







Dilated Convolution
空洞卷积、扩张卷积。用于语义分割
-
提出原因:传统图像分类网络通常通过连续的Pooling或DownSampling来整合多尺度上下文信息,这种方式会损失分辨率。而对于稠密预测(Dense Prediction)任务而言,不仅需要多尺度的上下文信息,同时还要求输出具有足够大的分辨率。如果不加Pooling层的话会使感受野变小,学不到全局的特征。如果单纯去掉Pooling层而去纯粹扩大卷积核的话势必会增大计算量。此时最好的办法就是Dilated Convolution
-
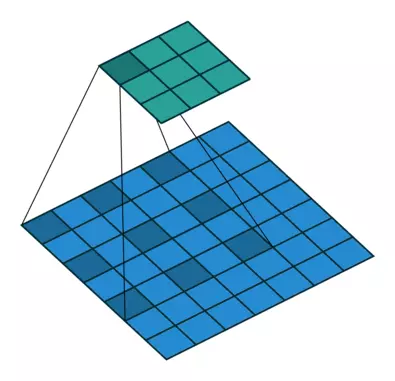
左图为标准卷积,右图为空洞率(Dilated Rate)为2的空洞卷积。(标准卷积空洞率默认为1)

-
空洞卷积支持感受野指数级的增长,同时还不损失分辨率
-
空洞卷积存在的问题:
1. The Gridding Effect:空洞卷积”空洞“部分的像素值并未参与计算,这会损失信息的连续性,这对Pixel-Level Dense prediction的任务来说是致命的
2. Long-ranged Information Might Be Not Relevant:只采用大空洞率的信息或许只对一些大物体分割有效果,而对小物体来说可能就有弊无利了
RoI Pooling
Region of Interest Pooling
- 前置操作:在Faster R-CNN中,在Shared Feature Map上通过RPN后,生成了 2 k 2k 2k个置信度与 4 k 4k 4k个坐标。这些坐标是相对于原图的,将这些坐标映射到公共特征图上即形成RoI区域。RoI Pooling就是对这些RoI区域进行操作。

- RoI Pooling:假设需要输出 2 ∗ 2 2*2 2∗2的特征图,那么就对RoI区域进行划分4大块,在每块内进行常规Pooling操作。


- 实际上RoI Pooling会对RoI区域平均划分 k × k k×k k×k个bins,一般来说这些bins的坐标都为浮点数,需要进行取整量化(向下取整),然后对这些bins进行max pooling操作。例如一个 7 × 7 7×7 7×7的RoI区域需要划分 2 × 2 2×2 2×2的bins,那么每个bin的长宽为 3.5 3.5 3.5,向下取整到 3 3 3,每个bin的尺寸就变为 3 × 3 3×3 3×3,只利用到了RoI区域的一部分,并不会像上图那样用到全部。
RoI Align
Region of Interest Align
-
提出原因:在实例分割任务中,RoI区域与原图是不对齐的(Mis-Alignment),这对于实例分割任务来说是致命的,毕竟实例分割需要精确分割出物体的边界。
-
RoI Pooling的局限性:由RPN产生的回归预测坐标是浮点数,而在RoI Pooling中,要求映射到特征图上的RoI区域尺寸是整数,故会存在两次取整量化过程:
- 原图坐标映射回特征图上时会将候选框边界量化为整数坐标值
- 将量化后的候选区域平均分割成 k × k k×k k×k个单元(bin),对每一个单元进行量化取整
-
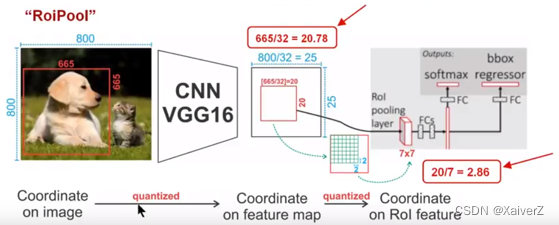
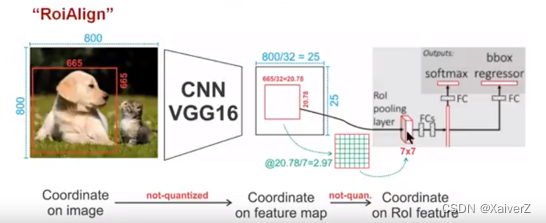
如上图所示,原图尺寸 800 × 800 800×800 800×800,候选区域在原图上尺寸 665 × 665 665×665 665×665,公共特征图与原图之间的步长为32。因此,将候选区域映射到特征图上时,需要进行缩放,即:
665 32 = 20.78 = 20 \frac{665}{32} = 20.78 = 20 32665=20.78=20
RoI Pooling直接将其量化为20,这一步的误差0.78还原到原图上就是 0.78 × 32 = 25 0.78 × 32 = 25 0.78×32=25,接近25个像素点的偏差。接下来对量化后的RoI区域平均分割成 7 × 7 7×7 7×7个bins,那么每个bin的尺寸大小为:
20 7 = 2.86 = 2 \frac{20}{7} = 2.86 = 2 720=2.86=2
RoI Pooling直接将其量化为2,这一步的误差还原到原图也接近30个像素点了。 -
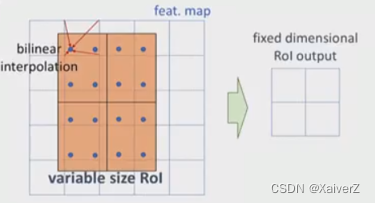
RoI Align的改进方案:RoI Align取消了RoI Pooling的所有量化操作,保持浮点数不变。在对RoI区域划分bins的过程中,由于bins的尺寸均为浮点数,故RoI Align对每个bin作如下处理:
- 选择bin的采样点的数量。若为1,则采样点就为该bin的中心坐标;若为4,则将bin内部平均划分 2 × 2 2×2 2×2的区域,每个采样点位于区域中心坐标处
- 根据采样点周围四个固定的整数坐标值,采用双线性插值(BiLinear Interpolation)计算每个采样点的值。然后在bin内对采样点值进行max pooling操作,计算出该bin最终的值
Region Proposal Networks(RPN)
区域生成网络
-
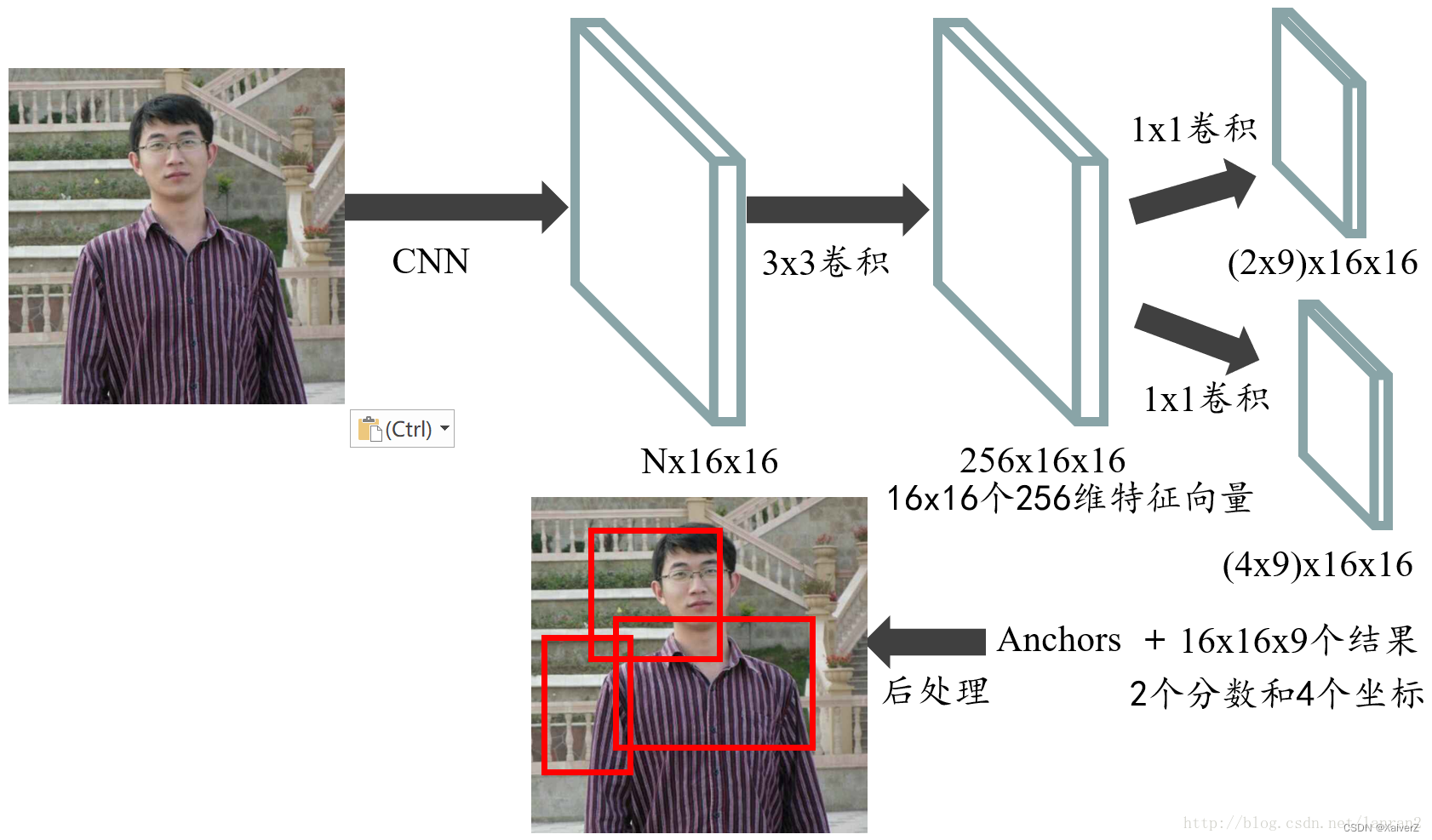
前置操作:在Faster R-CNN中,输入原始图像经过一系列卷积后得到公共特征图Shared Feature Map
-
RPN:在公共特征图上利用一个 n ∗ n n*n n∗n的滑动窗口对其进行特征提取,映射到一个更低维的特征空间。实际上,这里的滑动窗口是用 n ∗ n n*n n∗n的卷积来实现的。也就是说卷积完的特征图对于Shared Feature Map的感受野是 n ∗ n n*n n∗n,这样特征图上的每一点就可以映射到原图上一个感受野大小的区域。最后,再利用特征图分别经过两个 1 ∗ 1 1*1 1∗1的卷积输出特征图上每个点代表置信度与坐标的特征向量(这里输出的坐标是相对于原图的坐标),然后将坐标映射回公共特征图,生成RoI区域
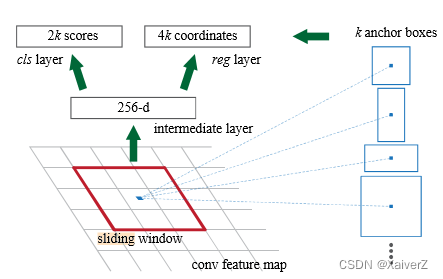
-
这里之所以是用 n ∗ n n*n n∗n的滑动窗口目的是为了进一步结合公共特征图上每一点周围像素的信息(注意公共特征图对于原图的感受野,这里的 n ∗ n n*n n∗n的卷积其实进一步扩大了感受野)
-
RPN只负责生成RoI区域的坐标以及区域内是否有物体的置信度,不负责输出分类结果。RPN只是第一阶段,第二阶段的RoI Pooling负责生成分类结果。
Deformable Convolutional Networks(DCN)
Paper : Deformable Convolutional Networks
Paper : Deformable ConvNets v2: More Deformable, Better Results
可变形卷积
- 解决的问题:传统的CNN只能靠一些简单的方法(如Max Pooling)来适应物体的形变。为了改善这种问题,大概有两种解决方式:
1. 使用大量数据训练。通过数据增强的方式,如翻转、旋转、裁剪等来穷举出各种仿射变换以使模型能够适应各种形状的物体。但这种方式显然收敛较慢且需要复杂的网络结构才能达到效果。
2. 设计特殊的算法来适应形变。比如SIFT、Sliding Windows。这种方式对那些形状极其复杂的物体很难设计出适应这种结构的算法。

-
数学定义:传统卷积结构可定义为下式:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n ) y(p_0) = \sum\limits_{p_n∈R}{w(p_n) · x(p_0 + p_n)} y(p0)=pn∈R∑w(pn)⋅x(p0+pn)
其中, p n p_n pn是卷积输出每一个点相对感受野上的每一个点的偏移量,取整数。
采用全新的可变形卷积后要在上述公式基础上给每个点增加一个偏移量 Δ p n Δp_n Δpn,这个新的偏移量是由另一个卷积得出的,一般为小数:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n + Δ p n ) y(p_0) = \sum\limits_{p_n∈R}{w(p_n) · x(p_0 + p_n + Δp_n)} y(p0)=pn∈R∑w(pn)⋅x(p0+pn+Δpn)
这里需要注意, x ( p 0 + p n + Δ p n ) x(p_0 + p_n + Δp_n) x(p0+pn+Δpn)该位置的坐标索引取值并非整数,并不对应特征图上实际存在的点,所以需使用双线性插值进行近似计算。 -
实现方式:如下图所示。可变形卷积有一个额外的Conv层来学习offset。例如当前可变形卷积的卷积核为 3 × 3 3×3 3×3,在计算输出特征图上的某一点时,对应输入特征图上一块 3 × 3 3×3 3×3的区域。若此时为传统卷积,则直接将权重矩阵与这块区域点积即可。而可变形卷积单独将这块 3 × 3 3×3 3×3区域取出来经过一次卷积核大小一样也为 3 × 3 3×3 3×3但卷积核数为 3 × 3 × 2 = 18 3×3×2 = 18 3×3×2=18的卷积,生成18个偏移量,分别对应着 3 × 3 3×3 3×3区域每个点的 X X X、 Y Y Y方向的偏移量。最后将该偏移域与原始数据输入进行计算得到最终值。(这里其实可以生成多组偏移矩阵,相应的卷积核数再乘以组数即可)
















 2166
2166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









