







 本文介绍了一种新颖的YOLO-World方法,通过区域-文本对的预训练和RepVL-PAN模型,实现了高效的零样本目标检测。文章详细阐述了训练过程和实验结果,展示了YOLO-World在大规模数据集上的优越性能和潜在的实际应用价值。
本文介绍了一种新颖的YOLO-World方法,通过区域-文本对的预训练和RepVL-PAN模型,实现了高效的零样本目标检测。文章详细阐述了训练过程和实验结果,展示了YOLO-World在大规模数据集上的优越性能和潜在的实际应用价值。
文章目录
前言
YOLO系列检测器已将自己确立为高效实用的工具。然而,它们依赖于预定义和训练的物体类别,这在开放场景中限制了它们的适用性。针对这一限制,作者引入了YOLO-World,这是一种创新的方法,通过视觉语言建模和在大型数据集上的预训练,将YOLO与开集检测能力相结合。
具体来说,作者提出了一种新的可重参化的视觉语言路径聚合网络(RepVL-PAN)和区域文本对比损失,以促进视觉和语言信息之间的交互。作者的方法在以零样本方式检测具有很好的效果。
paper:https://arxiv.org/pdf/2401.17270.pdf
github:https://github.com/AILab-CVC/YOLO-World
一、简介
Yolo-World的主要贡献可以概括为三个方面:
1)提出YOLO-World,一个前沿的open vocabulary目标检测器,它具有高效率,适用于实际应用场景。
2)作者提出了一个可重参数化的视觉-语言PAN模块,用以连接视觉和语言特征,并针对YOLO-World设计了一套区域文本对比预训练方案。
3)YOLO-World在大规模数据集上的预训练展示了强大的zero-shot性能,在LVIS上达到35.4 AP的同时,还能保持52.0 FPS的速度。预训练的YOLO-World可以轻松适应多种下游任务。此外,YOLO-World的预训练权重和代码将开源,以促进更多实际应用。
二、方法
早期的工作遵循标准OVD(Open-Vocabulary Object Detection)设置,在基类上训练检测器并评估新的(未知的)类。尽管如此,这种开放词汇设置可以评估检测器检测和识别新对象的能力,但它仍然局限于开放场景,并且由于在有限的数据集和词汇上进行训练,缺乏对其他领域的泛化能力。
其实对于zero-shot目标检测,目前已有不少研究,如GLIP,GroundingDINO,但是这些检测器使用如Swin-L等backbone导致计算成本较大。相比之下,YOLO World旨在通过实时推理和更容易的下游应用程序部署实现高效的开放词汇表对象检测。

1. 预训练公式:区域-文本对
传统的YOLO系列检测器,其训练label为bounding box和对应的物体类别,但YOLO-World中定义的label为一个区域-文本对,即bounding box和对应物体的文本描述。 文本可以是类别名称、名词短语或对象描述。
(PS:文章中提到的区域-文本对(region-text)指边框和描述,图像-文本对(image-text)指整张图像和对应的文本描述)
2.模型架构与训练
YOLO-WORLD的backbone采用了YOLO的现有结构,语言模型采用了CLIP模型。使用文本和图像特征中的特征通过区域到文本对比学习连接到 RepVL-PAN。YOLO检测将图像-文本数据集成到区域-文本对中。
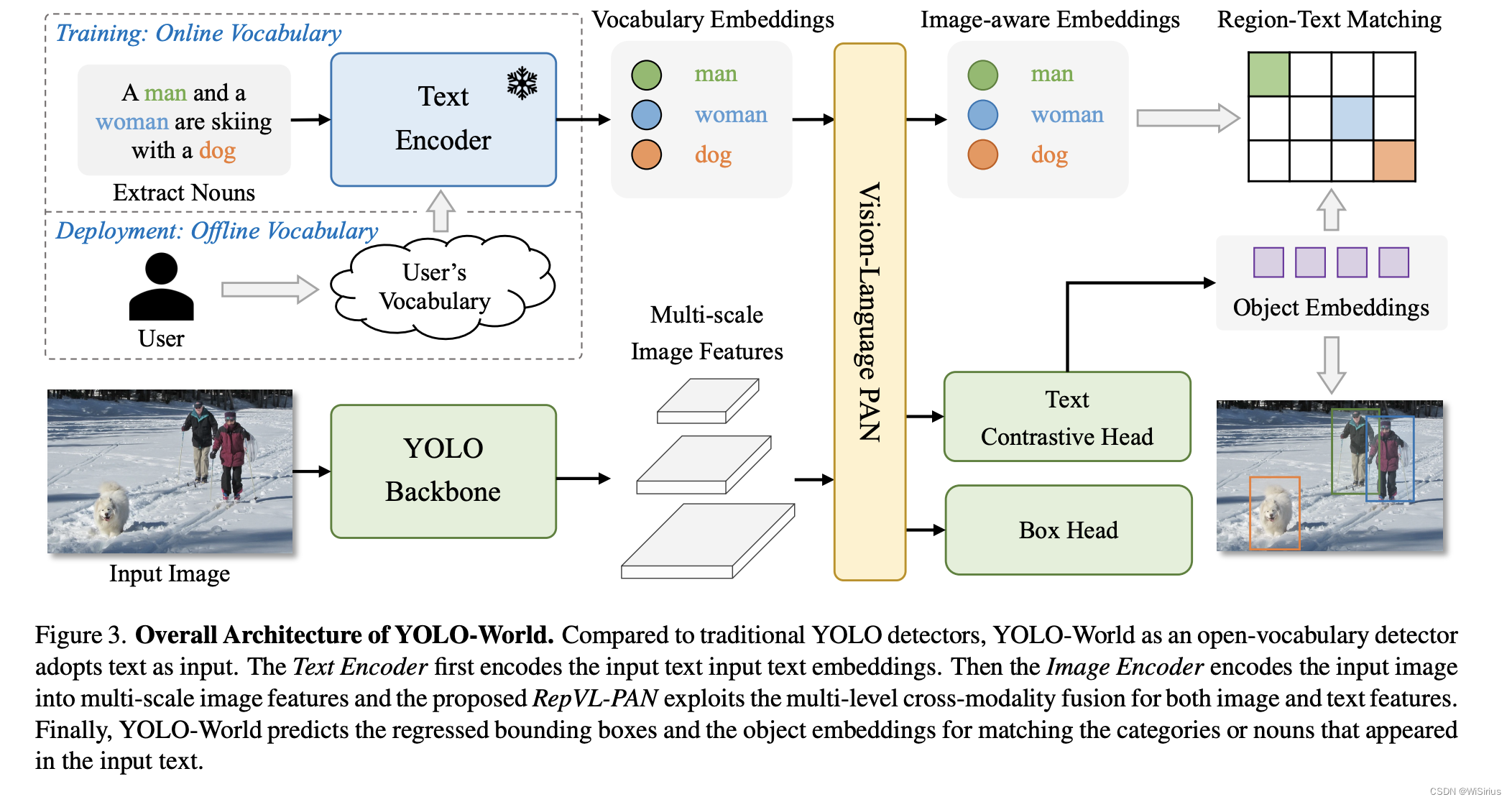
其实可以发现YOLO-WORLD的训练就是和CLIP一样的对比学习,通过特征匹配完成训练。
接下来,分别描述一下模型的几个主要部分:
1)YOLO Detector
模型基于 Ultralytics YOLOv8, 使用DarkNet作为backbone, 使用一个PAN网络用语聚合多尺度特征,最后通过head获得box回归值和object embedding。
2)Text Encoder
使用CLIP 预训练的 Transformer 文本编码器。(想详细了解CLIP可以参考我之前的blog——多模态:CLIP)。
3)Text Contrastive Head
根据以前的工作,作者依然选择解耦头的设计,如图模型结构图,用俩个3×3卷积作为box head用于回归边框值。因为要计算目标-文本的相似度,所以提出文本对比头。为了稳定区域-文本训练,目标编码e和文本编码w使用L2-Norm。
——这部分的计算方式和CLIP的计算相似度的方式相同,都是通过矩阵相乘。
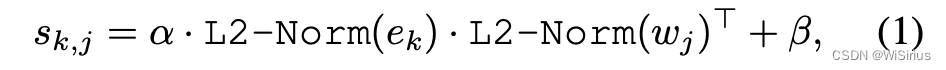
4)Training with Online Vocabulary
在训练过程中,为每个包含4幅图像的马赛克样本构建一个在线词汇表T。具体来说,对马赛克图像中涉及的所有positive名词进行采样,并从相应的数据集中随机采样一些negative名词。每个镶嵌样本的词汇表最多包含M个名词,默认情况下M设置为80。
5)Inference with Offline Vocabulary
在推理阶段,为了进一步提高效率,提出了一种离线词汇的提示-然后检测策略。用户可以定义一系列自定义提示,其中可能包括标题或类别。然后,我们利用文本编码器对这些提示进行编码,并获得离线词汇embeding。离线词汇表允许避免每次输入的计算,并提供根据需要调整词汇表的灵活性。
6)Re-parameterizable Vision-Language PAN
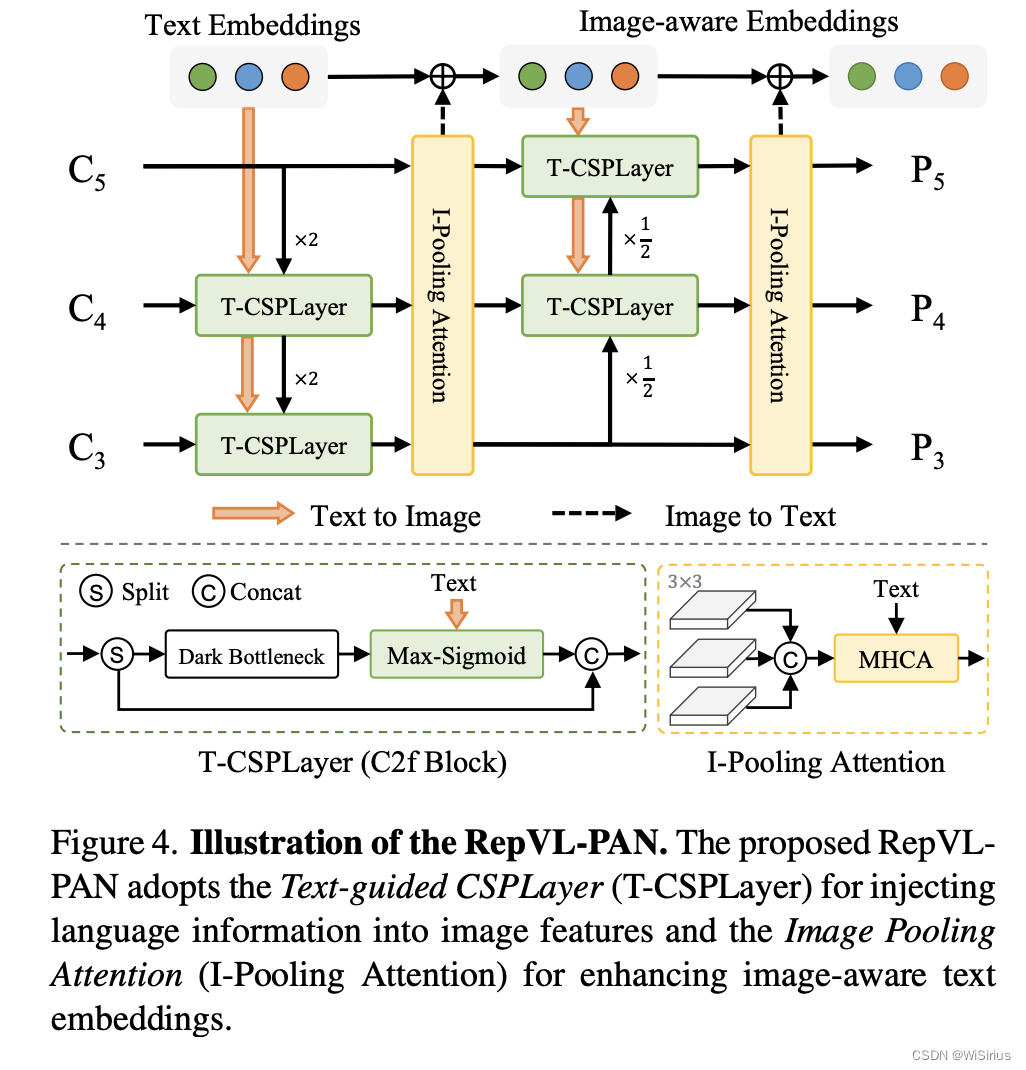
RepVL-PAN结构如上图,可以发现其实整体架构和之前的金字塔结构是一样的,包含自顶向下和自底向上的路径。区别在于提出了文本引导的CSPLayer(T-CSPLayer)和图像池化注意力(I-Pooling Attention),以进一步增强图像特征与文本特征之间的交互,这可以提高开集能力的视觉语义表示。
Max-Sigmoid: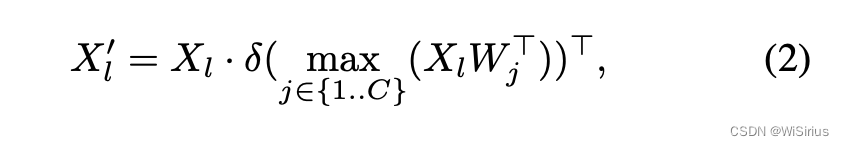
X
l
X_l
Xl代表第l个尺度的特征,
W
j
W_j
Wj表示文本编码。其实这个公式很好理解,就是X和W计算相似度矩阵,然后得到一组向量,这个向量其实就是文本编码中每个词语的相似度,将它作为权重乘上特征,相当于对每个通道的特征进行加权。
I-Pooling Attention:
为了利用图像感知信息增强文本嵌入,通过提出I-Pooling Attention聚合图像特征以更新文本嵌入。不是直接在图像特征上使用交叉注意力,而是利用多尺度特征上的最大池化来获得3×3个区域,从而产生总共27个patch
X
X
X。然后通过以下方式更新文本嵌入:
可以这么理解,Max-Sigmoid就是将文本聚合到图像中,I-Pooling Attention就是将图像聚合到文本中所设计的两种运算。
三、训练方案
给定mosic样本I和文本T,YOLO World输出K个对象预测(k个边框回归和k个相似度得分)。首先构建了区域-文本对的对比损失Lcon(个人感觉和CLIP的对比损失差不多)。此外,采用IoU损失和dfl(distributed focal loss)损失(yolov8中的损失)进行边界盒回归,总训练损失定义为:
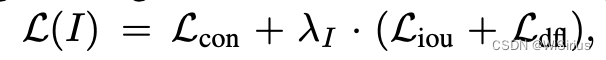
区域文本对和图像文本对的获取:
使用图像文本数据进行伪标记。文章提出了一种自动标记方法来生成区域-文本对,而不是直接使用图像-文本对进行预训练。
具体而言,标记方法包括三个步骤:(1)名词短语提取:我们首先利用n-gram算法从文本中提取名词短语;(2) 伪标记:采用预先训练的开放词汇检测器,例如GLIP,为每个图像的给定名词短语生成伪框,从而提供粗略的区域文本对。(3) 过滤:使用预先训练的CLIP来评估图像-文本对和区域-文本对的相关性,并过滤低相关性的伪注释和图像。我们通过结合诸如非最大抑制(NMS)之类的方法来进一步过滤冗余边界框。建议读者参考附录中的详细方法。使用上述方法,使用821k个伪注释对来自CC3M的246k个图像进行采样和标记。
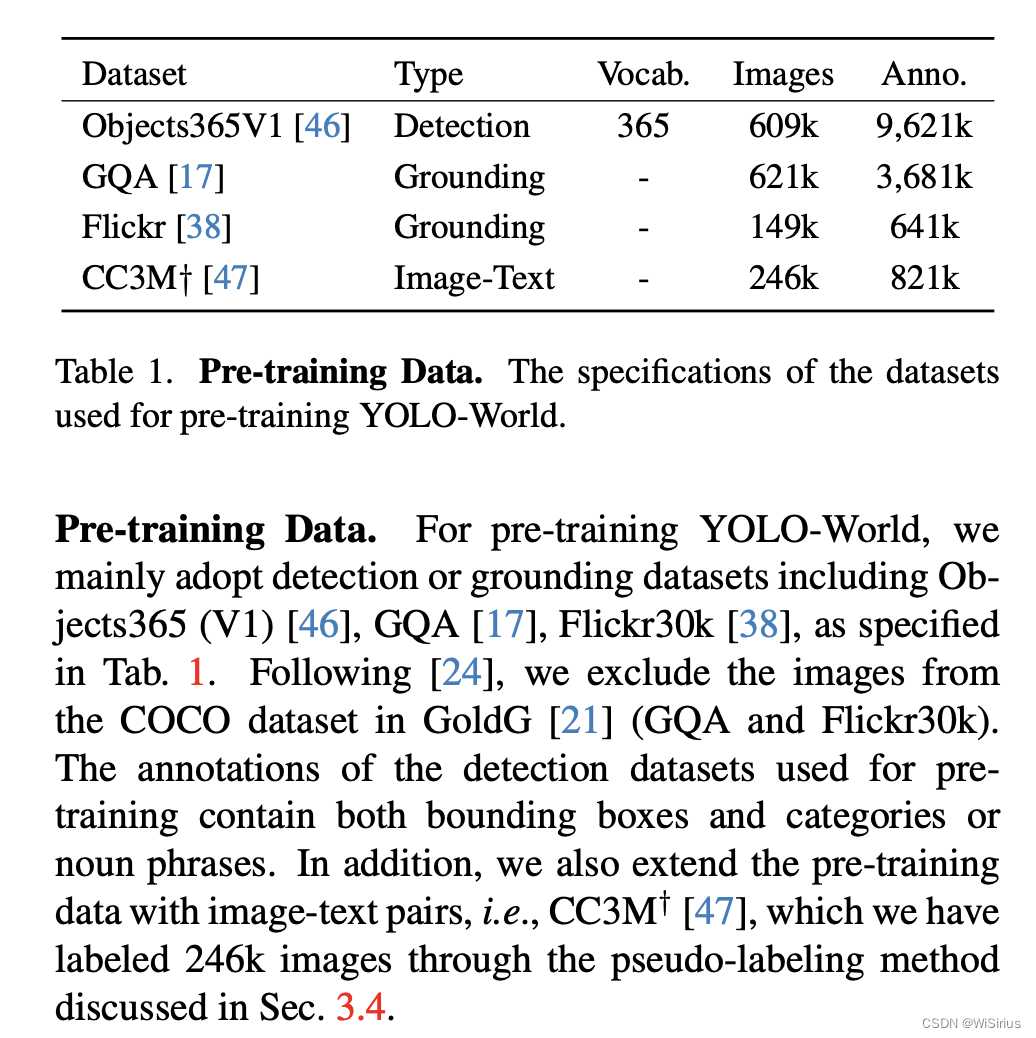
四、实验结果

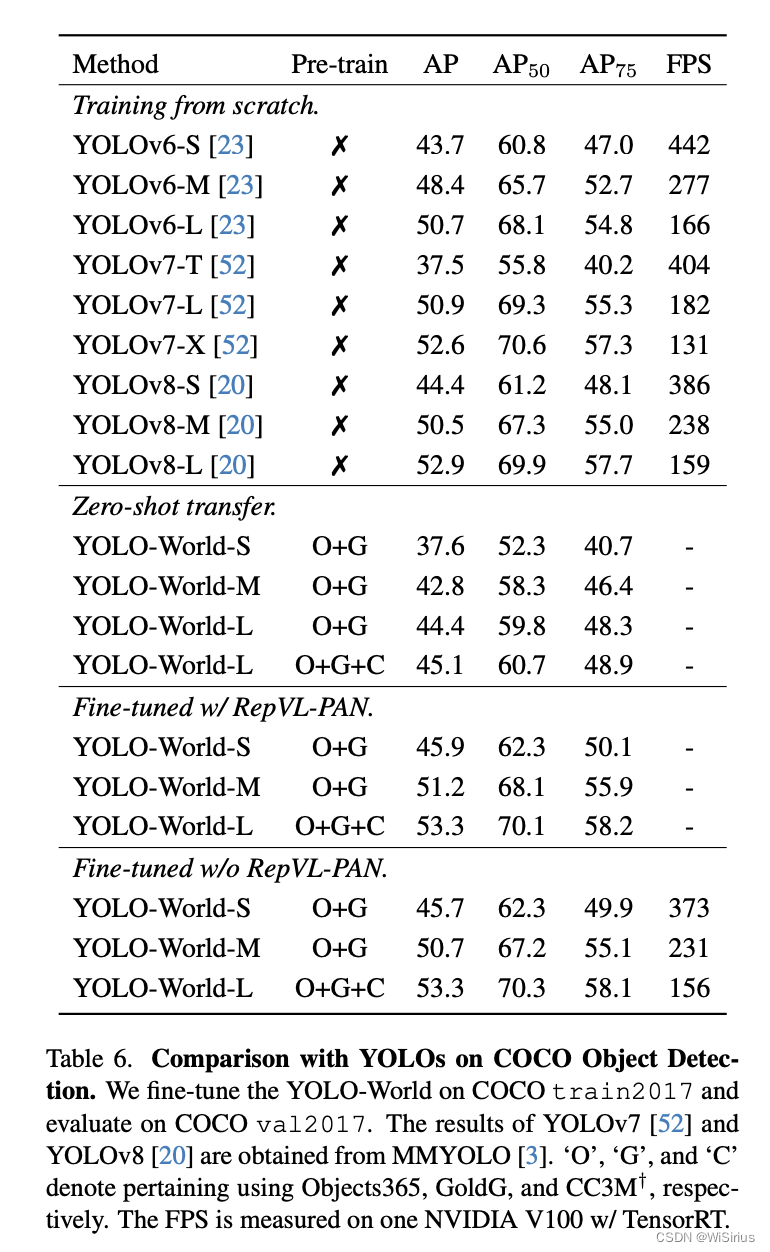
关于实验部分YOLO-WORLD做了大量消融研究,并探讨了微调实验,在预训练模型上(使用预训练数据集获得的模型)使用COCO等进行微调,效果如下:
总结
YOLO-world的到来将逐渐改变传统目标检测的框架,未来的目标检测将逐渐成为zero-shot任务。目标检测也将变得高度智能化。未来可期!!!


















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









