









当大模型逐渐从云端走向本地,如何在有限硬件资源上实现高性能推理成为开发者关注的焦点。 Qwen3 系列模型凭借其创新架构与强大能力,成为本地部署的理想选择;而 VLLM 作为新一代推理引擎,以「高吞吐量、低显存占用」的特性重塑推理效率。两者结合,让开发者可轻松搭建专属自己的大语言模型服务!
读者你好,我是_Tex-mind_,下面就让我来带领你部署独属于你的本地Qwen3吧!
一、Qwen3 与 VLLM:为何是黄金组合?

作为通义千问第三代模型,Qwen3 在保持轻量化的同时,实现了能力维度的全面突破:
- 双模式智能切换:
- 思考模式:激活深度推理引擎,擅长复杂数学题求解(如竞赛级代数/几何问题)、长链式逻辑推理、专业代码生成(支持多语言框架,代码通过率超 90%)。
- 非思考模式:响应速度提升 30%,适合日常对话、信息检索、多轮闲聊,支持 8K 上下文流畅交互。
- 多语言与代理能力:
- 覆盖 119 种语言及方言,多语言翻译流畅自然,指令遵循准确率达 95% 以上。
- 内置工具调用解析器,可自动生成标准格式的函数调用(如 SQL 查询、API 调用),复杂任务完成度领先开源模型 20%。
VLLM:重新定义本地推理效率

VLLM 通过三大技术革新,让 80 亿参数模型在消费级硬件上跑出新高度:
- 动态批处理调度:基于优先级队列智能复用计算资源,吞吐量较传统框架提升 10 倍,支持数百并发请求。
- 量化与编译优化:
- 原生支持 4bit/8bit 量化(BitsAndBytes/AWQ),显存占用压缩至原生模型的 1/4。
- 集成 TorchCompile 与 CUDA 图技术,首次编译后推理速度提升 50%,生成 tokens 成本降低 30%。
- 开箱即用的服务能力:
- 内置 FastAPI 服务器,支持 OpenAI 兼容 API,10 分钟内可搭建对话接口。
- 提供工具调用、流式输出、多卡并行等企业级功能,无需二次开发。
二、部署实战:从环境搭建到服务启动
硬件与软件基础配置
-
硬件要求:
- 显卡:至少 24GB 显存的 NVIDIA GPU(如 RTX 4090/3090 Ti,实测用 VLLM API 部署 Qwen3-8B-4bit 显存占用约 20GB)。
-
软件安装:```
pip install vllm -
版本要求:
- VLLM的版本>=0.8.5,
- transformers版本>4.51.0
模型选择与获取
- 推荐模型:Qwen3-8B-unsloth-bnb-4bit
-
特性:4bit 量化版本,兼顾性能与精度,推理延迟较 16bit 模型仅增加 15%。
-
下载方式:```
pip install modelscope
modelscope download --model unsloth/Qwen3-8B-unsloth-bnb-4bit --local_dir ./目标文件夹./目标文件夹 改为自定义的文件夹名称(当前终端目录下)或者路径
-
启动命令与参数解析
VLLM_USE_MODELSCOPE=true vllm serve /home/me/models/Language/Qwen3-8B-bnb-4bit --enable-reasoning --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.2 --max-model-len 4096 --host 0.0.0.0 --port 8000
关键参数说明:
| 参数 | 作用 |
|---|---|
| /your/model/path | 自定义模型存放路径。 |
| enable-reasoning | 激活逻辑推理模块。 |
| reasoning-parser | 指定工具调用格式(DeepSeek R1) |
| gpu-memory-utilization | 防止多任务时显存溢出,单卡部署可设为 0.8-0.9 充分利用资源。 |
三、功能验证
服务验证:访问 http://localhost:8000/docs,可通过 Swagger 界面测试 /v1/chat/completions 接口,确认服务正常响应。
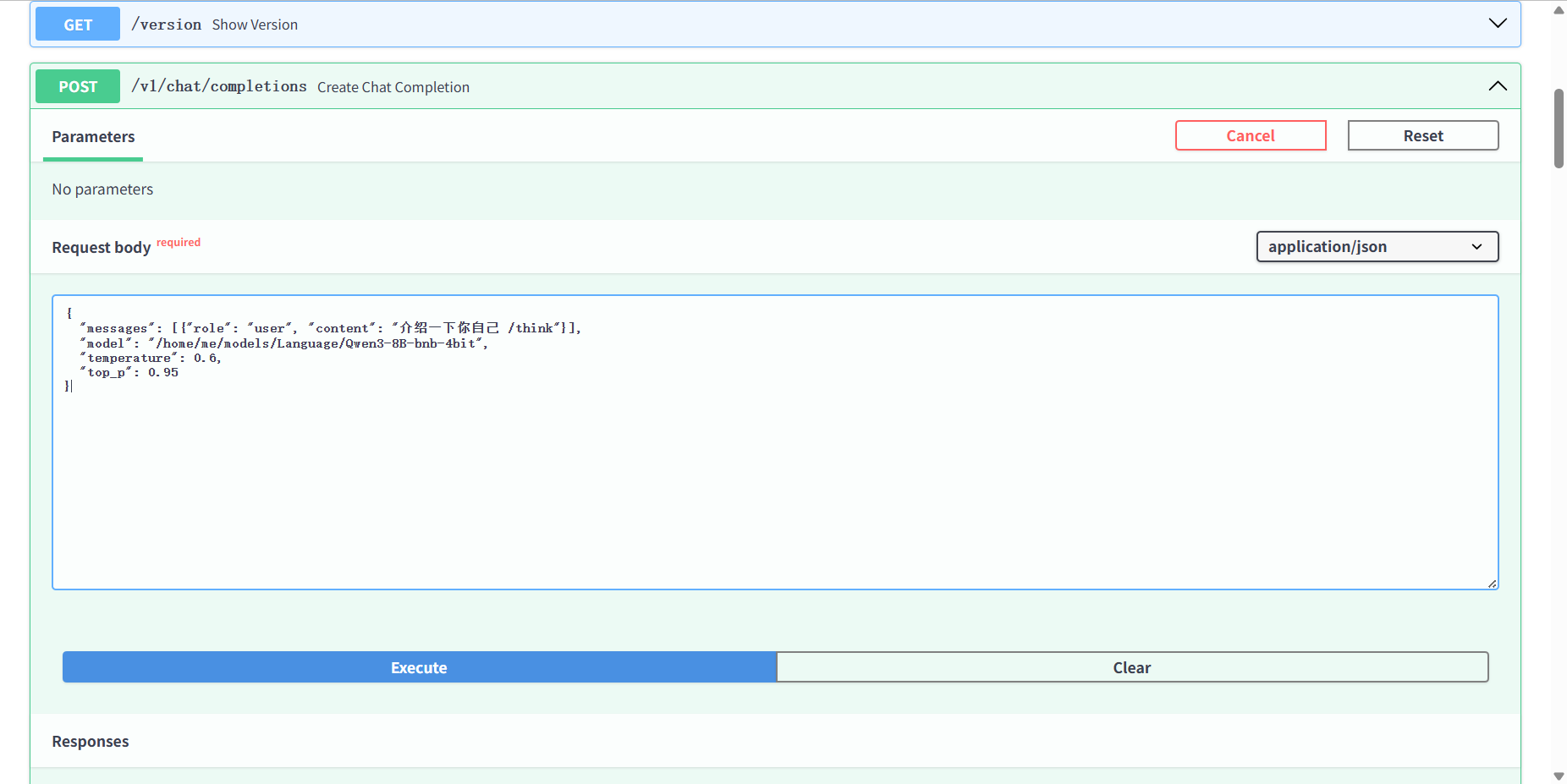
 点击该接口后在请求体中输出如下信息(注意模型路径替换成你的):
点击该接口后在请求体中输出如下信息(注意模型路径替换成你的):
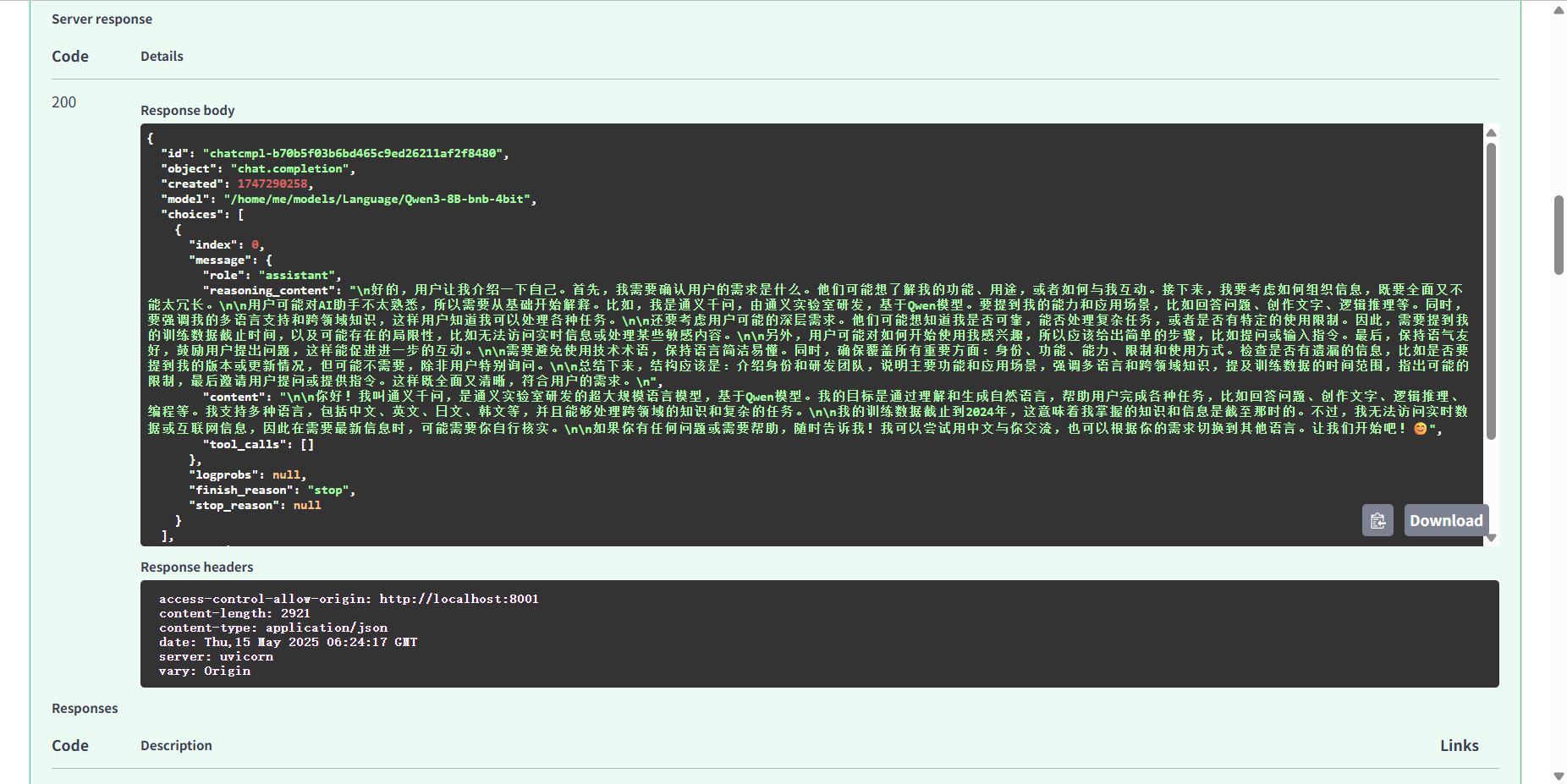
若是响应信息类似下方响应,则Qwen3模型推理服务已经成功本地部署!
或者通过Python代码方式进行接口测试:
# API方式调用
from openai import OpenAI
client = OpenAI(api_key="0",base_url="http://0.0.0.0:8000/v1")
messages = [{"role": "user", "content": "介绍一下你自己 /think"}]
result = client.chat.completions.create(messages=messages, model="/模型路径")
print(result.choices[0].message)
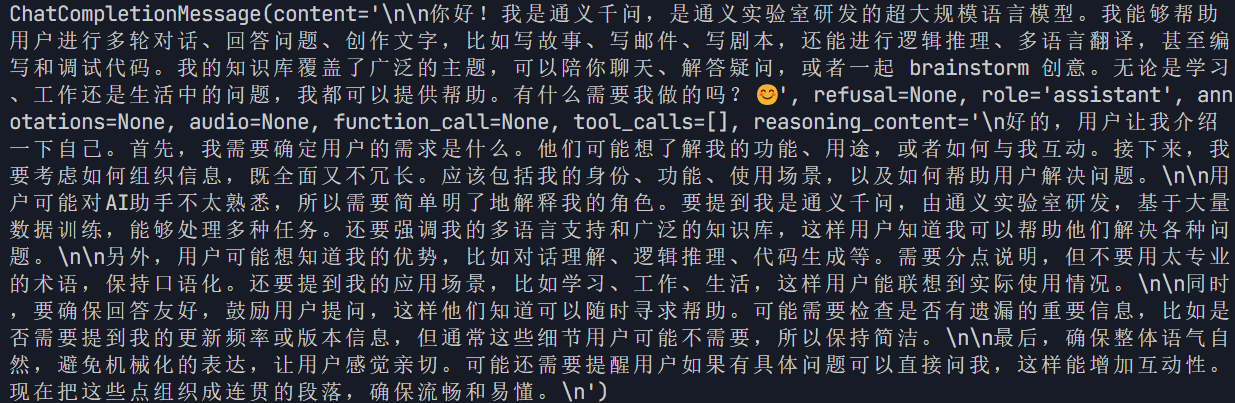
若成功打印模型回答及相关信息类似下方输出,则Qwen3模型推理服务已经成功部署!
四、性能观测
为什么会有额外的显存占用?
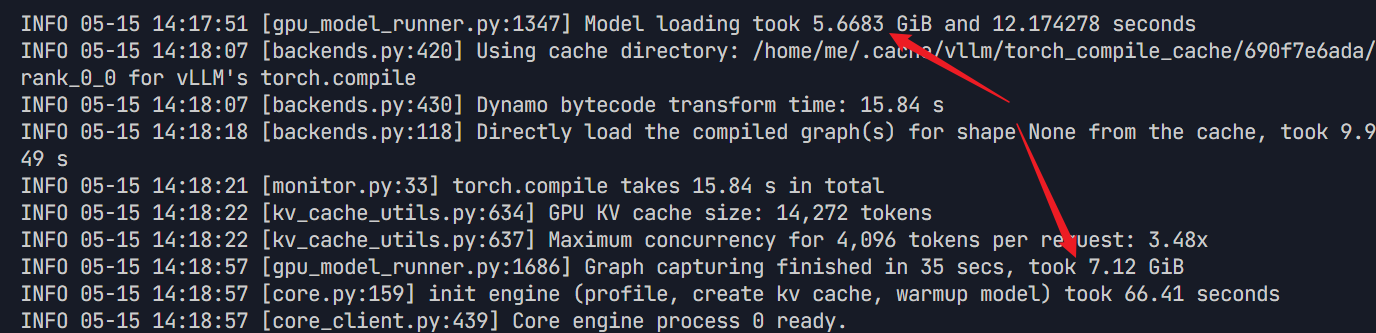
从运行截图中我们可以看出模型本身占用大概5.7GB,计算图缓存约7.12GB,总共约12.82GB,但使用 nvidia-smi 指令我们可以看到实际占用了约16.6GB显存,那多出来的部分被谁消耗了呢?

经过排查了推理,剩下的3GB左右的内存大概由预留的令牌缓存空间 、并发控制数据(0.5G)和vLLM 运行、FastAPI 服务器、PyTorch 依赖运行(2.5G)组成。至此找到了额外的显存占用的原因。
有没有更省显存的模型调用方式呢?
你好,读者,有的有的!如果不想持续化本地部署,而只是想单次小规模调用的话,官方也给出了标准Python代码以供测试:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen3-8B-bnb-4bit的模型路径"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Large language models (LLMs) are advanced artificial intelligence systems designed to understand and generate human-like text. Trained on vast amounts of diverse text data, they use deep learning techniques to recognize patterns, grasp context, and produce coherent responses. These models, often with billions of parameters, excel at tasks like answering questions, writing stories, coding, and translating languages. Their ability to mimic human communication has made them pivotal in fields like customer service, content creation, and research, marking a significant leap in AI's capacity to interact and collaborate with humans.给出这段英文的中文翻译/nothink"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
若控制台打印输出类似下方,则恭喜你已实现对Qwen3模型的成功调用!

那么这种形式的模型调用大概占用了多少显存呢?
是的,仅仅需要2.7GB左右的显存!这就是8B模型+BNB4bit量化带来的恐怖显存降耗能力,以这种形式进行模型调用,市面上绝大部分设备都能够轻松运行Qwen3模型!
希望你对本篇博客满意,我是_Tex-mind_,我们下期再见!
读者福利:知道你对AI大模型感兴趣,便准备了这套对AI大模型学习资料
对于0基础小白入门:
如果你是零基础小白,想快速入门AI大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:大模型从零基础到进阶的学习路线、100套AI大模型商业化落地方案,大模型全套视频教程。带你从零基础系统性的学好AI大模型!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









