







 本文详细介绍了Attention机制,包括其得分函数,还阐述了多种基于Attention的模型,如RAM、Encoder - Decoder等。在NLP和CV领域,Attention机制能有效解决信息丢失和并行计算问题,像Transformer就利用Self - Attention提升性能,SE模块则在CV中增强特征提取。
本文详细介绍了Attention机制,包括其得分函数,还阐述了多种基于Attention的模型,如RAM、Encoder - Decoder等。在NLP和CV领域,Attention机制能有效解决信息丢失和并行计算问题,像Transformer就利用Self - Attention提升性能,SE模块则在CV中增强特征提取。
几年前写的笔记了,部分内容对于现在来说肯定比较基础
Attention
Attention机制
Attention Score Function
q q q为Query Vector
-
加性模型
s ( x , q ) = v ⊤ tanh ( W x + U q ) s(\boldsymbol{x}, \boldsymbol{q})=\boldsymbol{v}^{\top} \tanh (\boldsymbol{W} \boldsymbol{x}+\boldsymbol{U} \boldsymbol{q}) s(x,q)=v⊤tanh(Wx+Uq)
-
点积模型
s ( x , q ) = x ⊤ q s(\boldsymbol{x}, \boldsymbol{q})=\boldsymbol{x}^{\top} \boldsymbol{q} s(x,q)=x⊤q
-
缩放点积模型
s ( x , q ) = x ⊤ q D s(\boldsymbol{x}, \boldsymbol{q})=\frac{\boldsymbol{x}^{\top} \boldsymbol{q}}{\sqrt{D}} s(x,q)=Dx⊤q
-
双线性模型
s ( x , q ) = x ⊤ W q s(\boldsymbol{x}, \boldsymbol{q})=\boldsymbol{x}^{\top} \boldsymbol{W} \boldsymbol{q} s(x,q)=x⊤Wq
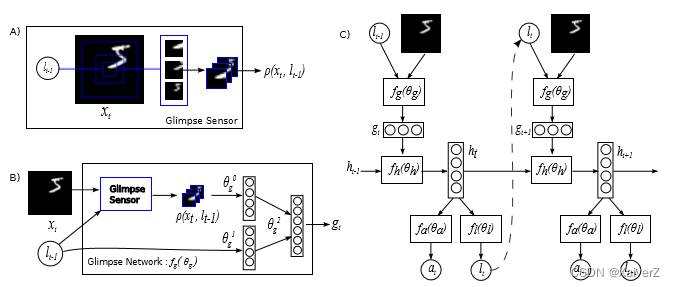
RAM(Recurrent Attention Model)
Paper : Recurrent Models of Visual Attention
Attention最早提出在CV领域
-
Glimpse Sensor:根据输入图像 x t x_t xt和上一时刻 h t − 1 h_{t-1} ht−1产生的位置坐标 l t − 1 l_{t-1} lt−1生成注意力区域 ρ ( x t , l t − 1 ) ρ(x_t, l_{t-1}) ρ(xt,lt−1)。实际上,Sensor会对位置坐标周围的图像采用高分辨率编码,离位置坐标中心越远,分辨率逐渐变低
-
Glimpse Network:根据产生的注意力区域 ρ ( x t , l t − 1 ) ρ(x_t, l_{t-1}) ρ(xt,lt−1)和位置坐标 l t − 1 l_{t-1} lt−1分别经过两个独立的全连接层 θ g 0 θ_g^0 θg0和 θ g 1 θ_g^1 θg1产生两个张量,再将这两个张量经过第三个全连接层 θ g 2 θ_g^2 θg2输出最终的表示 g t g_t gt
-
RNN Architecture:利用前述生成的 g t g_t gt张量作为RNN的输入,与前一时刻的 h t − 1 h_{t-1} ht−1相加生成当前时刻的 h t h_t ht,接着使用当前时刻的 h t h_t ht产生动作 a t a_t at, a t a_t at决定了下一个时刻输入的 g t g_t gt所用到的位置坐标 l t l_t lt
-
Internal state:agent当前所处的环境的状态编码,以 h t h_t ht表示
-
Actions: h t h_t ht产生的action,表示如何选取位置坐标 l t + 1 l_{t+1} lt+1
-
Reward:RNN的长度是预设好的超参数,在经过T个时间步后,分类结果若正确则reward为1,否则为0
-
上述过程在强化学习领域称为Partially Observable Markov Decision Process(POMDP)
-
Loss Function:RL看完再来补
Encoder-Decoder(Seq2Seq)
Paper : NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
NLP中的Attention机制(NLP最早的Attention机制)
-
早期的Seq2Seq模型先由Encoder编码出一个记忆向量 c c c,然后根据这个记忆向量去Decoder另一个序列。这种方式有一个问题,语义向量 c c c很难包含所有的语义信息,在decoder过程中,会随着序列的加长,效果越来越差
-
Encoder-Decoder Attention:在Decoder语义信息时,不再使用单一不变的语义向量 c c c。Decoder中每一个RNN Cell的输入都是Encoder中所有 h i h_i hi的加权平均。具体做法为:将 H i − 1 H_{i-1} Hi−1(也有些论文用 H i H_i Hi)分别与 h i h_i hi作一定的函数F操作(比如点积),将输出值经过Softmax进行权重归一化,然后利用得到的权重与对应的 h i h_i hi相乘并求和,将结果作为下一时刻的输入。
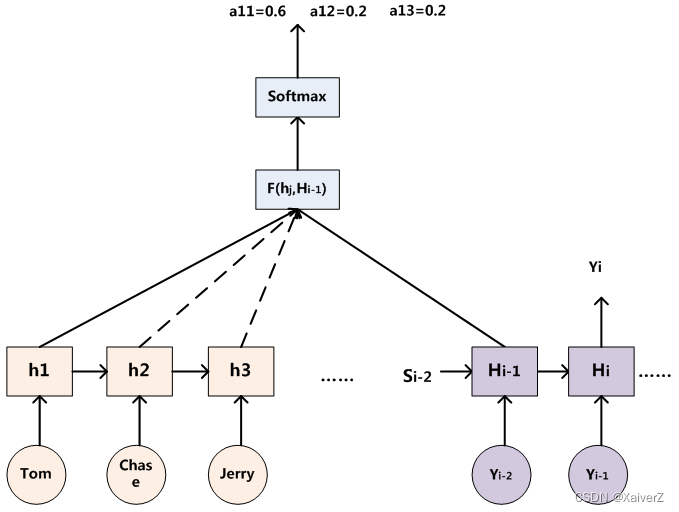
- 目前计算 H i − 1 H_{i-1} Hi−1与 h i h_i hi之间的Attention Score的函数F有以下几种:
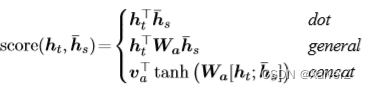
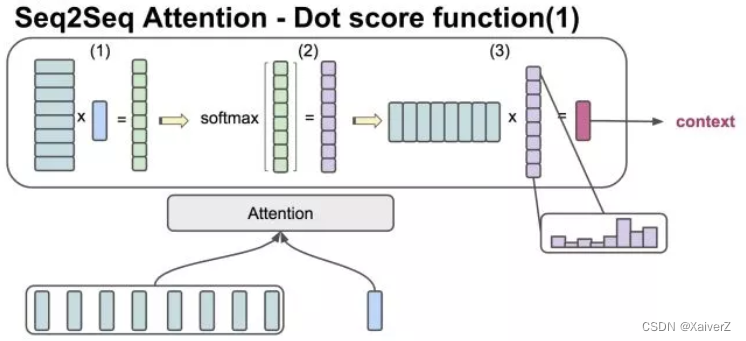
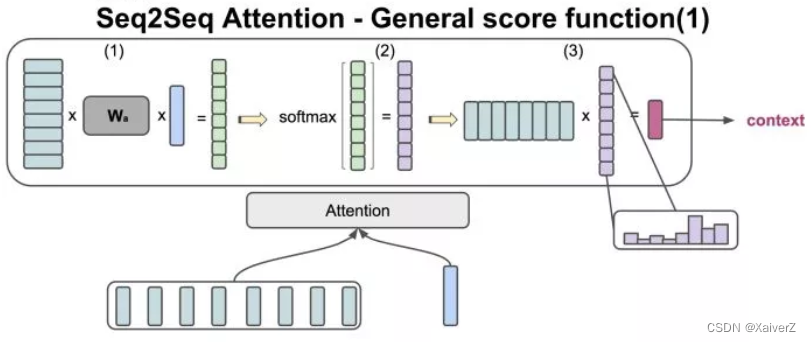
- Attention实际上计算了Decoder的 H i − 1 H_{i-1} Hi−1与每个 h i h_i hi的相似度(相关度),相关度越高的值肯定越大,所获得的权重也就越大,然后把这个权重与 h i h_i hi对应相乘,这样就可以在每次Decoder时,将注意力集中在某个相关度高的 h i h_i hi上,这就是Attention的精髓所在
Soft Attention & Hard Attention
Paper : Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
-
Soft Attention:考虑Encoder所有的 h i h_i hi,每个 h i h_i hi都与 H i − 1 H_{i-1} Hi−1计算概率
-
Hard Attention:只考虑Encoder中的一个对应的 h i h_i hi,只用特定的 h i h_i hi与 H i − 1 H_{i-1} Hi−1计算概率
Global Attention & Local Attention
Paper : Effective Approaches to Attention-based Neural Machine Translation
-
Global Attention:考虑Encoder所有的 h i h_i hi,每个 h i h_i hi都与 H i − 1 H_{i-1} Hi−1计算概率。等价于Soft Attention
-
Local Attention:考虑Encoder一个窗口期的 h i h_i hi。使用一个人为设定的参数D选择一个以 p t p_t pt为中心,[ p t − D p_t - D pt−D, p t + D p_t + D pt+D]为窗口的区域。是一种介于Soft Attention和Hard Attention之间的方式。
-
p
t
p_t
pt的选取在论文中有以下两种方式:
- Monotonic alignment (local-m):直接令 p t = t p_t = t pt=t
- Predictive alignment (local-p):公式为:
p t = S ⋅ s i g m o i d ( v p T t a n h ( W p h t ) ) p_t = S · sigmoid(v_p^Ttanh(W_ph_t)) pt=S⋅sigmoid(vpTtanh(Wpht))
其中, W p W_p Wp和 v p v_p vp为可训练参数, S S S为原输入序列的长度, h t h_t ht为当前Decoder的hidden state。实际上,这种方法在最后计算出的权重分配矩阵(Alignment Weights Matrix) a t a_t at上又添加了一项均值为 p t p_t pt,标准差为 D / 2 D/2 D/2的标准正态分布乘积项:
a t ( s ) = a l i g n ( h t , h ‾ s ) e x p ( − ( s − p t ) 2 2 σ 2 ) a_t(s) = align(h_t, \overline{h}_s)exp(-\frac{(s - pt)^2}{2σ^2}) at(s)=align(ht,hs)exp(−2σ2(s−pt)2)
a l i g n ( h t , h ‾ s ) = e x p ( s c o r e ( h t , h ‾ s ) ) ∑ s ′ e x p ( s c o r e ( h t , h ‾ s ′ ) ) align(h_t, \overline{h}_s) = \frac{exp(score(h_t, \overline{h}_s))}{\sum\limits_{s'}{exp(score(h_t, \overline{h}_{s'}))}} align(ht,hs)=s′∑exp(score(ht,hs′))exp(score(ht,hs))
其中,score为Attention Score函数, h t h_t ht为Decoder当前时刻状态, h ‾ s \overline{h}_s hs为Encoder某Cell状态。在添加高斯分布项后,alignment权重随着 h ‾ i \overline{h}_i hi在窗口中远离中心 p t p_t pt而逐渐降低,等于说给 p t p_t pt这个中心点一个更大的影响力
-
p
t
p_t
pt的选取在论文中有以下两种方式:
Key-Value Pair Attention
键值对注意力模式
-
“Key”用来与Query Vector计算Attention Score,“Value”用于计算Attention加权结果
att ( ( K , V ) , q ) = ∑ n = 1 N α n v n = ∑ n = 1 N exp ( s ( k n , q ) ) ∑ j exp ( s ( k j , q ) ) v n \begin{aligned} \operatorname{att}((\boldsymbol{K}, \boldsymbol{V}), \boldsymbol{q}) &=\sum_{n=1}^{N} \alpha_{n} \boldsymbol{v}_{n} \\ &=\sum_{n=1}^{N} \frac{\exp \left(s\left(\boldsymbol{k}_{n}, \boldsymbol{q}\right)\right)}{\sum_{j} \exp \left(s\left(\boldsymbol{k}_{j}, \boldsymbol{q}\right)\right)} \boldsymbol{v}_{n} \end{aligned} att((K,V),q)=n=1∑Nαnvn=n=1∑N∑jexp(s(kj,q))exp(s(kn,q))vn
Hierarchical Attention & Structured Attention
Paper : Hierarchical Attention Networks for Document Classification
Paper : STRUCTURED ATTENTION NETWORKS
层次、结构化注意力机制
Pointer Network
指针网络
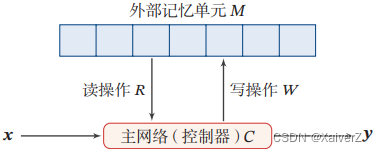
Memory Augmented Neural Network(MANN)
记忆增强神经网络
End-To-End Memory Network(MemN2N)
Paper : End-To-End Memory Networks
端到端记忆网络
Neural Turing Machine(NTM)
神经图灵机
Hopfield Network
Hopfield网络
Self-Attention(Transformer)
Paper : Attention Is All You Need
- 提出原因:RNN的计算顺序是有限制的,只能从左向右或从右向左依次计算。这种机制会带来两个问题:
-
时间点 t t t的计算依赖于 t − 1 t-1 t−1时刻的计算结果,限制了模型的并行能力
-
顺序计算的过程中信息会丢失。尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依然无能为力
-
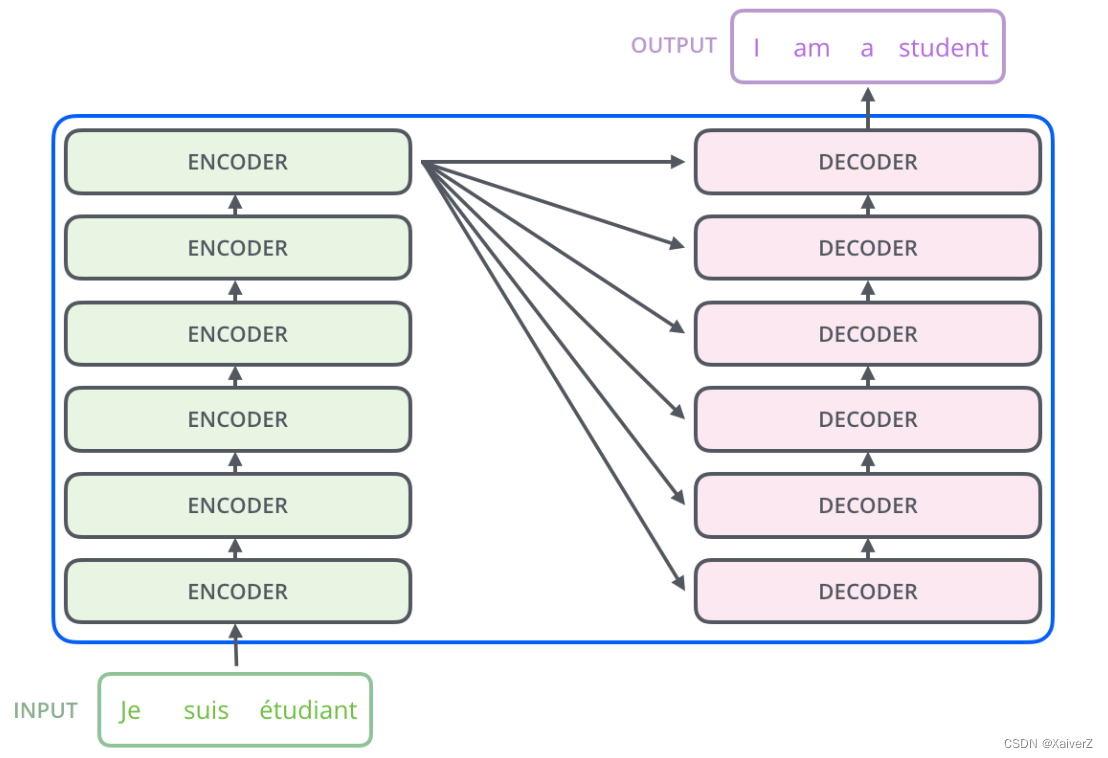
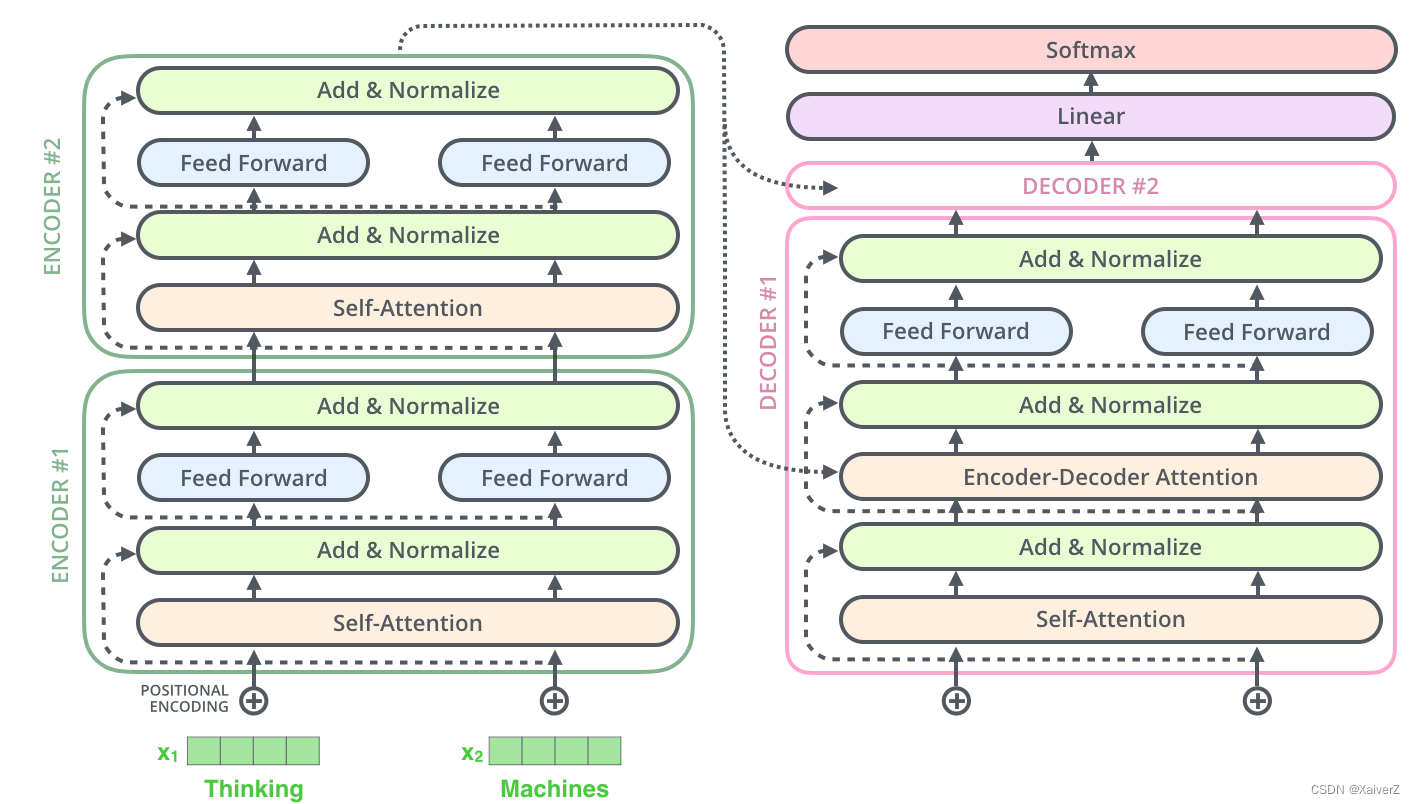
Transformer
Transformer完全不依赖于RNN结构,本质上是一种Encoder-Decoder结构。在论文中,Transformer由6个Encoder Block和6个Decoder Block组成:

Encoder
下图为Encoder整体结构
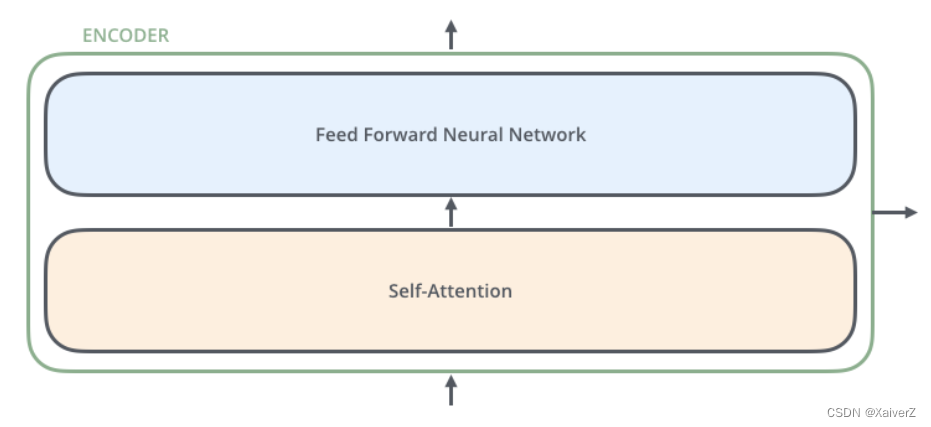
- 在Transformer的每个Encoder中,数据会首先经过Self-Attention模块得到一个加权之后的特征向量
Z
Z
Z,在原论文中定义如下:
Z = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Z = Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Z=Attention(Q,K,V)=softmax(dkQKT)V
得到 Z Z Z之后(实际上每个词都会生成一个 Z Z Z),它会被送到Encoder的下一个模块,即Feed Forward Neural Network(FFN)。FFN模块有两层,第一层是ReLU激活函数,第二层是一个线性激活函数。FFN在原论文中表示为:
F F N ( Z ) = m a x ( 0 , Z W 1 + b 1 ) W 2 + b 2 FFN(Z) = max(0,ZW_1 + b_1)W_2 + b_2 FFN(Z)=max(0,ZW1+b1)W2+b2
在Encoder中,我们将单词的Embedding Vector作为输入向量,经过Self-Attention后输出的向量通过FNN后继续喂给下一个Encoder,如下所示:

Decoder
Decoder
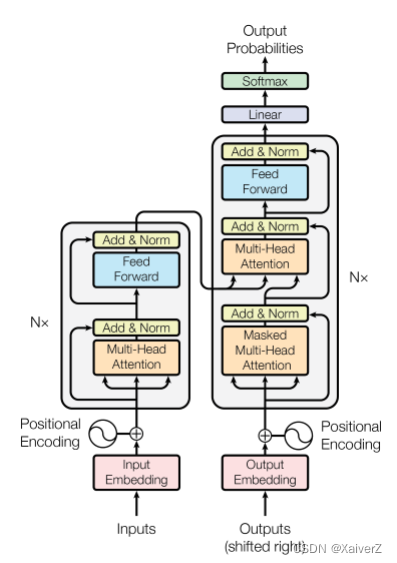
-
Masked Multi-Head Attention(Self-Attention):输入为当前已解码出的词的Embedding,但实际上输入必须是所有预测词的Matrix,这样大小才固定,所以这里需要用Masked矩阵去和输入做一个掩码操作,将未来待预测的词掩码成0,其余操作与Self-Attention一致。最后输出的值线性映射到某个维度,作为Query。
-
Multi-Head Attention(Encoder-Decoder Attention):该层接受从Encoder输出线性变换的Key,Value矩阵以及从Masked层输出的Query矩阵。其余操作与Multi-Head Attention一致。最后的输出也是过全连接层线性映射到某个维度,作为输出。
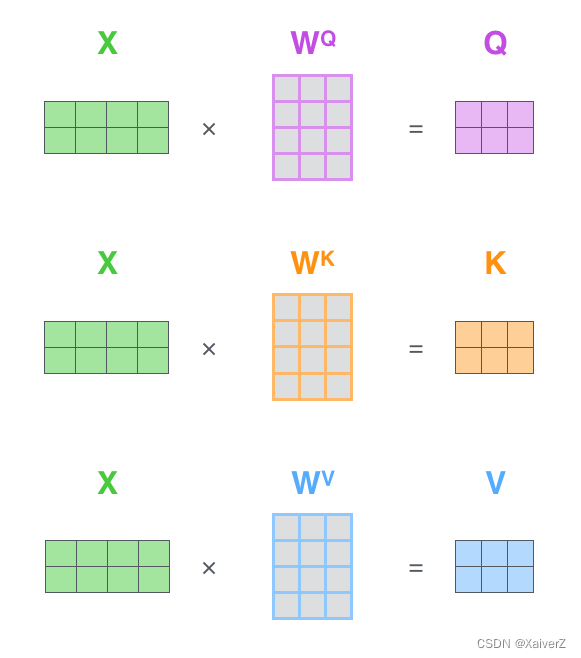
Self-Attention
自注意力机制
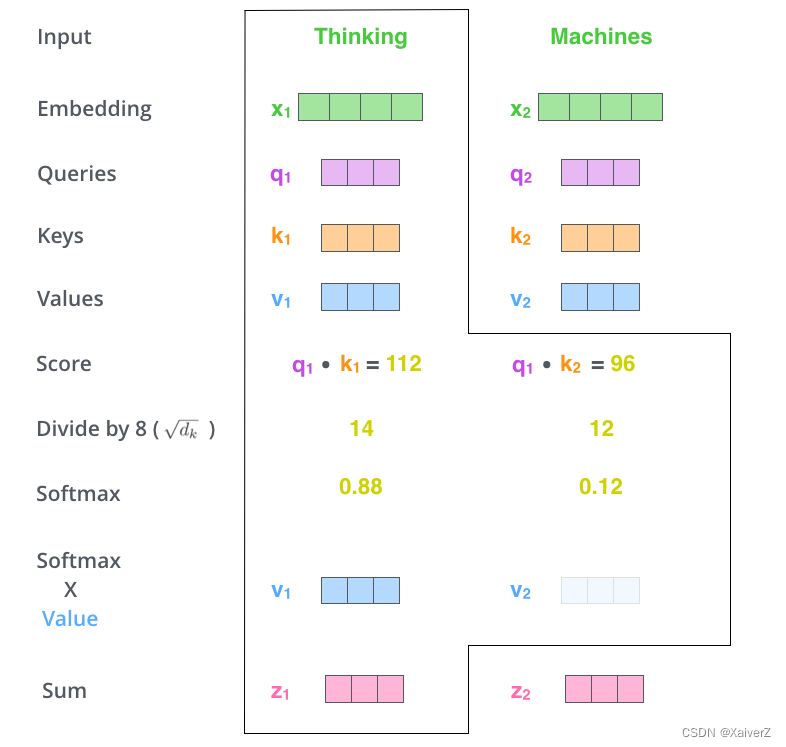
- 在Self-Attention中,每个单词有3个不同的向量:Query(Q),Key(K)和Value(V)。它们是由3个不同的权重矩阵 W Q W^Q WQ, W K W^K WK, W V W^V WV分别乘以单词的Embedding Matrix得到的:
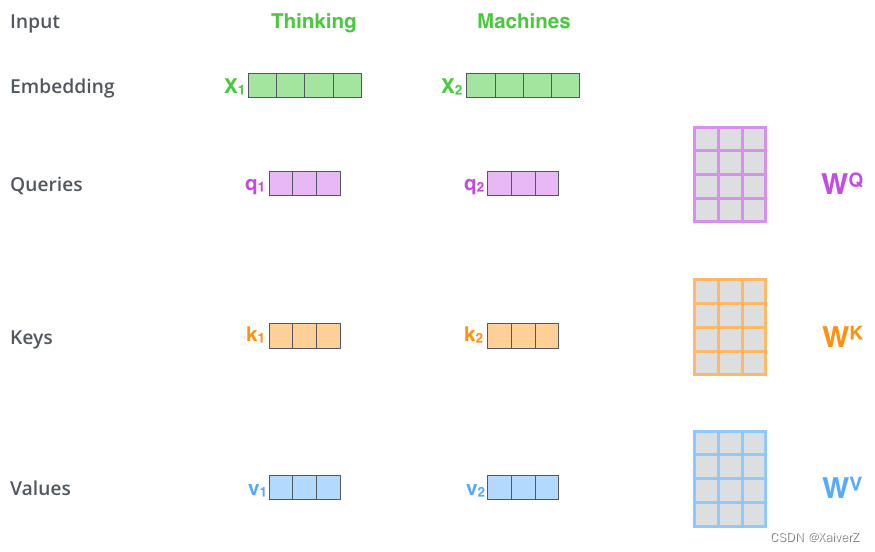
- Self-Attention核心操作:
- 将输入单词转化为词向量
- 根据词向量得到Q,K,V三个向量
- 为每个输入词向量计算一个Attention Score:
A t t e n t i o n S c o r e = Q ⋅ K Attention Score = Q · K AttentionScore=Q⋅K - 为了保持梯度的稳定,Transformer使用了Attention Score归一化,将其除以 d k \sqrt{d_k} dk防止值过大( d k d_k dk表示 K K K的维度)
- 对各个Attention Score进行Softmax权重归一化
- 将得到的权重点乘各个输入向量Value值得到该向量的加权输出
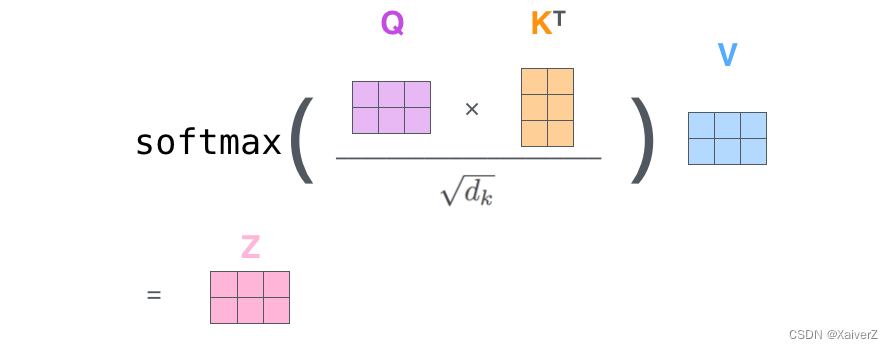
Multi-Head Attention
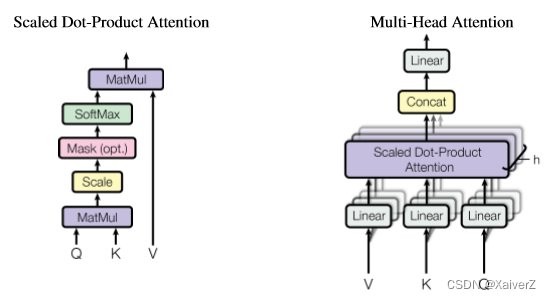
多头注意力,实际上自注意力的并行,绝非Stacking
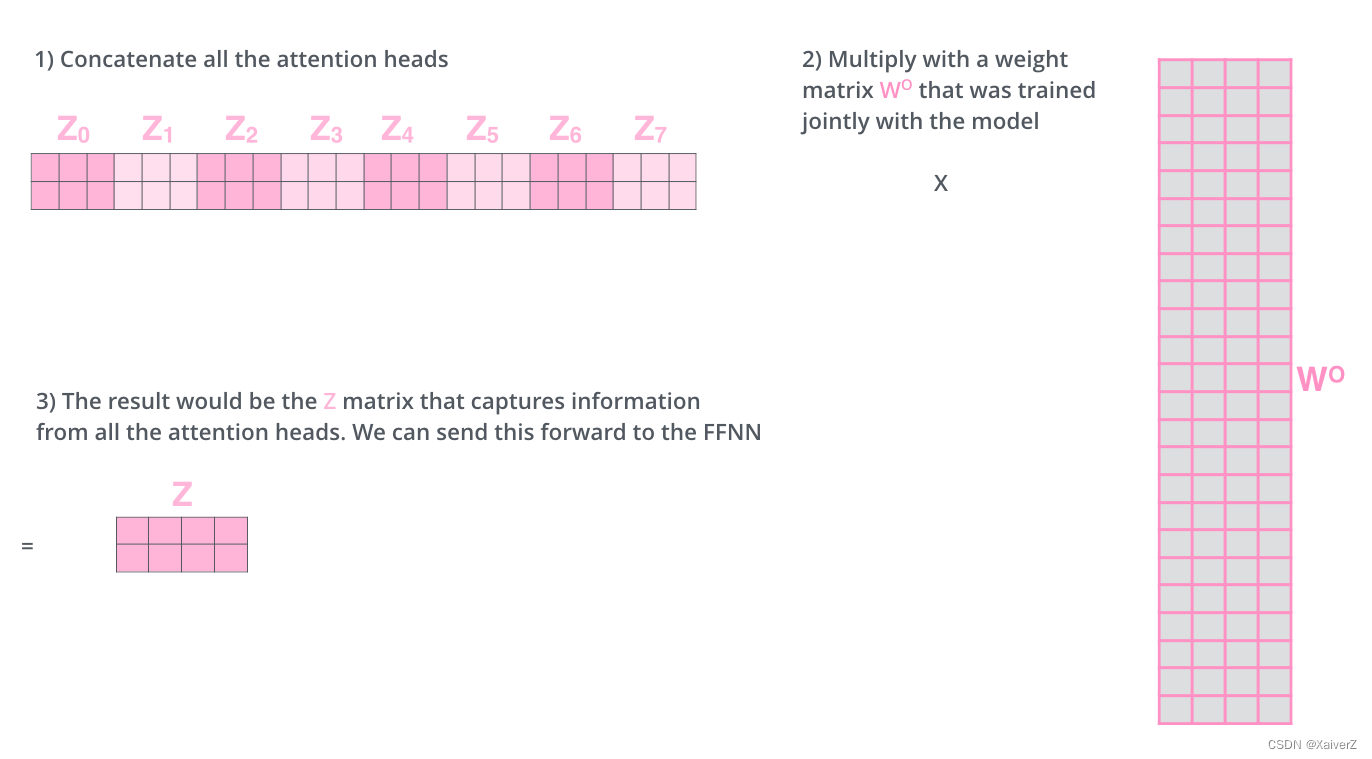
- 根据原论文的意思,先由输入的Embedding Matrix点积权重矩阵产生一组Q,K,V矩阵。然后将这组矩阵分别经过h个(假设h个并行多头注意力)全连接层,产生h组不同的Q,K,V。这h组各自作Self-Attention的操作,分别输出各自的加权输出向量。最后对这些向量作Concat,并点积一个权重矩阵将输出降维到单个输出的维度。如下为原文图解:
- 公式为:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W 0 MultiHead(Q,K,V) = Concat(head_1,...,head_h)W^0 MultiHead(Q,K,V)=Concat(head1,...,headh)W0
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i = Attention(QW_i^Q,KW_i^K,VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
Concat操作如下图所示:
Positional Encoding
位置编码
-
由于Transformer抛弃了RNN,改而使用了Self-Attention这种完全由Attention机制对序列数据进行特征提取的形式,所以Transformer本身并不能学习到语句中各个词的前后顺序(依赖)关系。为此,为使Transformer在输入数据的编码过程中能够捕捉到句子单词的位置信息,额外加入了对单词位置进行编码的方式,即Positional Embedding。
-
为了使Transformer能够捕捉到句子单词的位置信息,引入了Positional Encoding位置编码,在进行Self-Attention之前,会与Input Embedding进行相加。如下图所示:
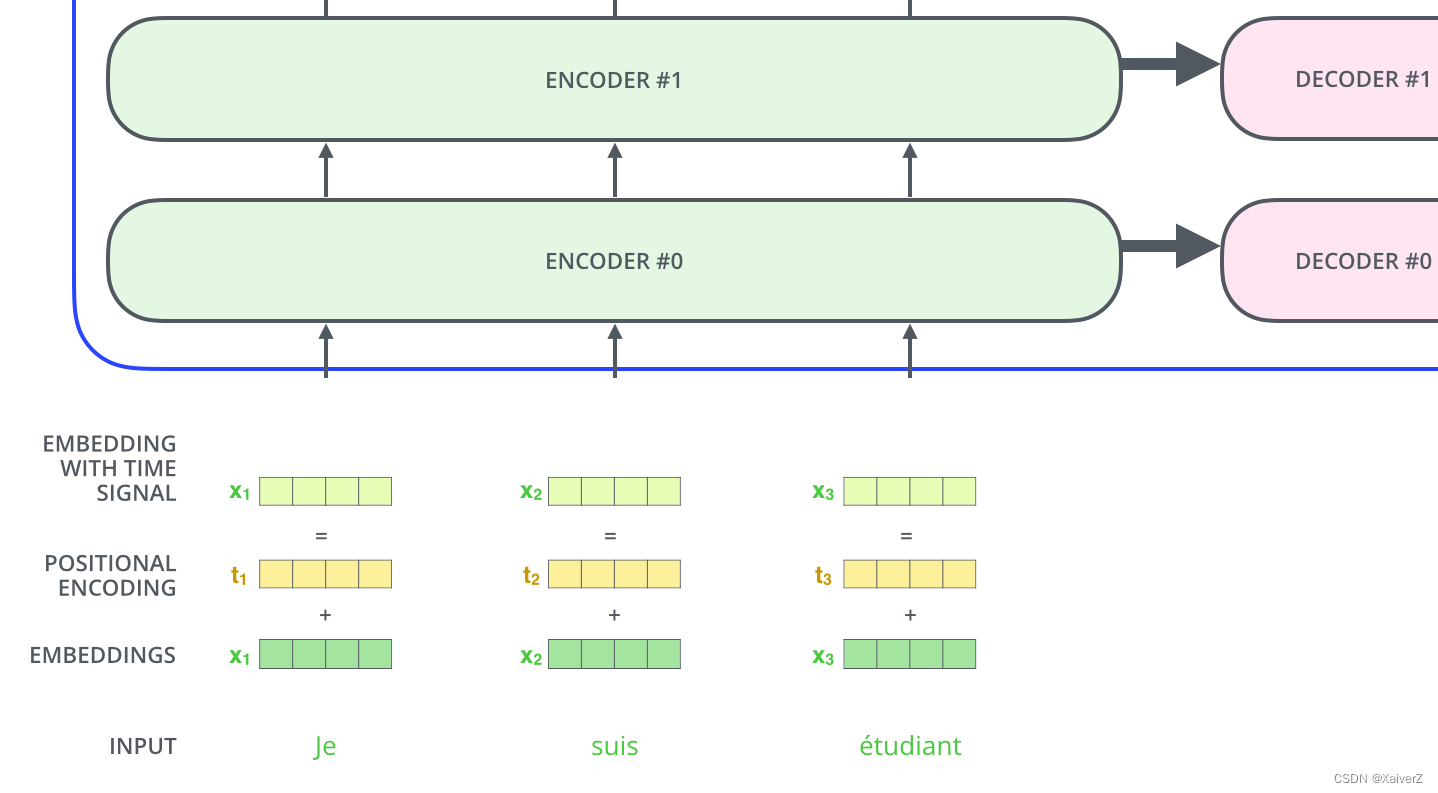
-
原论文中给出的编码公式如下:
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i d m o d e l ) PE(pos,2i) = sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d m o d e l ) PE(pos,2i + 1) = cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) PE(pos,2i+1)=cos(10000dmodel2ipos)
其中, p o s pos pos表示单词在原句子中的位置, i i i表示在pos位置上单词的Embedding Vector中的元素位置。 -
为什么使用这种公式?
-
由前述介绍的Word Embedding可知,单句话经过编码后得到的向量维度为[max_sequence, embedding_size],其中max_sequence为一个句子所能包含的最大单词数,embedding_size为每个单词的编码维度,二者均为超参数。为了能让向量进行加和运算,Positional Embedding的向量维度与Word Embedding保持一致。
-
那么为什么Positional Embedding能够捕捉到单词的位置信息呢?假设表示Embedding Vector中元素位置的参数i固定,则每个单词各自的Embedding Vector在i处的元素值只取决于pos参数,即单词在原句中的位置索引,则此时若将pos当作自变量,则上述编码公式的周期为:
T = 2 π ∗ 1000 0 2 i d model ∈ [ 2 π , 2 π ∗ 10000 ] T=2 \pi * 10000^{\frac{2 i}{d_{\text {model }}}} \in[2 \pi, 2 \pi * 10000] T=2π∗10000dmodel 2i∈[2π,2π∗10000]
- 可以看出,随着i值的增大,周期从2π逐渐增大到2π*10000,所以对于每一个pos上的Embedding Vector来说,都包含了不同周期的sin、cos函数的元素值组合,从而产生了独一无二的周期变化信息,而模型最终能学习到这些位置信息
-
-
例子:可以将Embedding Matrix看作是[5000, 512]的矩阵,5000为词数,512为Embedding Size。也就是说,行为 p o s pos pos,列为 i i i。例如当前需要计算第一个单词的位置编码,那么 p o s = 0 pos=0 pos=0,改变 i ∈ [ 0 , 511 / 2 ] i ∈[0, 511 / 2] i∈[0,511/2]就能计算出位置编码。
Residuals
Transformer用到了残差结构
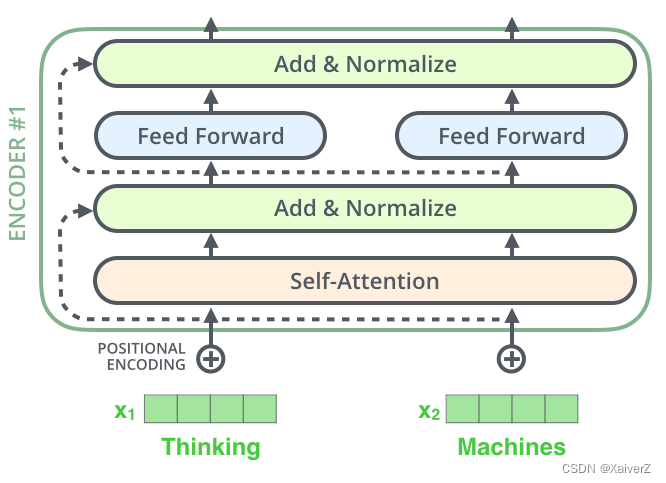
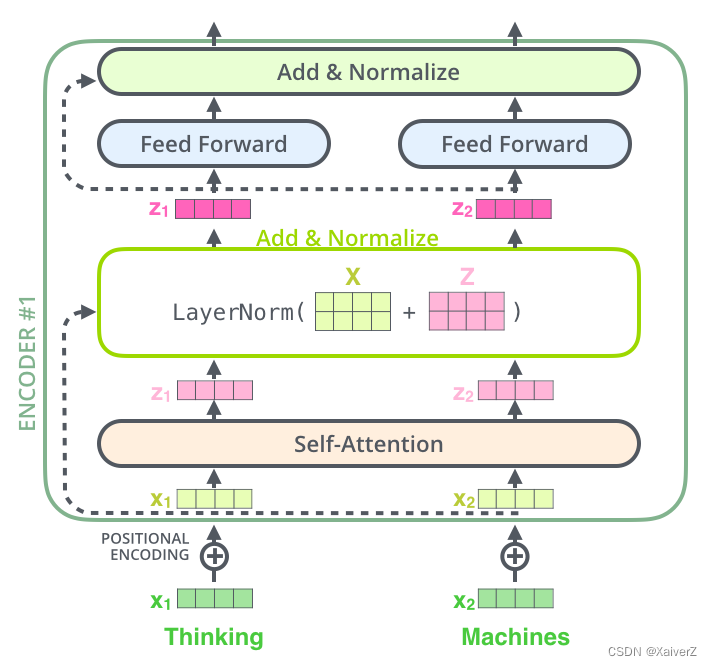
Squeeze-and-Excitation(SE)
Paper : Squeeze-and-Excitation Networks
CV中的Attention模块
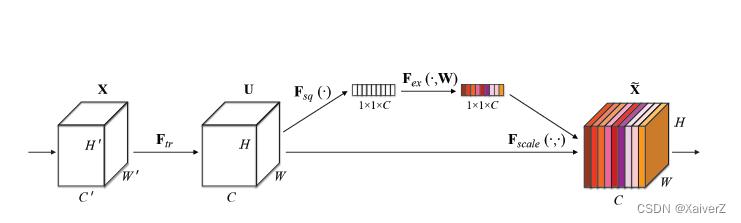
上图为SE的Block单元。 F t r F_{tr} Ftr表示传统的卷积结构, X X X和 U U U是 F t r F_{tr} Ftr的输入( C ′ × H ′ × W ′ C'×H'×W' C′×H′×W′)和输出( C × H × W C×H×W C×H×W)
-
Squeeze:Squeeze过程先对U做一个GAP(Global Average Pooling),即图中的 F s q ( ⋅ ) F_{sq}(·) Fsq(⋅)。GAP直接将每个通道的所有值平均成一个值。
-
Excitation:Excitation过程将Sequeeze输出的 1 × 1 × C 1×1×C 1×1×C数据经过两层全连接(图中的 F e x ( ⋅ ) F_{ex}(·) Fex(⋅)),最后再用Sigmoid将每个scale值限制到[0, 1]范围。最后将这个值作为scale乘到 U U U的 C C C个通道上,作为下一级的输入。两个全连接层中,第一个全连接把 C C C个通道压缩成了 C / r C/r C/r个通道来降低计算量,接着通过Relu激活,再通过第二个全连接层将其恢复回 C C C个通道,最后再通过Sigmoid。
-
r是指压缩的比例。作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡
-
这里加全连接层的意义就在于GAP操作是不可训练的,没有训练参数。如果只有GAP,那么这种Attention只能在单个样本内部起作用,无法基于整个数据集得出一个整体的scale。
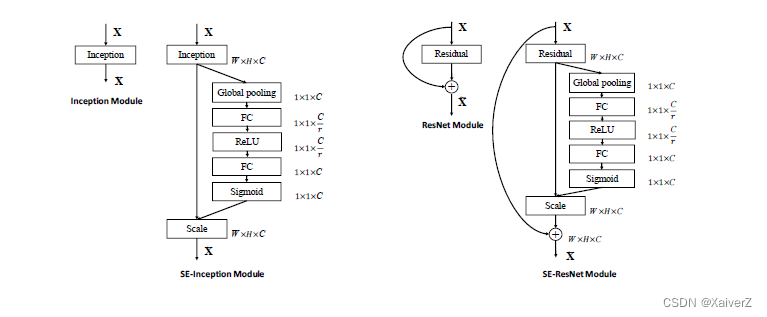
- 这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强

















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









