







 本文探讨了如何从信号中学习时序逻辑公式,提出了rPSTL用于描述事件间的因果关系。通过搜索算法,同时学习结构和参数,实现分类和预测。算法在牧羊和生物网络案例中得到应用,揭示了时序逻辑在知识挖掘和系统理解中的潜力。
本文探讨了如何从信号中学习时序逻辑公式,提出了rPSTL用于描述事件间的因果关系。通过搜索算法,同时学习结构和参数,实现分类和预测。算法在牧羊和生物网络案例中得到应用,揭示了时序逻辑在知识挖掘和系统理解中的潜力。
前言:前面复现的两篇文章都是基于已知的公式模板进行的参数学习,然而在工程应用和科学研究时,不知道系统规律才是常态。对于一段信号,实现从一无所知到洞悉规律,才是时序逻辑学习终止需要达到的效果。
主要参考文献:
Kong, Z., Jones, A., Medina Ayala, A., Aydin Gol, E., & Belta, C. (2014, April 15). Temporal logic inference for classification and prediction from data. Proceedings of the 17th International Conference on Hybrid Systems: Computation and Control. https://doi.org/10.1145/2562059.2562146
文章目录
概览
这篇文章不仅提出了基于搜索算法的时序逻辑公式学习方法,不仅解决了参数学习、还解决了公式的结构发掘,并提出了rPSTL(Reactive Parameter Signal Temporal Logic)用来反映事件之间的因果关系。
流水账笔记
1 Introduction
以逆向工程学(Reverse Engineering)引出课题研究的背景。那么什么是逆向工程学呢?这里应用百度百科进行一下科普:
逆向工程(又称逆向技术),是一种产品设计技术再现过程,即对一项目标产品进行逆向分析及研究,从而演绎并得出该产品的处理流程、组织结构、功能特性及技术规格等设计要素,以制作出功能相近,但又不完全一样的产品。逆向工程源于商业及军事领域中的硬件分析。其主要目的是在不能轻易获得必要的生产信息的情况下,直接从成品分析,推导出产品的设计原理。
逆向工程可能会被误认为是对知识产权的严重侵害,但是在实际应用上,反而可能会保护知识产权所有者。例如在集成电路领域,如果怀疑某公司侵犯知识产权,可以用逆向工程技术来寻找证据。
那么使用时序逻辑来表征系统的特性有什么好处呢?对于一个系统,描述方法一般有两种:要么用动态模型来进行建模,但是在只有信号而对系统一无所知的情况下,建模非常困难;要么在统计范畴上描述系统特性,但这些统计信息的作用有限,往往不能达到研究者的预期。时序逻辑就相当于中和了这两种极端,可以在不预先知道系统特性的情况下,对系统进行更精确的描述。
本文提出了时序逻辑公式推理的两个应用场景:
- 将公式推理的结果作为分类器,将系统的行为进行划分,因此非常适用于异常监控领域。
- 从数据中挖掘新的知识
本文提出的算法可以同时得到STL结构和参数。文章对公式本身定义了偏序(前面接触过这个概念,但是都是针对信号的),其目的是让搜索更高效有序;并且将鲁棒度(robustness degree)做为优化目标,将问题转化为了优化问题。
2 Signal and Parametric Signal Temporal Logic
这一部分所有的文章就大同小异了,这里介绍一些前面的博客没有讲过的重要概念。
语义等价 Semantically Equivalent
列举满足公式 ϕ 1 \phi_1 ϕ1和 ϕ 2 \phi_2 ϕ2的所有信号组成集合,如果这两个公式对应的信号集合是一样的,那么两条公式再语义上等价。
鲁棒度 Robustness Degree
之前的笔记中将robustness和tightess进行过对比。一个公式越鲁棒,能满足要求的信号集合越大。
有向距离 Signed Distance
定义一个点到集合的最近距离,点在集合外距离为正,反之为负。这里提出这个度量有什么意义呢?应该是想用距离来近似表示鲁棒度,给了一篇文献进行证明。
Fainekos, G. E., & Pappas, G. J. (2009). Robustness of temporal logic specifications for continuous-time signals. Theoretical Computer Science, 410(42), 4262–4291. https://doi.org/10.1016/j.tcs.2009.06.021
3 Problem Statement
3.1 Motivating Example
提出了一个牧场赶牛的例子。这里直接给了PSTL公式,这让人有些不解,不是要做结构学习的吗?为什么一上来先把公式给了?
3.2 Reactive PSTL
定义
这里提出了一个新概念——响应STL,就是可以反映因果关系的STL公式,比常规的STL多了一个表示因果关系的“
⇒
\Rightarrow
⇒”,后文中把
φ
c
\varphi_c
φc或
ϕ
c
\phi_c
ϕc称为因式,
φ
e
\varphi_e
φe或
ϕ
e
\phi_e
ϕe称为果式。
φ
:
:
=
⋄
[
τ
1
,
τ
2
)
(
φ
c
⇒
φ
e
)
\varphi::=\diamond_{[\tau_1,\tau_2)}(\varphi_c\Rightarrow\varphi_e)
φ::=⋄[τ1,τ2)(φc⇒φe)
上面的式子表示,在
[
τ
1
,
τ
2
)
[\tau_1,\tau_2)
[τ1,τ2)时间内,总会有一个时刻,信号满足
φ
c
\varphi_c
φc,接着满足
φ
e
\varphi_e
φe. 这里先留一个疑问,
φ
e
\varphi_e
φe是紧接着
φ
c
\varphi_c
φc满足呢还是在之后的任意时间呢?
这里最小的子公式只包含线性谓词。所谓线性谓词,我猜测应该是只包含“ < \lt <”或" ≥ \geq ≥"的谓词语句吧。一会儿再查查确定一下。
限制
有一些事件是不能用响应式的方法来进行描述的,比如concurrent eventuality(不能区分因果关系),nested “always eventually”(没有事件作为trigger条件)。
3.3 Problem Description
分类与预测
这里要区分分类与预测的概念了,引用原文:
- s i ⊨ ϕ d e s s_i \models \phi_{des} si⊨ϕdes iff p i = 1 p_i = 1 pi=1 (or s i ⊨ ϕ u n d s_i \models \phi_{und} si⊨ϕund iff p i = 0 p_i = 0 pi=0) ∀ i = 1 , . . . , N ∀i = 1, . . . , N ∀i=1,...,N (classification).
- ϕ d e s \phi_{des} ϕdes (or ϕ u n d \phi_{und} ϕund) can be used to determine pi from a prefix of si ∀ i = 1 , . . . , N ∀i = 1, . . . , N ∀i=1,...,N (prediction).
联系下文,这里分类指的是根据果式来区分信号、预测是指根据因式来判断果式是否会发生。具体是求 ϕ d e s \phi_{des} ϕdes还是 ϕ u n d \phi_{und} ϕund取决于具体应用。
因此,本文中因式和果式是分开来求的,文中先利用信号的末段学习出一条能够达到区分效果的果式。
学习果式
将学习问题转化为优化问题,优化目标为下面的函数:
J
e
(
φ
,
v
)
=
1
N
∑
i
=
1
N
l
(
p
i
,
r
(
s
i
,
ϕ
v
)
)
+
λ
∣
∣
ϕ
v
∣
∣
J_e(\varphi,v)=\frac{1}{N}\sum\limits_{i=1}^{N} l(p_i,r(s_i,\phi_v))+\lambda ||\phi_v||
Je(φ,v)=N1i=1∑Nl(pi,r(si,ϕv))+λ∣∣ϕv∣∣
下面来理解一下这个目标函数:函数的输入有PSTL公式 φ \varphi φ和赋值 v v v,因此此式的目的是已知参数模板找到最佳的参数组合;等式右边的损失函数 l l l将鲁棒度和信号标签作为输入,应该是表示误分类率,最后惩罚了 ϕ v \phi_v ϕv的长度,以避免公式过长造成过拟合。
学习因式
这里同样也是一个优化问题:
J
c
(
φ
,
v
)
=
1
N
∑
i
=
1
N
l
(
p
i
,
r
(
s
i
,
ϕ
v
)
)
+
λ
∣
∣
ϕ
v
∣
∣
J_c(\varphi,v)=\frac{1}{N}\sum\limits_{i=1}^{N} l(p_i,r(s_i,\phi_v))+\lambda ||\phi_v||
Jc(φ,v)=N1i=1∑Nl(pi,r(si,ϕv))+λ∣∣ϕv∣∣
唯一不同的是这里
φ
\varphi
φ值的就是整条rPSTL公式,
φ
=
⋄
[
0
,
τ
1
)
(
φ
c
⇒
φ
d
e
s
,
e
)
\varphi=\diamond_{[0,\tau_1)}(\varphi_c \Rightarrow \varphi_{des,e})
φ=⋄[0,τ1)(φc⇒φdes,e),其中
φ
d
e
s
,
e
\varphi_{des,e}
φdes,e是上一小节中的计算结果。
4 Properties of rPSTL
接下来介绍了rPSTL相关的一些重要性质,如:阶数、偏序关系、DAG等。
4.1 Partial Orders Over rSTL and rPSTL
那么什么是偏序?偏序的定义能够将任意两种食物进行比较。平时的“>”、"<"就是最简单的偏序关系。当然,我们可以在你想得到的任意范畴内定义偏序关系,例如:如果我们唯成绩论地定义数学成绩的偏序,就可以得到“小明 ⪯ \preceq ⪯小红”的结论。
那么STL的偏序怎么定义呢?
- 对于STL:如果信号满足 ϕ 1 \phi_1 ϕ1,那么信号必然满足 ϕ 2 \phi_2 ϕ2,则称 ϕ 1 ⪯ S ϕ 2 \phi_{1} \preceq_{S} \phi_{2} ϕ1⪯Sϕ2
- 对于PSTL:对于任意一组相同的赋值,如果信号满足 φ 1 \varphi_1 φ1,那么信号必然满足 φ 2 \varphi_2 φ2,则称 φ 1 ⪯ P φ 2 \varphi_{1} \preceq_{P} \varphi_{2} φ1⪯Pφ2
接着作者证明了前面定义的关系满足偏序关系的反身性、传递性与非对称性。
提出了 ⪯ P \preceq_{P} ⪯P的性质:
- φ 1 ∧ φ 2 ⪯ P φ j ⪯ P φ 1 ∨ φ 2 \varphi_{1} \wedge \varphi_{2} \preceq_{P} \varphi_{j} \preceq_{P} \varphi_{1} \vee \varphi_{2} φ1∧φ2⪯Pφj⪯Pφ1∨φ2 for j = 1 , 2 j=1,2 j=1,2
- □ [ τ 1 , τ 2 ) ℓ ⪯ P ⋄ [ τ 1 , τ 2 ) ℓ \square_{\left[\tau_{1}, \tau_{2}\right)} \ell \preceq_{P} \diamond_{\left[\tau_{1}, \tau_{2}\right)} \ell □[τ1,τ2)ℓ⪯P⋄[τ1,τ2)ℓ, where ℓ \ell ℓ is a linear predicate;
- For two rPSTL formulae, φ 1 : = ⋄ [ τ 1 , τ 2 ) ( φ c 1 ⇒ φ e 1 ) \varphi_{1}:=\diamond_{\left[\tau_{1}, \tau_{2}\right)}\left(\varphi_{c 1} \Rightarrow \varphi_{e 1}\right) φ1:=⋄[τ1,τ2)(φc1⇒φe1) and φ 2 : = ⋄ [ τ 1 , τ 2 ) ( φ c 2 ⇒ φ e 2 ) , φ 1 ⪯ P φ 2 \varphi_{2}:=\diamond_{\left[\tau_{1}, \tau_{2}\right)}\left(\varphi_{c 2} \Rightarrow \varphi_{e 2}\right), \varphi_{1} \preceq_{P} \varphi_{2} φ2:=⋄[τ1,τ2)(φc2⇒φe2),φ1⪯Pφ2 iff φ c 2 ⪯ P \varphi_{c 2} \preceq_{P} φc2⪯P φ c 1 \varphi_{c 1} φc1 and φ e 1 ⪯ P φ e 2 \varphi_{e 1} \preceq_{P} \varphi_{e 2} φe1⪯Pφe2.
前面两条比较intuitive,这里就不再做解释了。最后一个式子可以理解为:如果因式约束更严格,果式约束更宽泛,则整条公式的描述范围更广。因为可以把蕴含逻辑理解为 ¬ φ c ∨ φ e \neg \varphi_{c} \vee \varphi_{e} ¬φc∨φe,仅当 φ c \varphi_c φc为真, φ e \varphi_e φe为假时,整个式子才为假。
作者这里通过这种偏序关系的传递,将公式的指代范围更广(inclusive)。
4.2 DAG and Robustness Degree
DAG表示偏序关系
本文用有向直连图(DAG)的边来表示公式间的偏序关系。以下就是一个DAG的例子,由于公式按照偏序关系进行了排序。
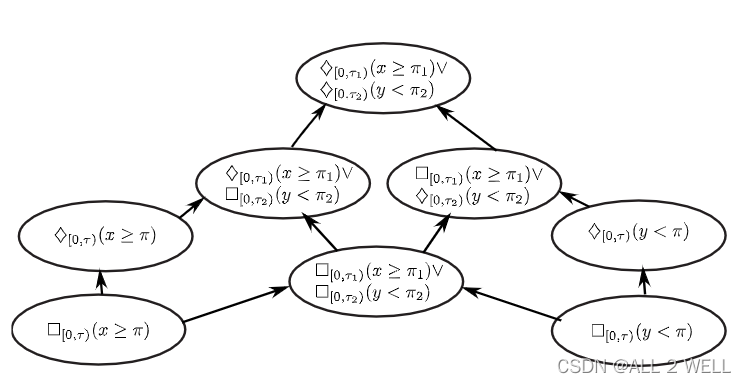
这里还提到DAG的顶部元素
⊤
\top
⊤和底部元素
⊥
\perp
⊥,具体作用是什么还不知道。
偏序关系与鲁棒度的关系
接下来证明了鲁棒度和STL(PSTL)的偏序关系式成正比的。这里先用这个结论,证明一会儿再解释。
基本思路
由于公式是按照偏序关系组织在DAG中的,所以我们可以从最exclusive的公式,也就是always引导的STL出发,沿着包含关系增加的方向向下遍历,直到找到一个恰好满足区分要求的节点。
The search starts from the most exclusive formula and follows directed edges until a satisfying formula is found.
那么怎么判断公式是否符合“区分”要求呢?在每个结点求解这个公式的最佳赋值方式,如果最佳赋值都不足以使鲁棒性为负时,说明需要继续沿着DAG看别的结点。因此,最后找到的是鲁棒度刚好稍微大于0的结点,即tightest解。
接下来对于: φ 3 : = φ 1 ∧ φ 2 \varphi_3:=\varphi_1\land\varphi_2 φ3:=φ1∧φ2, φ 4 : = φ 1 ∨ φ 2 \varphi_4:=\varphi_1\lor\varphi_2 φ4:=φ1∨φ2。显然 φ 3 \varphi_3 φ3要比 φ 1 \varphi_1 φ1或 φ 2 \varphi_2 φ2更加exlusive,所以在寻找undesirable行为时更加具有优势;反之, φ 4 \varphi_4 φ4要更加Inclusive,所以在寻找desirable行为时更具优势。这一段的叙述对于后面的算法作用不大。
5 Solution
接下来就开始描述具体分类算法了,预测算法就是在这个基础上把
φ
e
\varphi_e
φe推理出来的结果带进去,然后选择误分类率为0的节点:

重点是理解代码中的
L
i
s
t
List
List和
G
i
\mathcal{G}_i
Gi存储的是什么信息。
其中 G i \mathcal{G}_i Gi存储的是公式最大长度为 i i i的DAG,例如前面的DAG就是一个 G 2 \mathcal{G}_2 G2。经过PruningAndGrowing或DAGInitialization后,图中的每个节点应该存储了以下信息:PSTL公式模板、参数变量列表、相邻节点的偏序关系。 在后面的Maintenance函数中,DAG的每个节点还要增加参数幅值、误分类率以及代价函数值。
L i s t List List存储的是新长出的节点的顺序关系。这个变量的设置有什么作用呢?
- 避免重复遍历上次循环遍历过的节点,只保存本次循环新增的节点。
- 排序基于一个启发式的idea:父节点的平均代价函数越小,那么此节点的代价函数也越小,如果先check这个节点,那么可能提前结束循环。这一思想并没有进行证明,但是这里对代码本身的影响不大(因为即使不排序其实也能达到效果)。
6 Implementation and Case Studies
本文的算法已经集成到matlab的TempLogIn工具包里了。
6.1 Herding Example
这个案例中,是用rSTL来区分自己放牧的牛会不会跑到别人家的草场上去。
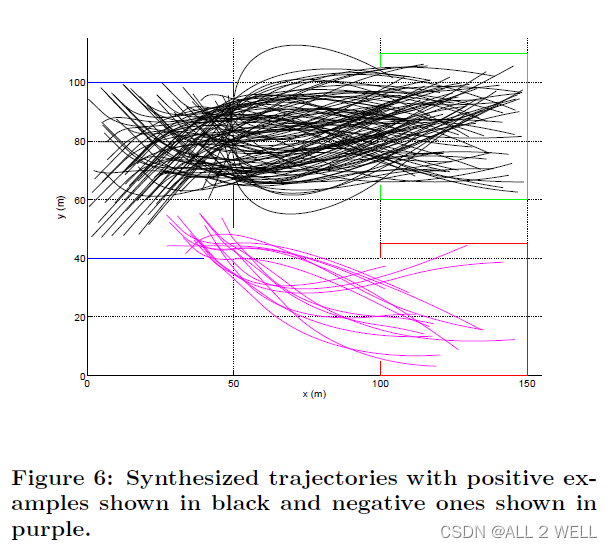
说实话这里的case选取我不是很理解,你用速度加速度来判断我也就认了,毕竟这两个数字和出口的选择关系是隐性的。但直接用坐标来判断好像过于直观了。
这里的计算效率也不算高的样子,优化算法用的是模拟退火,用了100个长度为200的信号样本,分类用了305.5s,预测用了643.1s。这里真的很想吐槽以下作者的文法,就不能说人话吗?
On a Mac with a 3.06 GHz Intel Core 2 Duo CPU and 6 GB RAM, the classification took 305.5 seconds, and the prediction took 643.1 seconds with n, the number of samples generated in simulated annealing, equal to 100, and m, the maximum number of data point per signal, equal to 200.
6.2 Biological Network
这里case举得还挺有意思,利用rSTL得出了生物网络中两种化学物质的浓度关系,因此可以把这一类应用看作是知识挖掘。
优化过程同样使用了模拟退火算法,用了100个长度为600的信号样本,分类用了494.0s,预测用了693.7s。
7 Final Remarks and Future Work
未来方向
- 复杂应用:系统重构(看懂离职老员工写的代码到底写了些啥)、知识挖掘(生物网络系统的输出反映了什么规律)、精准建模(知道网络有什么用处了以后对模型进行修改)
- 尝试更复杂的公式
- 扩大算法支持的数据规模
- 非监督场景
思考与记录
- 这已经不是第一次看这篇文献了,阅读完前两篇文献后对本文的理解清晰了很多,名词上的障碍基本上消除了(*^ ▽ ^*)
- 应用场景可以进一步改进:还是比较适合应用于人类看不太明白的数据,用这些数据来实现监督或者知识挖掘,否则用时序公式缺乏说服性(有种杀鸡用牛刀的感觉)。
- 前面两篇参数学习的文献提到过tightness和robustness的trade-off在这里体现在了代价函数里。

















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









