









主要工作
- 定义了一种表示整个序列概率分布方式。
- 然后用交叉熵的方式计算两个分布的距离。
- 比pairwise好的方式是,解决了pairwise因为query不同而导致的训练数据偏差。listwise的方式更接近map等排序指标的优化。
理论工作
定义排列得分
定义了序列的概率表示方式。

例如:

排序公式的特性:大体意思是将高分item交换到任何一个低分的位置,整个队列的概率得分P会下降。

优化排列得分计算方式
原因:因为计算两个概率分布之间的差异,需要计算所有排列组合的差异,计算量是N的阶乘,计算量较大。
解决方式:所以对于任何排序组合同TOP1的排序得分作为一批概率分布的总得分,将计算量降低到N。
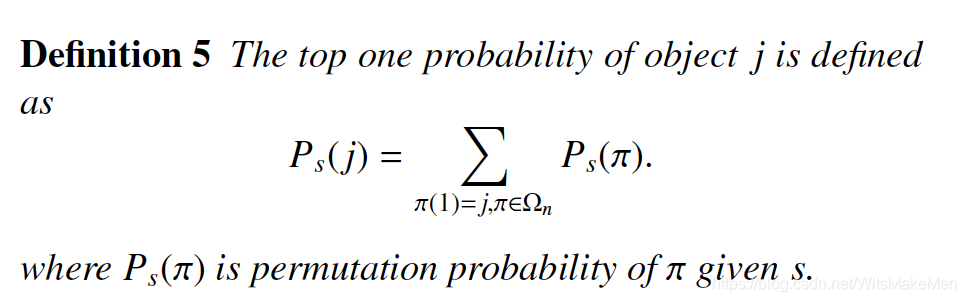
简化公式5后,后面n-1的子队列,加和是1,所以简化后公式6

计算两个分布之间的差异
使用交叉熵作为最后的损失函数

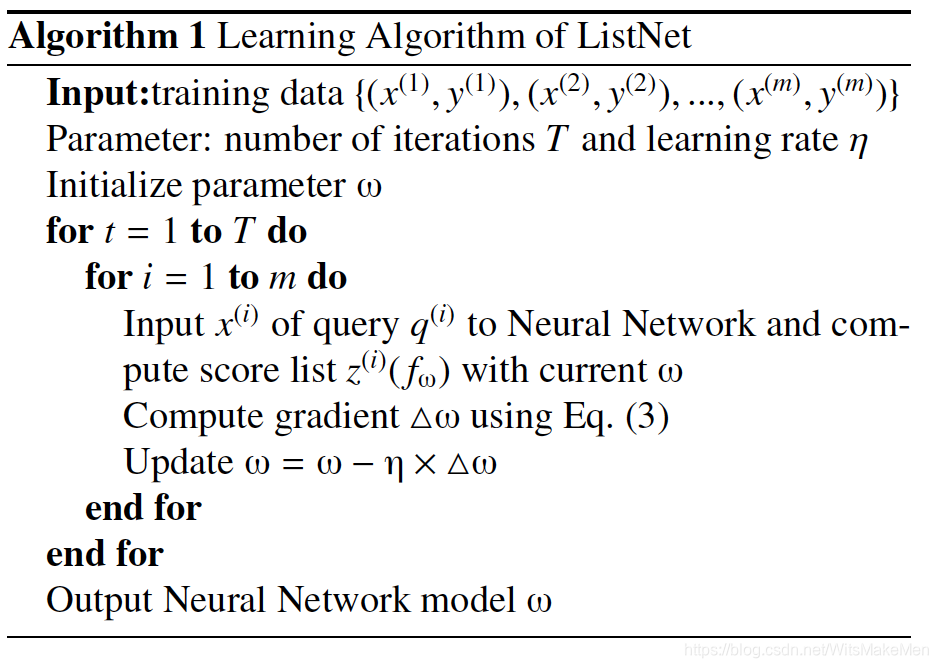
算法工作ListNet
为了方便求导,对公式6进行了修改,加上指数函数

算法,求导并且进行参数迭代

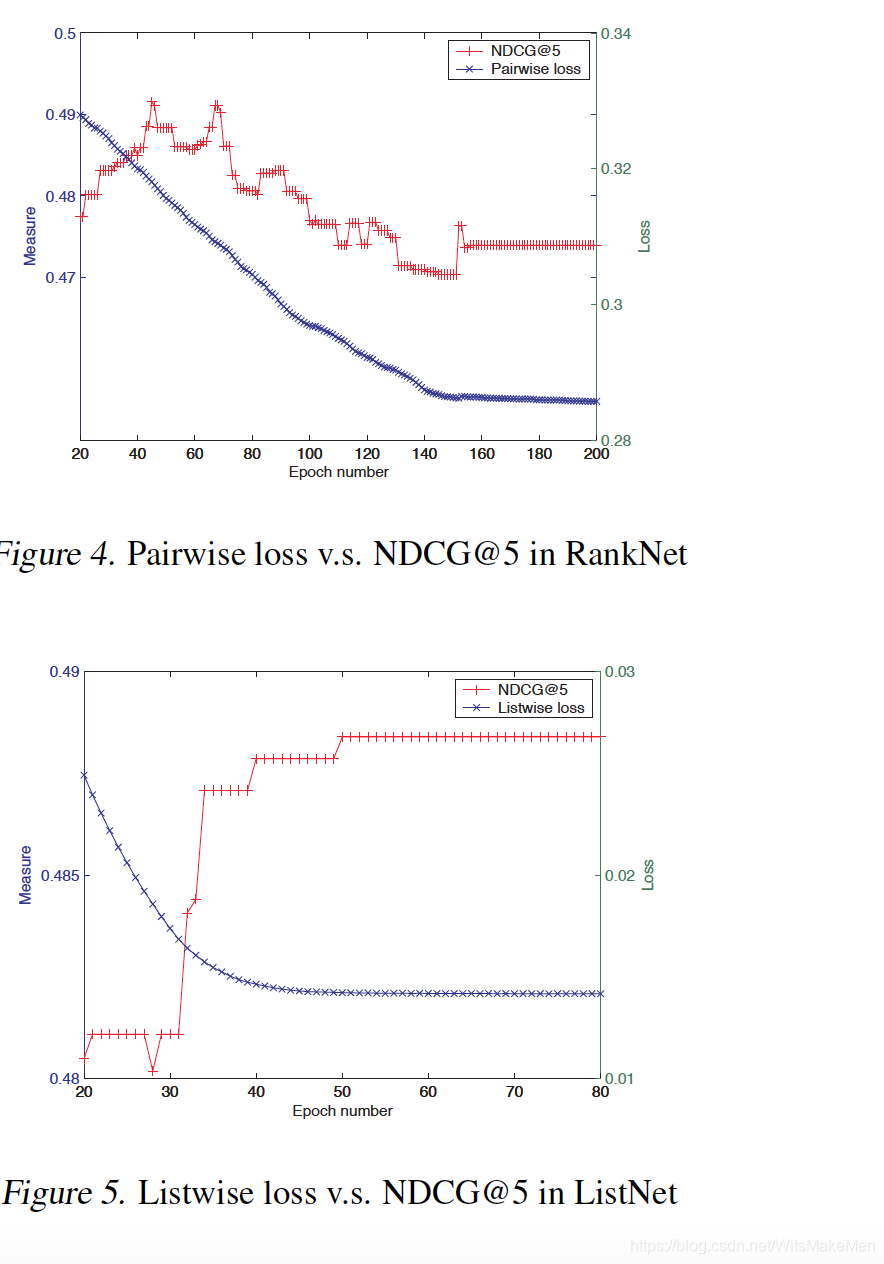
效果好的原因
- 解决了pairwise因为query不同,返回item个数不同,而导致的样本偏差的问题。
- listwise优化目标更接近map,ndcg等评估指标,例如随着训练轮数的增加,pairwise的ndcg5会下降,但是listwise不会。















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











