






【引用格式】:Jiang H, Karpur A, Cao B, et al. OmniGlue: Generalizable Feature Matching with Foundation Model Guidance[J]. arXiv preprint arXiv:2405.12979, 2024.
【网址】:https://arxiv.org/pdf/2405.12979
【开源代码】:https://github.com/google-research/omniglue
目录
一、瓶颈问题
当前的可学习特征匹配技术虽然在传统基准测试中表现优异,但在面对新颖图像域时,泛化能力有限,难以应用于实际世界的多样场景。
二、本文贡献
文中提出了一种名为OmniGlue的全新可学习图像匹配器,以泛化作为核心原则。首先,OmniGlue利用了视觉基础模型(DINOv2)的广泛知识来指导特征匹配过程,达到增强模型在训练时未见过的图像域上的泛化能力。另外,OmniGlue提出了一种新的关键点位置引导的注意力机制,通过解耦空间信息和外观信息(关键点位置特征p和局部描述符d),提高了匹配描述符的质量和泛化能力。
三、解决方案
OmniGlue首先将输入图像通过SuperPoint进行处理,生成关键点和局部描述符。接着,DINOv2对输入图像进行处理,生成全局特征,与SuperPoint生成的局部描述符结合。然后,在融合的特征上应用关键点位置引导的注意力机制,生成最终的匹配描述符。最终,根据生成的描述符在不同图像之间进行特征匹配,得到匹配对。
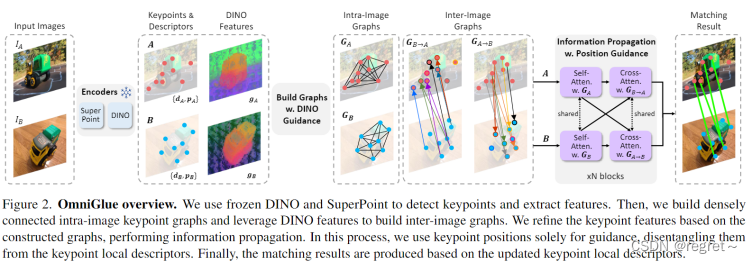
1 特征提取
对于输入的两张图像IA和IB,使用SuperPoint提取关键点和描述符,提取到的Superpoint关键点集表示为A:={A1, ... , ..., AN}和B:={B1, ..., ..., BM},N和M分别是IA和IB中识别到的关键点数量,每个关键点与其SuperPoint局部描述符关联。其中,归一化关键点位置使用位置嵌入进行编码,这里使用了MLP层来进一步细化,将关键点的结果位置特征表示为p。此外,对两幅图像提取密集的DINOv2特征图,通过SuperPoint提取到的关键点位置对特征图进行插值,得到每个关键点的DINOv2描述符,记为g。最终会得到集合A和集合B,集合A可表示为:、
和
。OmniGlue模型则是为了估计两个关键点集A和B之间的对应关系。
2 利用DINOv2构建图
文中共构建了四个关键点关联图:两个图像间图和两个图像内图。
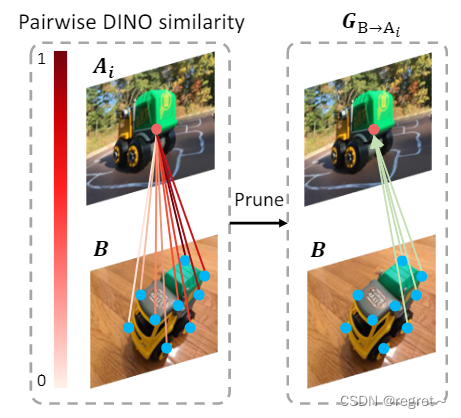
两个图像间图表示两幅图像关键点之间的连接。两个图像间图是有向的,其中信息从源节点传播到目标节点。这里利用DINOv2特征来指导图像间图的构建,以为例,对于关键点集A中的每个关键点Ai,计算其与集合B中所有关键点的DINOv2特征的相似性(在计算相似性之前对DINOv特征
和
执行通道归一化)。文中选择具有最大DINOv2相似度的几何B中的上半部分关键点与Ai连接。
图像内图表示属于同一图像的关键点之间的连接。这里它们是无向的,信息在连接的关键点之间双向传播,每个关键点都与同一图像中的所有其他关键点紧密相连。
3 具有新颖指导的信息传播
这里基于关键点图执行信息传播,该模块包含多个块,每个块有两个注意力层。第一个基于图像内图更新关键点,执行自注意;第二个基于图像间图更新关键点,执行交叉注意。与之前工作不同的是,这里引入了两个新的元素:分别来自DINOv2和关键点位置的指导。
3.1 DINOv2指导
在交叉注意期间,对于关键点Ai,它只聚合来自从B中选择的DINOv2-pruned潜在匹配集的信息,而不是所有关键点。DINO的广泛知识可以指导模型在训练时没有看到的域中的特征匹配过程,有助于广义图像匹配。通过这种方式,来自不相关关键点的信息不会融合到查询关键点特征中。其还鼓励交叉注意模块专注于区分较小潜在的匹配集中的匹配点。【由于在某些情况下DINO也可能不正确,这里不会强制将匹配空间限制为潜在的匹配集】
3.2 关键点指导
之前的方法在特征传播过程中,将关键点位置特征和局部描述符纠缠在一起,使得模型过于依赖学习到的位置相关先验。而对于在训练时没有看到的匹配模式的图像对下,学习到的先验很容易受到攻击,限制了泛化能力。针对这一问题,文中提出了一种新颖的位置引导注意力,它解开了关键点位置特征p和局部描述符d。位置信息被用作该模块中的空间上下文,不包含在用于匹配的最终局部描述符中。
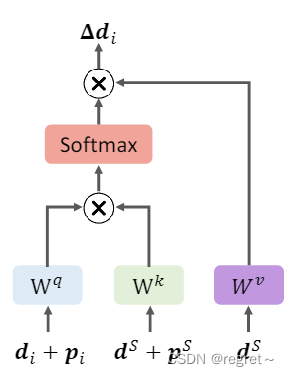
有了以上的新颖的元素,文中的注意力层如上图所示,取关键点Ai为例,定义如下:
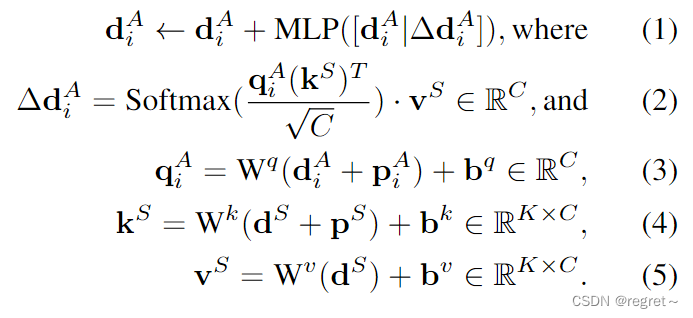
- 如公式1所示:注意力有一个残差连接,它集成了注意力更新值
。<----更新操作;[·|·]:通道级联
- 如公式2所示:计算图中关键点Ai与其源连接关键点之间的特征相似度,记为包含K个关键点的S。注意的查询、键和值分別是
、
和
,计算如公式3-5所示。
- 在自注意中,S是由所有关键点组成;在交叉注意中,S包含DINO识别的关键点。
4 匹配层和损失函数
文中通过细化的关键点表示来生成成对相似矩阵,其中S_{i,j} = d_{i}^{A}\cdot (d_{j}^{B})^{T}。得到相似矩阵之后,使用Sinkhorn算法来细化相似度,产生匹配矩阵
,其中
表示关键点Ai和Bj之间的匹配概率。损失函数则是参考自SuperPoint与LoFTER,在训练中,将匹配矩阵的付对视似然与基本事实最小化。
四、实验结果
1 实验
在SuperPoint和LightGlue之后,文中首先在SH100上训练OmniGlue来初始化OmniGlue,然后在SH200上进一步预训练OmniGlue,最后在MegaDepth上训练OmniGlue。文中在每个训练域的测试拆分上评估OmniGlue和所有基线方法,并测试它们对后续训练数据集或域外测试数据集的泛化。最后,文中尝试将OmniGlue适应具有有限目标域训练数据的域外图像。
1.1 数据集
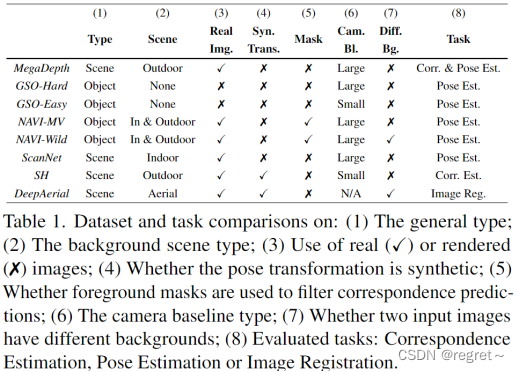
实验中用到的数据集如下表所示:
1.2 从合成单应性到MegaDepth
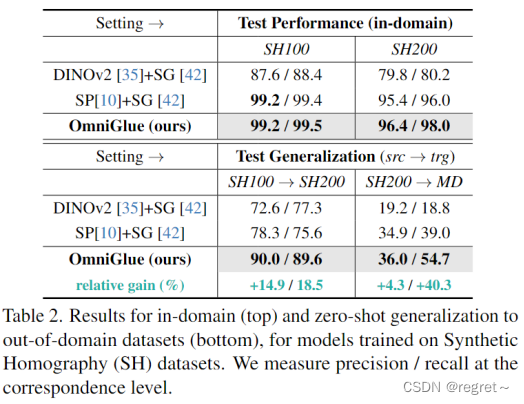
与基本方法 SuperGlue 相比,OmniGlue 不仅在域内数据上表现出卓越的性能,而且表现出稳健的泛化。即使数据分布从 SH100 转移到 SH200 最小,SuperGlue 的性能也会大幅下降,精度和召回率降低了 20%。这一结果表明,SuperGlue过度依赖于学习到的与位置相关的模式,无法处理进一步的图像扭曲失真。相比之下,OmniGlue 展示了强大的泛化能力,超过了 SuperGlue,精度提高了 12%,召回率提高了 14%。同样,在从SH200转移到Megadepth的过程中,OmniGlue优于SuperGlue,召回率提高了15%。
1.3 从MegaDepth到域外数据
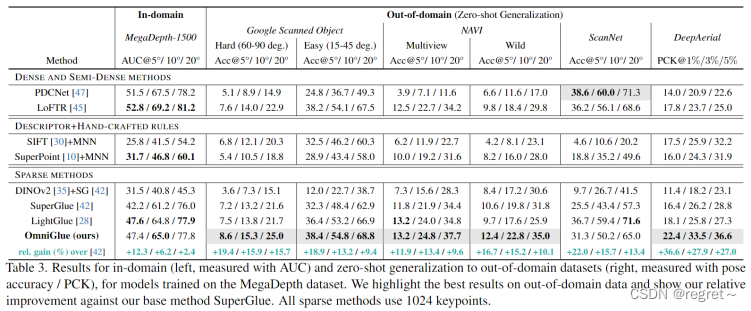
与所有其他方法相比,OmniGlue 不仅在 MegaDepth-1500 和最先进的稀疏匹配器 LightGlue 上实现了相当的性能,而且在 6 个新领域中的 5 个上表现出更好的泛化能力。具体来说,在MegaDepth-1500上,OmniGlue相对于基本方法SuperGlue表现出12.3%的相对增益(姿势AUC@5°)。在6个新领域中,OmniGlue分别比SuperGlue和LightGlue显示出20.9%和9.5%的平均相对增益(对于最紧阈值的姿态和配准精度)。此外,OmniGlue 在更难的新领域与 LightGlue 表现出更大的性能提升,即在 GSO-Hard、NAVI-Wild 和 DeepAerial 上。我们在图 5 和图 4 中展示了可视化,用于对新领域进行零样本泛化及其在源域上的性能。
值得注意的是,密集匹配器在域内 MegaDepth 数据集上取得了更好的性能,泛化更差。而SuperGlue的性能接近甚至更差,域内 AUC@5° 降低了 10%。文中推测这可能是由于视觉描述符和匹配模块的联合学习,使它们更容易强烈地专门化到训练领域。


1.4 使用少数图像微调
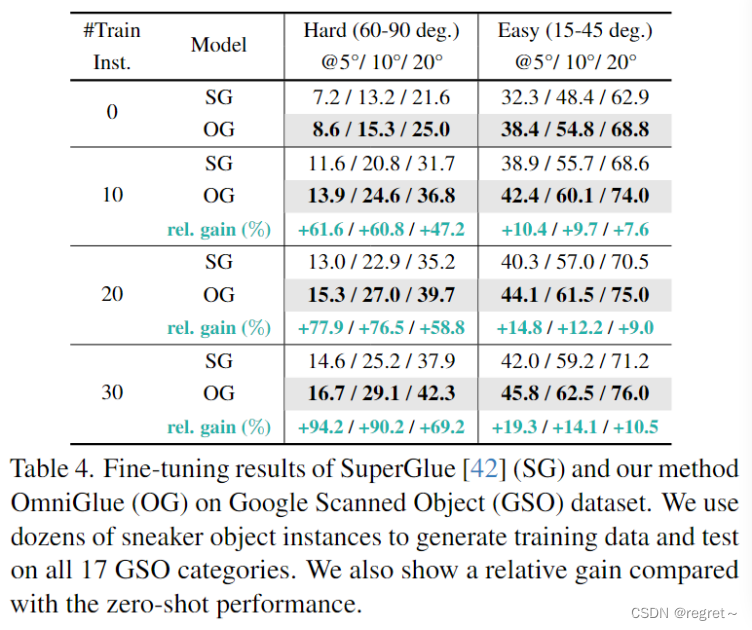
OmniGlue 更容易适应目标域。具体来说,当从 0 到 30 个实例进行缩放进行训练时,OmniGlue 在两个测试子集中都始终表现出增强的性能。仅使用 10 个实例进行训练,OmniGlue 在两个子集上将姿态估计准确率提高了 5.3% 和 4.0%。通过合并 10 个更多对象来扩展训练集可以进一步提高 2%。此外,OmniGlue 始终优于 SuperGlue,在所有实验中实现了大约 10% 的相对增益。结果共同证明了OmniGlue在现实场景中作为一种通用和可推广的方法的适用性。
2 消融实验
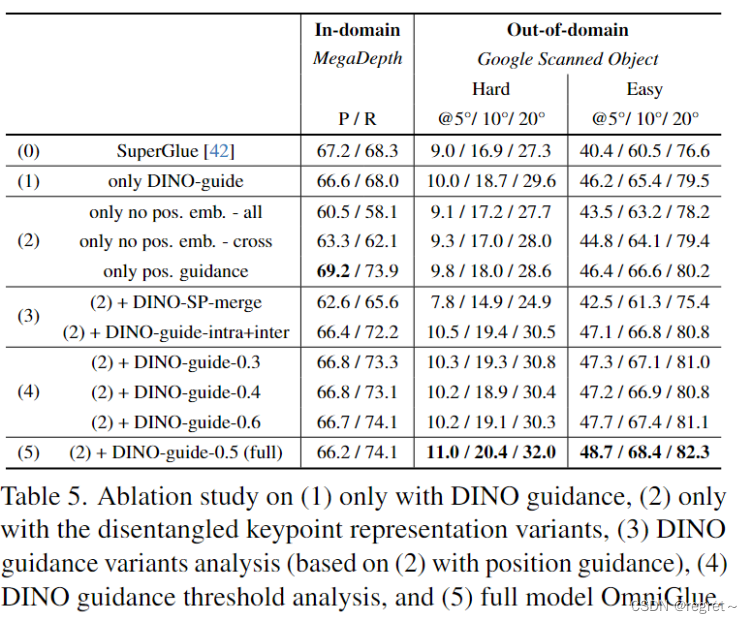
表 5 (1) 中的结果突出了文中基础模型指导的有效性,增强了域外数据的泛化能力。此外,表 5 (2) 的第三行说明了位置引导注意力的影响,展示了域内和域外数据的改进。此外,文中使用不同的方法来解开关键点位置特征。表 5 (2) 的前两行表明,当不使用任何位置特征或仅在 selfattention 上应用位置引导时,性能会下降(没有交叉注意的位置引导)。这强调了文中的位置引导注意力在促进图像内和图像间上下文中的信息传播方面的有效性。此外,在去除位置嵌入后,即使域内性能下降,模型也显示出更好的泛化。这一结果表明,SuperGlue 使用位置信息的不合适方式限制了其泛化。
如表 5 (3) 所示,文中探索了合并 DINOv2 的不同方法。第一个涉及合并 DINO 特征和 SuperPoint 局部描述符。这种集成是在使用 MLP 的信息传播模块之前执行的。实验表明性能下降,这表明这两个特征不兼容,这可能是由于 DINO 的粗粒度。这些特征可以有效合并的方式仍然是一个悬而未决的问题。第二种方法需要应用DINOv2指导来构建图像内图和图像间图,与(5)相比,性能下降。文中假设原因在于图像内信息传播(self-attention)需要一个全局上下文,特别是对于区分特征空间中的所有关键点。减少图像内图的连通性会对全局上下文产生不利影响,这与SuperGlue中注意力跨度研究的发现一致。















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









