







YOLOv1:YOLO v1深入理解
YOLOv2:YOLOv2 / YOLO9000 深入理解
转载自:YOLOv3 深入理解
Yolov3是2018年发明提出的,这成为了目标检测one-stage中非常经典的算法,包含Darknet-53网络结构、anchor锚框、FPN等非常优秀的结构。
YOLOv3没有太多的创新,主要是借鉴一些好的方案融合到YOLO里面。不过效果还是不错的,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。
YOLO3主要的改进有:
调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax。
新的网络结构Darknet-53
在基本的图像特征提取方面,YOLO3采用了称之为Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路(shortcut connections)

上图的Darknet-53网络采用256x256x3作为输入,最左侧那一列的1、2、8等数字表示多少个重复的残差组件。每个残差组件有两个卷积层和一个快捷链路,一个残差组件示意图如下:
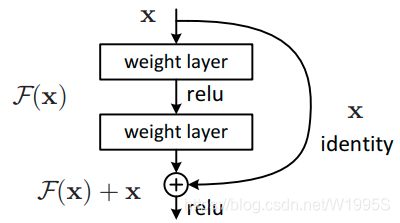
Yolo_v3使用了darknet-53的前面的52层(没有全连接层),yolo_v3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
为了加强算法对小目标检测的精确度,YOLO v3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。
作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3x(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score/confidence score。
详细的网络结构


上图三个蓝色方框内表示Yolov3的三个基本组件:
(1)CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
(2)Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。
(3)ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作:
(1)Concat:张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。Concat和cfg文件中的route功能一样。
(2)Add:张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。add和cfg文件中的shortcut功能一样。
Backbone中卷积层的数量:
每个ResX中包含1+2×X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2×1)+(1+2×2)+(1+2×8)+(1+2×8)+(1+2×4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
利用多尺度特征进行对象检测
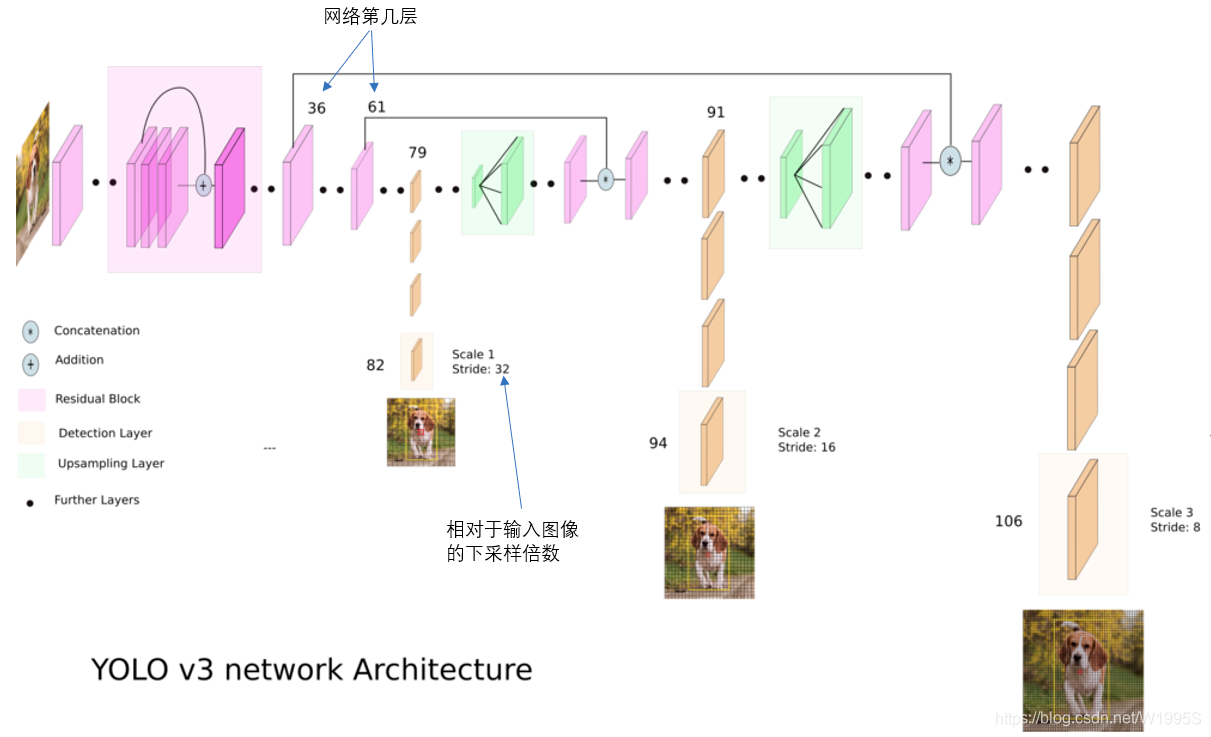
YOLO2曾采用passthrough结构来检测细粒度特征,在YOLO3更进一步采用了3个不同尺度的特征图来进行对象检测。
结合上图看,卷积网络在79层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。相比输入图像,这里用于检测的特征图有32倍的下采样。比如输入是416416的话,这里的特征图就是1313了。由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。
为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(Concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的对象。
最后,第91层特征图再次上采样,并与第36层特征图融合(Concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的对象。
9种尺度的先验框
随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLO2已经开始采用K-means聚类得到先验框的尺寸,YOLO3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13x13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52x52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。


感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

目标边界框预测
yolov2一样的。先验框的偏移量从每个cell的左上角开始计算,故中心坐标应该是图中红点,虚线框就是先验框,中心坐标(Cx,Cy),宽高(Pw,Ph)。预测值(tx,ty,tw,th),tx,ty通过σ 函数(就是sigmod函数),将中心坐标偏移量限制在红cell内,加上Cx,Cy就得到了最终预测的bounding box的中心坐标(bx,by),tw,th通过e指数进行扩展,得到最终预测的bounding box的宽高坐标(bw,bh)。

正负样本

针对每一个GT,分配一个bounding box prior,即分配一个正样本,有几个GT就有几个正样本。原则:与GT的IOU最大的bounding box prior最为正样本,如果存在IOU>某一阈值如0.5的bounding box prior,但不是最大,那么丢弃(非正非负),那么剩下的样本都是负样本。如果bounding box prior不是正样本,那么没有定位损失、没有类别损失、只有confidence score。
损失函数
YOLOv3的损失函数文章中写的很粗略,比如坐标损失采用的是误差的平方和,类别损失采用的是二值交叉熵。
YOLOv3的损失函数主要分为三个部分:目标定位偏移量损失
L
l
o
c
(
l
,
g
)
L_{loc}(l,g)
Lloc(l,g),目标置信度损失
L
c
o
n
f
(
o
,
c
)
L_{conf}(o,c)
Lconf(o,c)以及目标分类损失
L
c
l
a
(
O
,
C
)
L_{cla}(O,C)
Lcla(O,C)
 目标置信度可以理解为预测目标矩形框内存在目标的概率,目标置信度损失
L
c
o
n
f
(
o
,
c
)
L_{conf}(o,c)
Lconf(o,c)采用的是二值交叉熵损失(Binary Cross Entropy),其中
o
i
∈
{
0
,
1
}
o_{i}\in \{0,1\}
oi∈{0,1},表示预测目标边界框i中是否真实存在目标,0表示不存在,1表示存在。
c
i
^
\hat{c_{i}}
ci^表示预测目标矩形框i内是否存在目标的Sigmoid概率(将预测值
c
i
c_{i}
ci通过sigmoid函数得到)。
目标置信度可以理解为预测目标矩形框内存在目标的概率,目标置信度损失
L
c
o
n
f
(
o
,
c
)
L_{conf}(o,c)
Lconf(o,c)采用的是二值交叉熵损失(Binary Cross Entropy),其中
o
i
∈
{
0
,
1
}
o_{i}\in \{0,1\}
oi∈{0,1},表示预测目标边界框i中是否真实存在目标,0表示不存在,1表示存在。
c
i
^
\hat{c_{i}}
ci^表示预测目标矩形框i内是否存在目标的Sigmoid概率(将预测值
c
i
c_{i}
ci通过sigmoid函数得到)。

目标类别损失
L
c
l
a
(
O
,
C
)
L_{cla}(O,C)
Lcla(O,C)同样采用的是二值交叉熵损失(采用二值交叉熵损失的原因是,作者认为同一目标可同时归为多类,比如猫可归为猫类以及动物类,这样能够应对更加复杂的场景。但在本人实践过程中发现使用原始的多类别交叉熵损失函数效果会更好一点,原因是本人针对识别的目标都是固定归于哪一类的,并没有可同时归于多类的情况),其中
O
i
j
∈
{
0
,
1
}
O_{ij}\in \{0,1\}
Oij∈{0,1},表示预测目标边界框i中是否真实存在第j类目标,0表示不存在,1表示存在。
C
^
i
j
\hat{C}_{ij}
C^ij表示网络预测目标边界框i内存在第j类目标的Sigmoid概率(将预测值
C
i
j
C_{ij}
Cij通过sigmoid函数得到)

 目标定位损失
L
l
o
c
(
l
,
g
)
L_{loc}(l,g)
Lloc(l,g)采用的是真实偏差值与预测偏差值差的平方和,其中
l
^
\hat{l}
l^表示预测矩形框坐标偏移量(注意网络预测的是偏移量,不是直接预测坐标),
g
^
\hat{g}
g^表示与之匹配的GTbox与默认框之间的坐标偏移量,
(
b
x
,
b
y
,
b
w
,
b
h
)
(b^{x},b^{y},b^{w},b^{h})
(bx,by,bw,bh)为预测的目标矩形框参数,
(
c
x
,
c
y
,
p
w
,
p
h
)
(c^{x},c^{y},p^{w},p^{h})
(cx,cy,pw,ph)为默认矩形框参数,
(
g
x
,
g
y
,
g
w
,
g
h
)
(g^{x},g^{y},g^{w},g^{h})
(gx,gy,gw,gh)为与之匹配的真实目标矩形框参数,这些参数都是映射在预测特征图上的。
目标定位损失
L
l
o
c
(
l
,
g
)
L_{loc}(l,g)
Lloc(l,g)采用的是真实偏差值与预测偏差值差的平方和,其中
l
^
\hat{l}
l^表示预测矩形框坐标偏移量(注意网络预测的是偏移量,不是直接预测坐标),
g
^
\hat{g}
g^表示与之匹配的GTbox与默认框之间的坐标偏移量,
(
b
x
,
b
y
,
b
w
,
b
h
)
(b^{x},b^{y},b^{w},b^{h})
(bx,by,bw,bh)为预测的目标矩形框参数,
(
c
x
,
c
y
,
p
w
,
p
h
)
(c^{x},c^{y},p^{w},p^{h})
(cx,cy,pw,ph)为默认矩形框参数,
(
g
x
,
g
y
,
g
w
,
g
h
)
(g^{x},g^{y},g^{w},g^{h})
(gx,gy,gw,gh)为与之匹配的真实目标矩形框参数,这些参数都是映射在预测特征图上的。

对象分类softmax改成logistic
预测对象类别时不使用softmax,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。
输入映射到输出
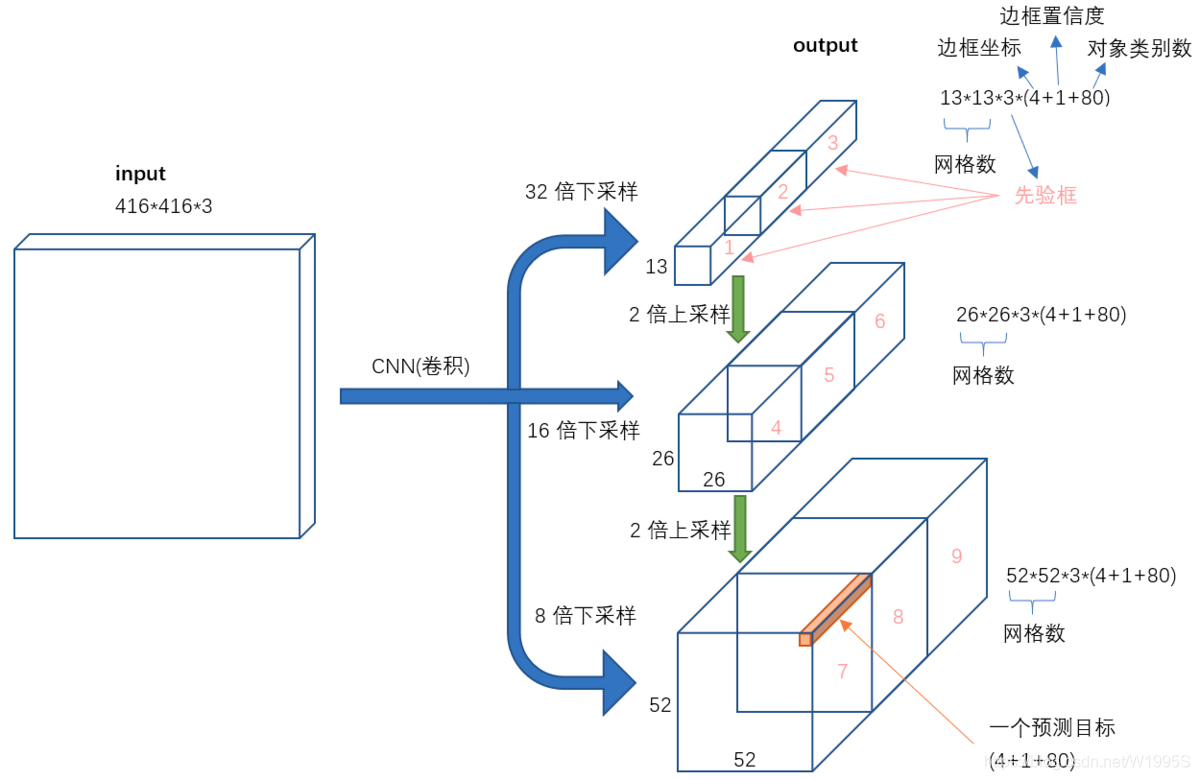
不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
我们看一下YOLO3共进行了多少个预测。对于一个416x416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13x13x3 + 26x26x3 + 52x52x3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
对比一下,YOLO2采用13 * 13 * 5 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。
小结
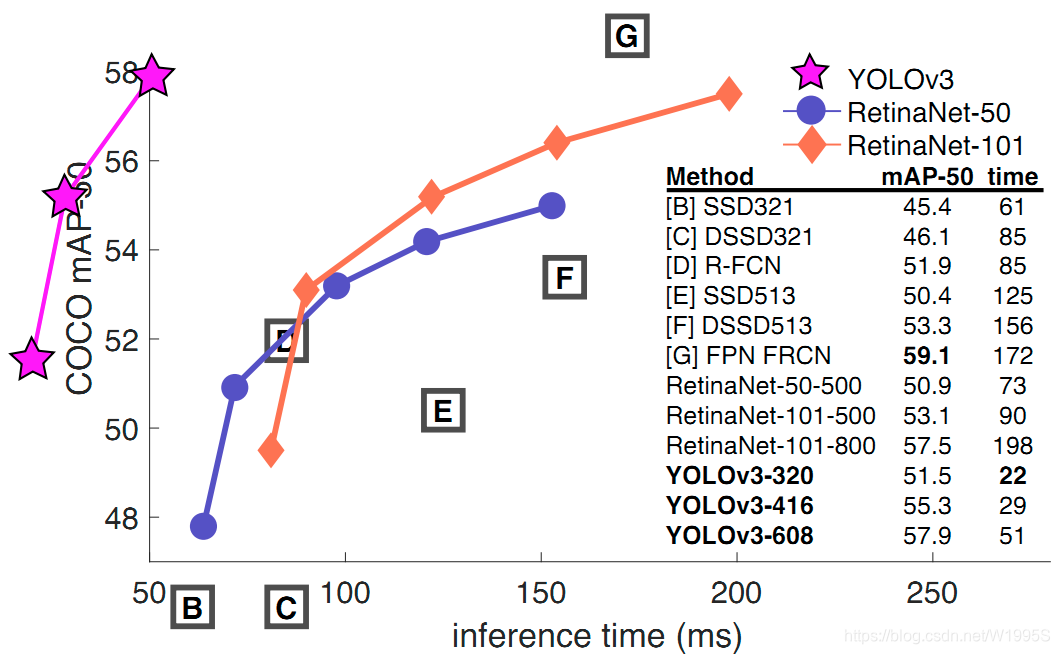
YOLO3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,提升了mAP及小物体检测效果。如果采用COCO mAP50做评估指标(不是太介意预测框的准确性的话),YOLO3的表现相当惊人,如下图所示,在精确度相当的情况下,YOLOv3的速度是其它模型的3、4倍。
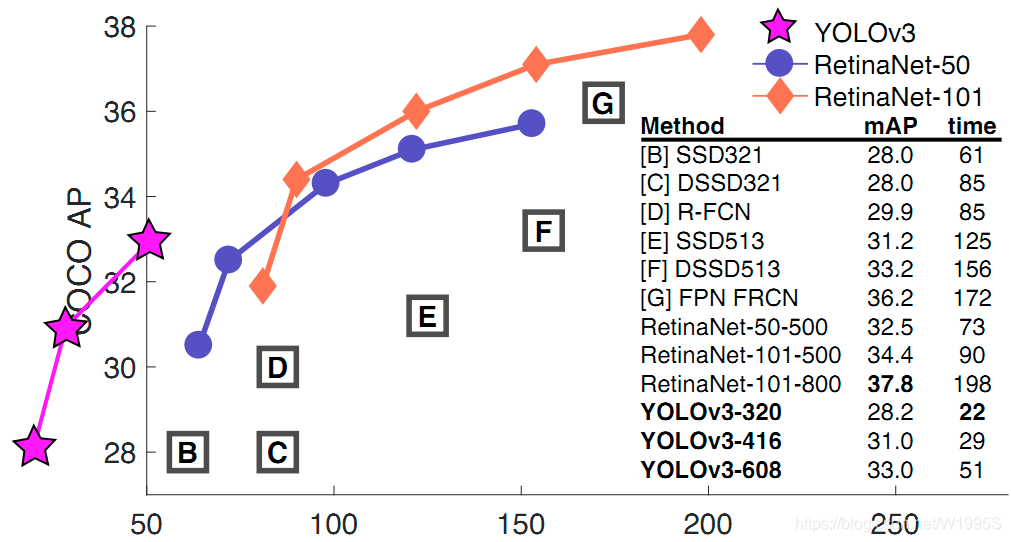
不过如果要求更精准的预测边框,采用COCO AP做评估标准的话,YOLO3在精确率上的表现就弱了一些。如下图所示。















 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









