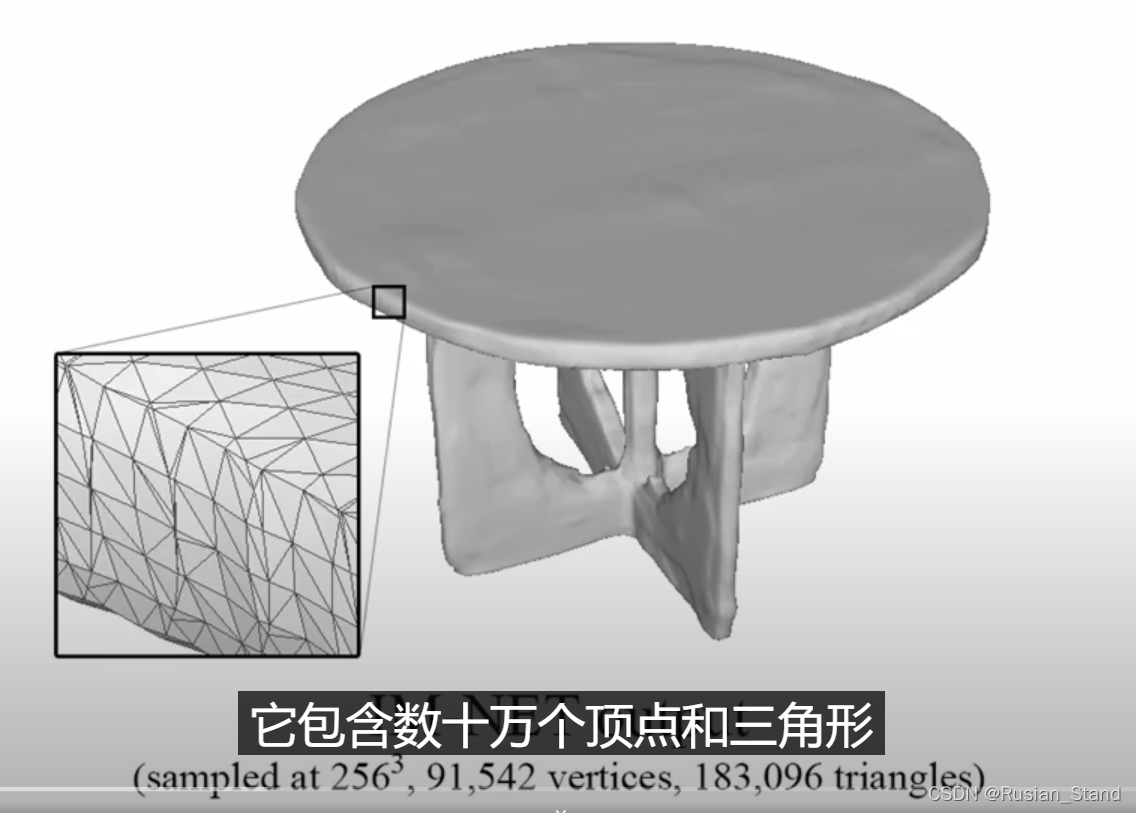
在这个例子中,我们展示了一个由 IM-NET 生成的 3D 对象。网格是通过以 256 的分辨率运行行进立方体获得的。它包含数十万个顶点和三角形。我们更希望有一个紧凑的输出网格,有几百个顶点并保留表示复杂结构的能力。

为了解决这些问题,我们提出了一种本地输出网格的神经网络。我们生成的网格是低多边形的并且保证是水密的。边缘可以再现清晰的细节,但仍然可以近似弯曲边界。总的来说,我们通过线框反映的极少图元获得了高视觉质量。
我们的关键思想来自二元空间分区树。给定一组定向平面。以及将它们分组的连接。我们可以计算每个组内的交集以获得凸形。然后取他们的联合来构造最终的输出。整个过程基于CSG操作。因此,输出形状是多边形网格。
我们以每个组件代表 BSP 树的一部分的方式设计网络。给定体素模型或图像作为输入,我们使用编码器来获取相应的特征代码。然后使用MLP将特征码映射到平面参数上。平面是BSP-tree中的叶子节点 类似于其他隐式模型的训练 我们在空间中采样一组点 。平面参数和点的乘积坐标将为我们提供符号距离,这些距离在右图的第一层中可视化。为了表示 BSP 树中的连接,我们使用了一个可训练的二元矩阵 。这个矩阵与距离的乘积表示凸形状。最后,我们引入了一些辅助权重,并使用加权和来近似最小池化操作或直接使用最小池化来获得最终输出形状。
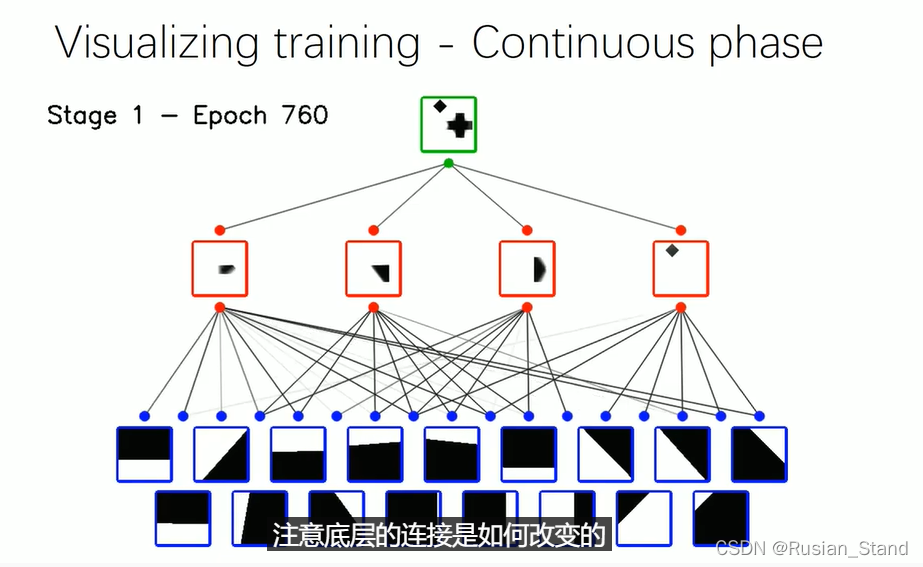
在这里,我们将 2D 玩具示例的训练过程可视化。我们在训练之前用随机权重初始化网络,包括将平面连接到凸面的二进制矩阵。以及聚合凸面形成输出的辅助权重 所有权重都是浮点数,以便梯度可以轻松传播 在第一阶段,我们用重建损失和其他两个损失来训练网络以帮助构建树。注意底层的连接是如何变化的(有些线条会消失)。
第一阶段给出了目标形状的重建,但由于权重连续,它可能不准确。因此,在第二阶段,我们通过阈值对连接权重进行二值化并替换带最小池化的加权和。
这里我们展示了我们玩具 2D 实验中的输入形状。
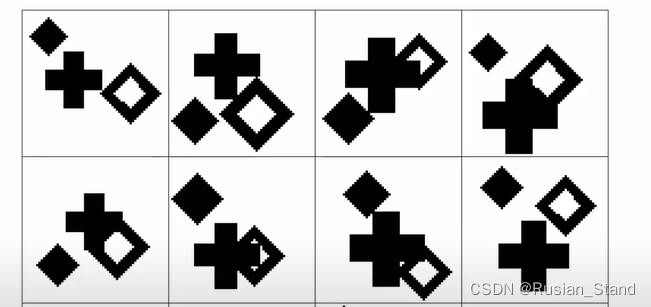
网络的任务是将每个图像重建为凸部分的组合。
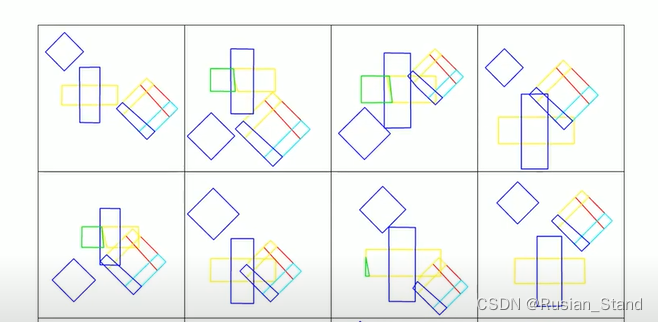
这是输出。由于所有形状共享相同的一组凸面和树连接,我们在凸面级别找到形状分割和对应关系。这里我们表明第 n 个凸面始终代表相同的部分。我们将我们的方法与其他几种通过重建进行形状分解的方法。我们的方法不仅实现了更好的重建质量,而且具有更好的分割结果。
类似于二维情况,我们可以找到凸面之间的自然对应关系,这里,我们手动将凸面分组为语义部分,并使用不同颜色可视化对应关系。最后,由于我们的 BSP-Net 是一个可微的 3D 解码器,
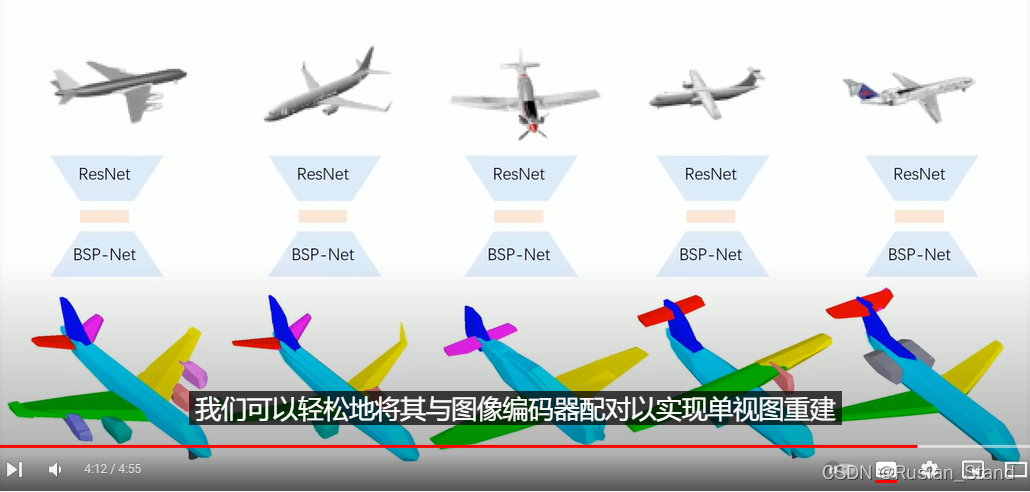
我们可以轻松地将其与图像编码器配对以实现单视图重建。我们与几种最先进的方法进行比较以显示我们网络的表示能力和输出的紧凑性。

请注意中间网格细分的特写。我们的方法达到了可比的在使用较少数量的顶点和三角形的情况下达到最新技术水平。最近的一项工作 CvxNet 也执行凸分解。我们的方法与他们的方法不同,因为我们针对的是低多边形重建和我们的网络具有不同形状的动态凸面数。
8、Neural-Pull: Learning Signed Distance Functions from Point Clouds by Learning to Pull Space onto Surfaces
方法的目的:从粗糙的点云中提取出较好的三维模型
简单来说:具体来说,训练一个神经网络,使用预测的有符号距离值和查询位置的梯度将查询 3D 位置拉到表面上最近的点,这两者都是由网络本身计算的。 pull操作可以沿着或逆着 SDF 的梯度方向以网络预测的SDF值移动查询位置 。
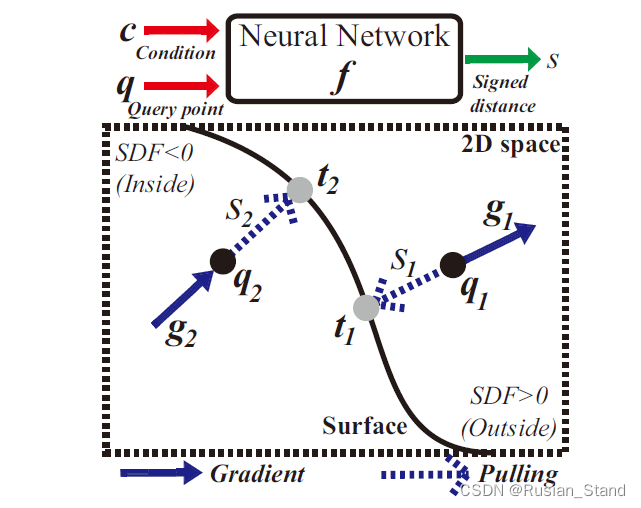
如果sdf值是负的,就沿着梯度的方向移动预测的sdf值距离,即:
如果sdf值是正的,就沿着梯度相反的方向移动预测的sdf值距离,即:
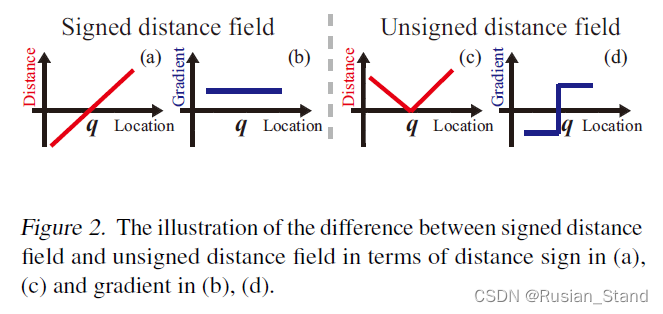
有符号距离值和无符号距离值的区别:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









