





解决的问题
关于排序已经有很多方法提出了,它们的共同点就是将object对当做学习的实例,我们把它们叫做pairwise的方法。Pairwise方法有诸多优点,但它们忽略了一个事实——排序是一个在object list上进行预测的任务。本文认为排序应该以一个list的object作为实例。
listwise方法
在本节我们以文档召回为例简短介绍一下learning to rank,再着重介绍listwise方法。下面我们用上标来代表query的index,下标表示doc的index。
在训练过程中,给出一个集合的query
Q
=
{
q
(
1
)
,
q
(
2
)
,
.
.
.
,
q
(
m
)
}
Q = \{ q^{(1)}, q^{(2)}, ..., q^{(m)}\}
Q={q(1),q(2),...,q(m)},每个query与一个list的doc
d
(
i
)
=
(
d
1
(
i
)
,
d
2
(
i
)
,
.
.
.
,
d
n
(
i
)
(
i
)
)
d^{(i)} = (d_1^{(i)}, d_2^{(i)}, ..., d_{n^{(i)}}^{(i)})
d(i)=(d1(i),d2(i),...,dn(i)(i))相关联。其中
d
j
(
i
)
d_j^{(i)}
dj(i)表示第j个doc,
n
(
i
)
n^{(i)}
n(i)表示
d
(
i
)
d^{(i)}
d(i)的长度。此外,每个doc list的doc
d
(
i
)
d^{(i)}
d(i)与一个list的score
y
(
i
)
=
(
y
1
(
i
)
,
y
2
(
i
)
,
.
.
.
,
y
n
(
i
)
(
i
)
)
y^{(i)} = (y_1^{(i)}, y_2^{(i)}, ..., y_{n^{(i)}}^{(i)})
y(i)=(y1(i),y2(i),...,yn(i)(i))相关联。分数表示doc和query间的相关性,可以是用户给出的显式或隐式的分数。
一个特征向量
x
j
(
i
)
=
Φ
(
q
(
i
)
,
d
j
(
i
)
)
x_j^{(i)} = \Phi(q^{(i)}, d_j^{(i)})
xj(i)=Φ(q(i),dj(i))会从每个query-doc对中抽取出来。每个list的特征
x
(
i
)
=
(
x
1
(
i
)
,
x
2
(
i
)
,
.
.
.
,
x
n
(
i
)
(
i
)
)
x^{(i)} = (x_1^{(i)}, x_2^{(i)}, ..., x_{n^{(i)}}^{(i)})
x(i)=(x1(i),x2(i),...,xn(i)(i))就有了相关联的分数
y
(
i
)
=
(
y
1
(
i
)
,
y
2
(
i
)
,
.
.
.
,
y
n
(
i
)
(
i
)
)
y^{(i)} = (y_1^{(i)}, y_2^{(i)}, ..., y_{n^{(i)}}^{(i)})
y(i)=(y1(i),y2(i),...,yn(i)(i))。于是训练集就可以表示为
T
=
{
(
x
(
i
)
,
y
(
i
)
)
}
i
=
1
m
T = \{(x^{(i)}, y^{(i)})\}_{i=1}^m
T={(x(i),y(i))}i=1m。
对于一个list的特征向量
x
(
i
)
x^{(i)}
x(i),我们的排序模型得到一个list的分数
z
(
i
)
=
(
f
(
x
1
(
i
)
)
,
f
(
x
2
(
i
)
)
,
.
.
.
,
f
(
x
n
(
i
)
(
i
)
)
)
z^{(i)} = (f(x_1^{(i)}), f(x_2^{(i)}), ..., f(x_{n^{(i)}}^{(i)}))
z(i)=(f(x1(i)),f(x2(i)),...,f(xn(i)(i))),训练的损失函数为
∑
i
=
1
m
L
(
y
(
i
)
,
z
(
i
)
)
\sum^m_{i=1}L(y^{(i)}, z^{(i)})
i=1∑mL(y(i),z(i)),其中
L
L
L是listwise损失。
在排序过程中,当给出一个新的query和与它关联的一个list的doc,我们就用训练好的排序模型来对它们进行排序。
概率模型
为计算listwise的loss,我们提出了一个概率模型——我们将一个list的score映射为一个概率分布,然后将两个概率分布间的metric作为loss。两个概率模型分别为permutation probability和top one probability。
Permutation Probability
假设将要被排序的ojbects用1,2, …, n来标示。一个permutation (排列)
π
\pi
π定义为{1, 2, …, n}到自身的双射,我们将其写作
π
=
<
π
(
1
)
,
π
(
2
)
,
.
.
.
,
π
(
n
)
>
\pi = <\pi(1), \pi(2), ..., \pi(n)>
π=<π(1),π(2),...,π(n)>,对于所有n个object的可能的排列表示为
Ω
n
\Omega_n
Ωn。
假设我们现在有一个排序函数,为每个object打了一个分数,我们用s来表示分数的list:
s
=
(
s
1
,
s
2
,
.
.
.
,
s
n
)
s = (s_1, s_2, ..., s_n)
s=(s1,s2,...,sn)。之后我们对排序函数和用排序函数打出的分数会不作区分。
下面我们就可以定义排列概率来表示一个排序函数的似然——
定义1:假设
π
\pi
π是在n个object上的一个排列,
ϕ
(
.
)
\phi(.)
ϕ(.)是一个单调递增的正函数,那么在给定
s
s
s的情况下,排列
π
\pi
π的概率为:
P
s
(
π
)
=
∏
j
=
1
n
Φ
(
s
π
(
j
)
)
∑
k
=
j
n
Φ
(
s
π
(
k
)
)
P_s(\pi) = \prod ^n _{j=1} \frac{\Phi(s_{\pi(j)})}{\sum^n_{k=j}\Phi(s_{\pi(k)})}
Ps(π)=j=1∏n∑k=jnΦ(sπ(k))Φ(sπ(j))
其中
s
π
(
j
)
s_{\pi(j)}
sπ(j)是被排在j位置的object的分数。
考虑一个例子,假设3个object {1, 2, 3} 的分数
s
=
(
s
1
,
s
2
,
s
3
)
s=(s_1, s_2, s_3)
s=(s1,s2,s3),两个排列
π
=
<
1
,
2
,
3
>
\pi = <1, 2, 3>
π=<1,2,3>和
π
=
<
3
,
2
,
1
>
\pi = <3, 2, 1>
π=<3,2,1>的概率分别是:
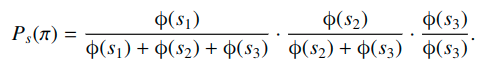
和
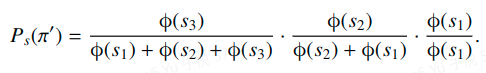
对于以上排列概率我们有一个引理。
引理2:排列概率对于排列的集合服从概率分布,即对于任意排列
π
∈
Ω
n
\pi \in \Omega_n
π∈Ωn,有
P
s
(
π
)
>
0
和
∑
π
∈
Ω
n
P
s
(
π
)
=
1
P_s(\pi)>0和\sum_{\pi \in \Omega_n}P_s(\pi) = 1
Ps(π)>0和∑π∈ΩnPs(π)=1
定理3: 给定两个排列
π
\pi
π和
π
′
\pi'
π′,若(1)
π
(
p
)
=
π
′
(
q
)
,
π
(
q
)
=
π
′
(
p
)
,
p
<
q
\pi(p) = \pi'(q), \pi(q) = \pi'(p), p < q
π(p)=π′(q),π(q)=π′(p),p<q; (2)
π
(
r
)
=
π
′
(
r
)
,
r
≠
p
,
q
\pi(r) = \pi'(r), r \neq p, q
π(r)=π′(r),r=p,q; (3)
s
π
(
p
)
>
s
π
(
q
)
s_{\pi(p)} > s_{\pi(q)}
sπ(p)>sπ(q),则
P
s
(
π
)
>
P
s
(
π
′
)
P_s(\pi) > P_s(\pi')
Ps(π)>Ps(π′)
定理4: 对于n个objects,若
s
1
>
s
2
>
.
.
.
>
s
n
s_1 > s_2 > ... > s_n
s1>s2>...>sn,则
P
s
(
<
1
,
2
,
.
.
.
,
n
>
)
P_s(<1, 2, ..., n>)
Ps(<1,2,...,n>)是排列概率最大的一个排列,
P
s
(
<
n
,
n
−
1
,
.
.
.
,
1
>
)
P_s(<n, n-1, ..., 1>)
Ps(<n,n−1,...,1>)是排列概率最小的一个排列。
定理3表示对于任意排好序的list,如果我们交换一个分数较高和一个分数较低的object的顺序,排列概率就会降低。定理4表示按照分数降序的排列有最高的排列概率,而按分数升序的排列概率最低。
给出两列分数,我们可以先计算出它们的排列概率,然后计算两个分布的距离来作为listwise的loss。由于n个object的排列数量是n!个,全部计算出来是不现实的,我们利用top one概率来解决这个问题。
top one probability
一个object的top one概率代表它被排在top 1的概率。
定义5:object j的top one probability定义为:
P
s
(
j
)
=
∑
π
(
1
)
=
j
,
π
∈
Ω
n
P
s
(
π
)
P_s(j) = \sum_{\pi(1)=j, \pi \in \Omega_n} P_s(\pi)
Ps(j)=π(1)=j,π∈Ωn∑Ps(π)
也就是说,object j的top one概率等于j被排在第一位的所有排列的排列概率之和。对于这一概率我们有更加简便的算法。
定理6:对于top one概率
P
s
(
j
)
P_s(j)
Ps(j),我们有:
P
s
(
j
)
=
Φ
(
s
j
)
∑
k
=
1
n
Φ
(
s
k
)
P_s(j) = \frac{\Phi(s_j)}{\sum^n_{k=1}\Phi(s_k)}
Ps(j)=∑k=1nΦ(sk)Φ(sj)其中
s
j
s_j
sj表示object的分数。
引理7:top one概率在n个object的集合上组成概率分布。
定理8:给出两个ojbect j和k,若
s
j
>
s
k
,
j
≠
k
,
k
=
1
,
2
,
.
.
.
,
n
s_j > s_k, j \neq k, k=1, 2, ..., n
sj>sk,j=k,k=1,2,...,n,则
P
s
(
j
)
>
P
s
(
k
)
P_s(j) > P_s(k)
Ps(j)>Ps(k)
以上所有定理的证明见原文附录。
有了上面的top one概率,给出两列分数我们可以利用任意的度量元来度量两列分数间的距离。例如当用交叉熵作为度量时,listwise loss就会变成:
L
(
y
(
i
)
,
z
(
i
)
)
=
−
∑
j
=
1
n
P
y
(
i
)
(
j
)
l
o
g
(
p
z
(
i
)
(
j
)
)
L(y^{(i)}, z^{(i)}) = -\sum^n_{j=1}P_{y^{(i)}}(j)log(p_{z^{(i)}}(j))
L(y(i),z(i))=−j=1∑nPy(i)(j)log(pz(i)(j))
训练方法:ListNet
本节依旧以文档召回为例。我们将基于神经网络的排序函数表示为
f
ω
f_\omega
fω,给出一个特征向量
x
j
(
i
)
x_j^{(i)}
xj(i),
f
ω
(
x
j
(
i
)
)
f_\omega(x_j^{(i)})
fω(xj(i))表示它的分数。为简化过程,我们定义1中的
Φ
\Phi
Φ为一个指数函数,于是定理6可以写成:
P
s
(
j
)
=
Φ
(
s
j
)
∑
k
=
1
n
Φ
(
s
k
)
=
e
x
p
(
s
j
)
∑
k
=
1
n
e
x
p
(
s
k
)
P_s(j) = \frac{\Phi(s_j)}{\sum^n_{k=1}\Phi(s_k)} = \frac{exp(s_j)}{\sum^n_{k=1}exp(s_k)}
Ps(j)=∑k=1nΦ(sk)Φ(sj)=∑k=1nexp(sk)exp(sj)
给出query
q
(
i
)
q^{(i)}
q(i),排序函数
f
ω
f_\omega
fω能够生成一个分数list
z
(
i
)
(
f
ω
)
=
(
f
ω
(
x
1
(
i
)
)
,
f
ω
(
x
2
(
i
)
)
,
.
.
.
,
f
ω
(
x
n
(
i
)
(
i
)
)
)
z^{(i)}(f_\omega) = (f_\omega(x_1^{(i)}), f_\omega(x_2^{(i)}), ..., f_\omega(x_{n^{(i)}}^{(i)}))
z(i)(fω)=(fω(x1(i)),fω(x2(i)),...,fω(xn(i)(i))),若采用交叉熵作为度量,query的loss可以写作:
L
(
y
(
i
)
,
z
(
i
)
(
f
ω
)
)
=
−
∑
j
=
1
n
(
i
)
P
y
(
i
)
(
x
j
(
i
)
)
l
o
g
(
P
z
(
i
)
(
f
ω
)
(
x
j
(
i
)
)
)
L(y^{(i)}, z^{(i)}(f_\omega)) = - \sum^{n^{(i)}}_{j=1}P_{y^{(i)}}(x_j^{(i)})log(P_{z^{(i)}(f_\omega)}(x_j^{(i)}))
L(y(i),z(i)(fω))=−j=1∑n(i)Py(i)(xj(i))log(Pz(i)(fω)(xj(i)))
读这篇文章的目的是为了读Session-aware Information Embedding for E-commerce ProductRecommendation,所以实验部分有缘再写(。















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









