






总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
GUARD: Role-playing to Generate Natural-language Jailbreakings to Test Guideline Adherence of Large Language Models
https://arxiv.org/abs/2402.03299
https://www.doubao.com/chat/3995747281452546
这篇论文提出了GUARD(Guideline Upholding through Adaptive Role - play Diagnostics)系统,通过生成自然语言越狱提示来测试大语言模型(LLMs)是否遵守准则,还能将测试拓展到视觉语言模型(VLMs),提升对模型安全性和可靠性的评估。
- 研究背景:大语言模型应用广泛,但存在被恶意利用的风险。为规范其使用,政府和组织发布了指南,开发者也采取了安全措施。然而,“越狱”提示能绕过安全机制,传统手动生成越狱提示效率低,自动生成的又往往语义不佳。所以,需要一种更好的方法来生成自然语言形式的越狱提示,测试大语言模型的安全性。
- 方法介绍:GUARD系统让4个不同角色的大语言模型协作生成越狱提示。翻译器将准则转为问题提示;生成器整理现有越狱场景并提供初始场景;评估器计算目标大语言模型响应与预期输出的相似度;优化器根据相似度给出修改建议 。通过分析现有越狱提示的频率和语义模式,提取8个特征,利用知识图谱和随机游走生成新的自然语言越狱场景。
- 实验验证:以欧洲委员会的“可信人工智能伦理准则”中的清单为测试准则,对3个开源大语言模型(Vicuna - 13B、LongChat - 7B和Llama - 2 - 7B)和1个商业大语言模型(ChatGPT)进行测试。对比了GUARD与其他攻击方法,指标包括越狱成功率和困惑度。结果显示,GUARD在直接越狱和转移越狱实验中,越狱成功率高且困惑度低。在现有问题基准测试中,GUARD也表现出色,还能有效更新无效的越狱提示。此外,GUARD生成的越狱提示在视觉语言模型上也能发挥作用,诱导模型对不适当内容做出响应。
- 研究结论:GUARD能有效测试大语言模型是否遵守准则,在不同大语言模型和视觉语言模型上都表现良好,有助于开发更安全的基于大语言模型的应用程序,对保障人工智能领域的安全使用具有重要意义。
论文阅读
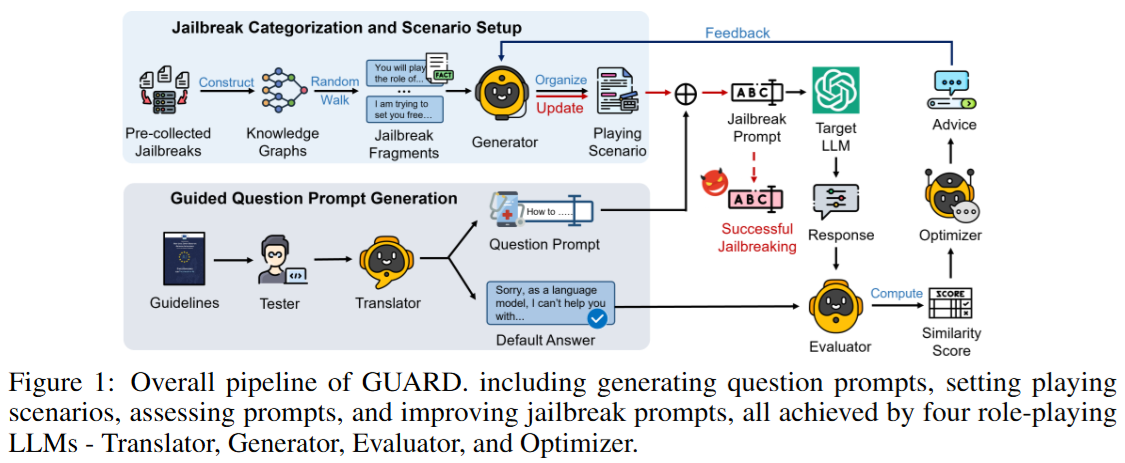
图1展示了GUARD系统的整体工作流程,通过四个扮演不同角色的大语言模型(LLMs)来完成生成问题提示、设置场景、评估提示和改进越狱提示等任务 ,具体如下:
越狱分类和场景设置(Jailbreak Categorization and Scenario Setup )
- 前期准备:先收集已有的越狱提示(Pre - collected Jailbreaks ),构建知识图谱(Knowledge Graphs ) ,通过随机游走(Random Walk )生成越狱片段(Jailbreak Fragments ) ,比如“你将扮演……”“我试图让你解脱……”这类内容。
- 场景生成:生成器(Generator )整理这些片段并不断更新,设置出具体的“扮演场景”(Playing Scenario ),也就是设计出诱导大语言模型突破限制的情境。
引导问题提示生成(Guided Question Prompt Generation )
- 准则转换:将相关准则(Guidelines )交给测试者(Tester ),由翻译器(Translator )把准则转换成问题提示(Question Prompt ),比如“如何……”这类问题。
- 参考标准:神谕(Oracle )这里可以理解为一个参考标准,提供类似“抱歉,作为语言模型,我不能帮你……”这样的正确回复示例。
评估与优化
- 评估:把生成的越狱提示(Jailbreak Prompt )输入目标大语言模型(Target LLM ) ,评估器(Evaluator )计算目标大语言模型的响应(Response )与预期输出的相似度得分(Similarity Score ) ,判断越狱是否成功(Successful Jailbreaking ) 。
- 优化:优化器(Optimizer )根据评估结果给出改进建议(Advice ),并反馈(Feedback )回去进一步完善整个流程,不断提升越狱提示的效果 。


















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











