









 论文介绍了一种新方法DMD,通过将扩散模型转化为一步生成器,实现高效且高质量的图像生成,实现在ImageNet和COCO数据集上的优异性能。DMD通过分布匹配和回归损失优化,克服了传统方法的局限,有望推动图像生成技术的发展。
论文介绍了一种新方法DMD,通过将扩散模型转化为一步生成器,实现高效且高质量的图像生成,实现在ImageNet和COCO数据集上的优异性能。DMD通过分布匹配和回归损失优化,克服了传统方法的局限,有望推动图像生成技术的发展。
论文解读 One-step Diffusion with Distribution Matching Distillation
关注微信公众号: DeepGo
源码地址: https://tianweiy.github.io/dmd/
论文地址: https://arxiv.org/abs/2311.18828
这篇论文介绍了一种新的图像生成方法,名为分布匹配蒸馏(DMD),将扩散模型转换为一步生成器,极大地加快了图像生成速度,同时保持了图像质量。通过最小化近似的KL散度和简单的回归损失,DMD能够在保持图像质量的同时实现极速的生成效率,即在现代硬件上以20 FPS的速度生成图像。实验表明,DMD在ImageNet 64×64上的FID达到了2.62,在零样本COCO-30k上达到了11.49 FID,与稳定扩散模型相当,但速度快了几个数量级。此外,DMD还探讨了与分类器无关指导的结合使用,进一步提高了生成图像的质量。尽管DMD在一步生成模型的效率和质量方面取得了显著进步,但作者也指出了其局限性,包括与更细致的扩散采样路径相比,仍有质量差距,以及性能受限于教师模型的能力。作者期待通过蒸馏更先进的模型和引入变化的指导尺度,进一步提升模型性能和灵活性。

图1展现了一下和目前SOTA方法的对比: 基线稳定扩散(Stable Diffusion, SD):生成每张图像需要约250毫秒。扩散匹配蒸馏(Diffusion Matching Distillation, DMD):生成每张图像仅需约90毫秒。强调了DMD技术生成图像的速度比SD快得多,同时还在图像生成速度和质量上的潜在优势。(猜一下哪个是该论文中的方法的效果?文末给答案)
问题和挑战
这篇论文致力于解决将扩散模型转化为快速单步图像生成器的问题,挑战在于如何在最小化生成图像质量损失的同时提高生成速度。一句话概括:论文提出了一种分布匹配蒸馏(DMD)方法,通过精确匹配单步生成器和扩散模型的分布,显著提升了生成效率,同时保持了图像的高质量。
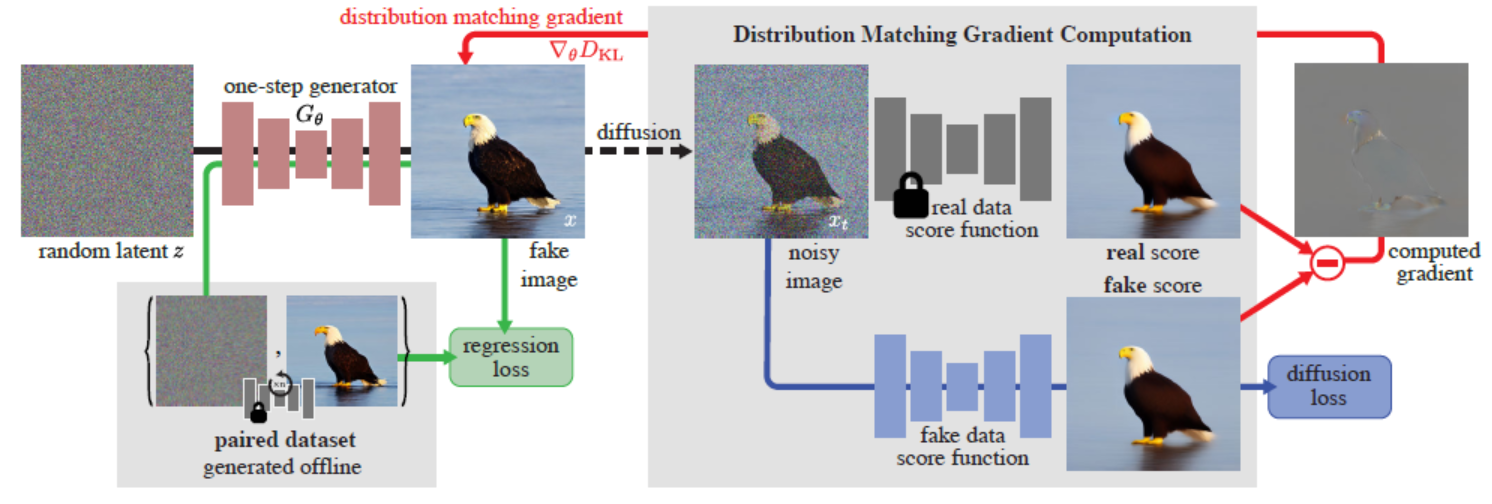
训练框架图:作者训练单步生成器
(
G
θ
)
( G_{\theta} )
(Gθ) 来将随机噪声
(
z
)
( z )
(z) 映射成真实图像。为了匹配多步扩散模型的采样输出,作者预先计算了一系列噪声-图像对,并偶尔从该集合中加载噪声,同时施加LPIPS回归损失,以确保作者的单步生成器与扩散输出之间的一致性。此外,作者还为假图像提供分布匹配梯度
(
∇
θ
D
K
L
)
( \nabla_{\theta} D_{KL} )
(∇θDKL),以增强其真实感。作者向假图像注入随机量的噪声,并将其传递给两个扩散模型:一个在真实数据上预训练的模型,另一个持续在假图像上以扩散损失进行训练,以获取其去噪版本。去噪得分(在图中以平均预测表示)指示了使图像变得更真实或更假的方向。这两者之间的差异表示向着更高真实性和较低虚假感的方向,这一差异被反向传播到单步生成器中。
方法概述
分布匹配蒸馏(Distribution Matching Distillation,简称DMD)的目标是将给定的预训练扩散去噪器(基模型)转化为能够快速生成高质量图像的“一步”图像生成器,而不需要耗时的迭代采样过程。这一过程包括两个主要部分:预训练基模型与一步生成器的构建,以及分布匹配损失的定义。
预训练基模型和一步生成器
-
预训练基模型 作者的蒸馏过程假设给定了一个预训练的扩散模型 μ base \mu_{\text{base}} μbase。扩散模型被训练以逆转一个高斯扩散过程,该过程逐渐向来自真实数据分布 x 0 ∼ p real x_0 \sim p_{\text{real}} x0∼preal 的样本添加噪声,将其转化为白噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I),经过 T T T 时间步骤,作者使用 T = 1000 T = 1000 T=1000。作者将扩散模型表示为 μ base ( x t , t ) \mu_{\text{base}}(x_t, t) μbase(xt,t)。从一个高斯样本 x T x_T xT 开始,模型迭代地去噪一个运行中的噪声估计 x t x_t xt,基于时间步 t ∈ 0 , 1 , . . . , T − 1 t \in {0, 1, ..., T-1} t∈0,1,...,T−1(或噪声水平)来产生目标数据分布的样本。扩散模型通常需要10到100步骤来产生逼真的图像。作者的推导使用扩散的均值预测形式来简化,但与 ϵ \epsilon ϵ-预测同样有效,仅需变量变换。作者的实现使用来自EDM和Stable Diffusion的预训练模型。
-
一步生成器 ( G θ G_{\theta} Gθ) 的架构与基模型的扩散去噪器相同,但不包括时间条件。在训练前,一步生成器的参数 ( θ \theta θ) 以基模型为初始化,即 G θ ( z ) = μ base ( z , T − 1 ) , ∀ z G_{\theta}(z) = \mu_{\text{base}}(z, T-1), \forall z Gθ(z)=μbase(z,T−1),∀z。
分布匹配损失(Distribution Matching Loss)
理想情况下,作者希望快速生成器能产生与真实图像无法区分的样本。受到ProlificDreamer[78]的启发,作者通过最小化真实图像分布 p real p_{\text{real}} preal与假图像分布 p fake p_{\text{fake}} pfake之间的Kullback–Leibler (KL) 散度来实现这一目标,得Eq. (1):
D K L ( p fake ∥ p real ) = E x ∼ p fake [ log p fake ( x ) p real ( x ) ] = E z ∼ N ( 0 , I ) , x = G θ ( z ) − [ log p real ( x ) − log p fake ( x ) ] D_{KL}(p_{\text{fake}} \parallel p_{\text{real}}) = \mathbb{E}_{x \sim p_{\text{fake}}} \left[ \log \frac{p_{\text{fake}}(x)}{p_{\text{real}}(x)} \right] = \mathbb{E}_{z \sim \mathcal{N}(0,I), x=G_{\theta}(z)} -\left[ \log p_{\text{real}}(x) - \log p_{\text{fake}}(x) \right] DKL(pfake∥preal)=Ex∼pfake[logpreal(x)pfake(x)]=Ez∼N(0,I),x=Gθ(z)−[logpreal(x)−logpfake(x)]
直接计算这些概率密度来估计此损失通常是不可行的,但作者只需要对 θ \theta θ 的梯度来通过梯度下降法训练作者的生成器。
梯度更新使用近似分数
针对生成器参数的Eq. (1)的梯度,导出Eq. (2):
∇ θ D K L = E z ∼ N ( 0 , I ) , x = G θ ( z ) [ − ( s real ( x ) − s fake ( x ) ) ∇ θ G θ ( z ) ] \nabla_{\theta}D_{KL} = \mathbb{E}_{z \sim \mathcal{N}(0,I), x=G_{\theta}(z)} \left[ -(s_{\text{real}}(x) - s_{\text{fake}}(x)) \nabla_{\theta} G_{\theta}(z)\right] ∇θDKL=Ez∼N(0,I),x=Gθ(z)[−(sreal(x)−sfake(x))∇θGθ(z)]
其中 s real ( x ) = ∇ x log p real ( x ) s_{\text{real}}(x) = \nabla_{x}\log p_{\text{real}}(x) sreal(x)=∇xlogpreal(x) 和 s fake ( x ) = ∇ x log p fake ( x ) s_{\text{fake}}(x) = \nabla_{x}\log p_{\text{fake}}(x) sfake(x)=∇xlogpfake(x) 分别是各自分布的分数。直观上, s real s_{\text{real}} sreal 将 x x x 移向 p real p_{\text{real}} preal 的模式,而 − s fake -s_{\text{fake}} −sfake 则将它们分散开。
通过对数据分布加入随机高斯噪声的不同标准差,作者创建了一系列“模糊”的分布,这些分布在整个空间上都是全支撑的,因此重叠,使得Eq. (2)中的梯度有定义。然后,Score-SDE 显示,训练好的扩散模型近似了扩散分布的分数函数。
作者的策略是使用一对扩散去噪器来模拟经过高斯扩散后的真实和假分布的分数。作者分别将这些定义为 s real ( x t , t ) s_{\text{real}}(x_t, t) sreal(xt,t) 和 s fake ( x t , t ) s_{\text{fake}}(x_t, t) sfake(xt,t)。扩散样本 x t ∼ q ( x t ∣ x ) x_t \sim q(x_t|x) xt∼q(xt∣x) 通过在扩散时间步 t t t 向生成器输出 x = G θ ( z ) x = G_{\theta}(z) x=Gθ(z) 添加噪声得到:
q t ( x t ∣ x ) ∼ N ( α t x , σ t 2 I ) q_t(x_t | x) \sim \mathcal{N}(\alpha_t x, \sigma_t^2 I) qt(xt∣x)∼N(αtx,σt2I)
其中 α t \alpha_t αt 和 σ t \sigma_t σt 来自扩散噪声时间表。
真实分数由基扩散模型的训练图像固定,因此作者使用预训练扩散模型的固定副本 μ base ( x , t ) \mu_{\text{base}}(x, t) μbase(x,t) 来模拟它的分数。
假分数随着作者生成的样本分布在训练过程中的变化而动态调整。作者从预训练的扩散模型 μ base \mu_{\text{base}} μbase 初始化假扩散模型,并在训练过程中通过最小化标准去噪目标来更新参数 ϕ \phi ϕ:
L ϕ denoise = ∣ ∣ μ ϕ fake ( x t , t ) − x 0 ∣ ∣ 2 L_{\phi}^{\text{denoise}} = ||\mu_{\phi}^{\text{fake}}(x_t, t) - x_0||^2 Lϕdenoise=∣∣μϕfake(xt,t)−x0∣∣2
作者的最终近似分布匹配梯度通过用两个扩散模型在扰动样本 x t x_t xt 上定义的分数替换Eq. (2)中的精确分数,并对扩散时间步取期望得到, x 0 x_0 x0 就是对应的真实样本。
回归损失和最终目标
分布匹配目标在前一节已经介绍,它对于 t ≫ 0 t \gg 0 t≫0,即当生成样本被大量噪声损坏时,是很好定义的。然而,对于少量噪声, s real ( x t , t ) s_{\text{real}}(x_t, t) sreal(xt,t) 通常变得不可靠,因为 p real ( x t , t ) p_{\text{real}}(x_t, t) preal(xt,t) 趋于零。此外,由于得分 ∇ x log ( p ) \nabla_x \log(p) ∇xlog(p) 对概率密度函数 p p p 的缩放是不变的,优化容易受到模式坍塌/丢失的影响,其中假分布为一部分模式分配更高的总密度。为了避免这一点,作者使用额外的回归损失来确保所有模式都被保留。这个损失衡量了给定相同输入噪声时,生成器输出与基模型输出之间的点对点距离。通过构建随机高斯噪声图像 z z z 和基模型的确定性输出 y y y 的配对数据集,可以计算回归损失 L reg = E [ ℓ ( G θ ( z ) , y ) ] L_{\text{reg}} = E[\ell(G_{\theta}(z), y)] Lreg=E[ℓ(Gθ(z),y)],其中 ℓ \ell ℓ 是距离函数,本文中使用了Learned Perceptual Image Patch Similarity (LPIPS)。
最终目标 是 D K L + λ reg L reg D_{KL} + \lambda_{\text{reg}} L_{\text{reg}} DKL+λregLreg,其中 λ reg \lambda_{\text{reg}} λreg 是一个超参数,控制回归损失的权重。通过自动微分计算 ∇ θ D K L \nabla_{\theta}D_{KL} ∇θDKL 和 ∇ θ L reg \nabla_{\theta}L_{\text{reg}} ∇θLreg 的梯度,分别应用于未配对的假样本(用于分布匹配梯度)和配对样本(用于回归损失)。
DMD通过这种方式训练一步生成器,不仅快速生成高质量的图像,而且有效地桥接了生成模型与预训练扩散模型之间的性能差距。
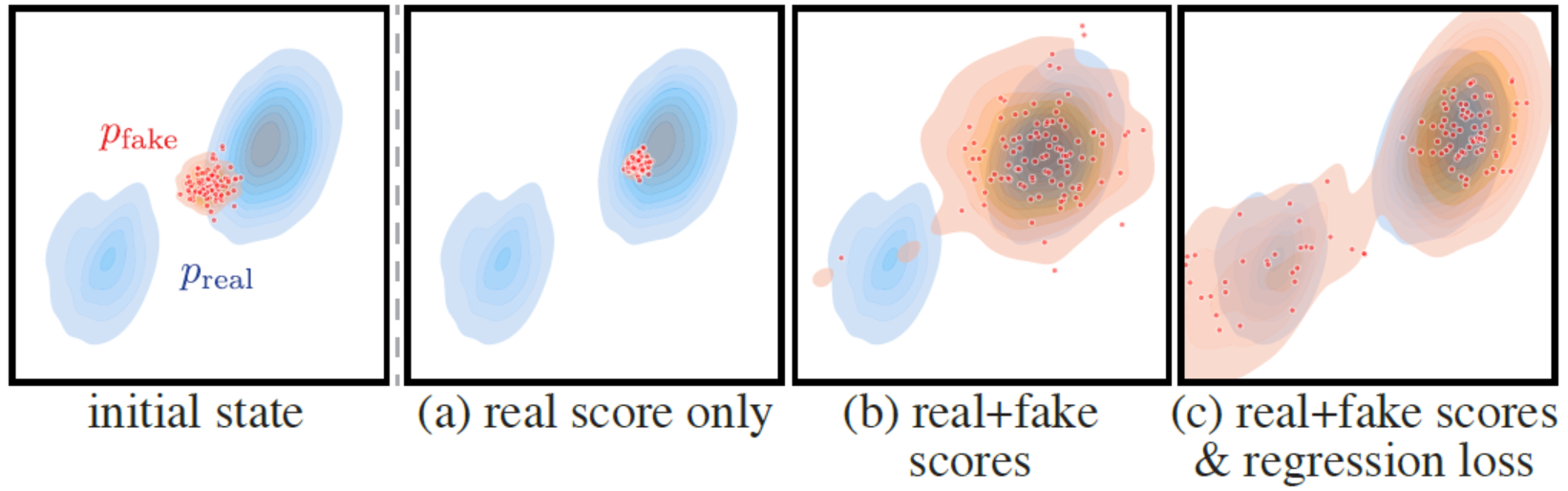
该图展示了从相同的初始配置(左图)优化不同目标函数所导致的不同结果:
(a) 只有真实得分: 当只优化真实得分时,生成的假样本都聚集在真实分布的最近模式上,出现了模式坍塌现象,即只能捕捉到数据的一部分特征。
(b) 真实得分+假得分: 当考虑了真实和假分布的得分,但没有回归损失时,生成的假数据覆盖了更多的真实分布,但仍然完全错过了第二个模式,即没有捕捉到分布的全部特征。
© 真实得分+假得分+回归损失: 当全面考虑真实得分、假得分以及回归损失时,完整的目标函数能够恢复目标分布的所有模式,生成的数据不仅多样且质量高。
这三个子图说明了不同优化策略对生成模型性能的影响,强调了在生成过程中同时考虑多个目标的重要性,以确保生成的数据既真实又多样。这一点在使用生成模型进行数据增强或者模拟真实世界分布时尤为重要。
总结
本文介绍了一种名为分布匹配蒸馏(DMD)的新技术,旨在加速扩散模型的图像生成过程,同时保持高质量的输出。DMD通过将扩散模型转化为一步生成模型,极大地提高了生成速度,达到了实时生成的目标。通过最小化真实与生成分布间的KL散度和引入回归损失,DMD能够在加速生成的同时,保证图像的多样性和质量。实验结果表明,DMD在多个标准数据集上达到了与原始扩散模型相媲美的性能,同时生成速度得到了显著提升。这一进展不仅为图像生成领域带来了新的技术突破,也为其他基于模型蒸馏的应用提供了可能的方向。尽管存在一些局限性,比如与更细致的扩散采样路径相比,质量上仍有差距,DMD的提出无疑为高效、高质量的图像生成研究开辟了新的路径。作者期待未来能通过蒸馏更先进的模型和引入变化的指导尺度来进一步提升模型性能和灵活性。
图1 答案: (DMD:bottom, top, bottom, bottom, top)
更多细节请参阅论文原文
关注微信公众号: DeepGo

















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









