









摘要
AMP是生物体内产生的具有杀菌活性的碱性物质,天然的AMPs还具有如伤口愈合、抗氧化和免疫调节作用等重要活性,AMPs被誉为是抗生素最好的替代品。但研究AMP使用的湿实验方法既昂贵又难度大,需要新技术来解决这一问题。近年来,深度学习方法已被用于研究AMP且效果显著。本文作者提出一种新的深度学习方法来预测AMPs,其可以高精度的分类出10~200长度的AMP和non-AMP,同时结果表明,在不降低其他指标的情况下此模型依旧可以在独立数据验证方面的精度比目前最好的模型还高1.05%。
数据集
文中作者使用的数据集是来自于Sharma等人的文章中所使用的数据集,文章如下。AniAMPpred: artificial intelligence guided discovery of novel antimicrobial peptides in animal kingdom | Briefings in Bioinformatics | Oxford Academic
此数据集中,AMPs取自于NCBI和StarPepDB数据库,non-AMPs则取自于UniProt数据库。通过去重后最终获得10,187个AMPs和10,422个non-AMPs。然后以65:35的比例分为cross-validation和independent集。
模型
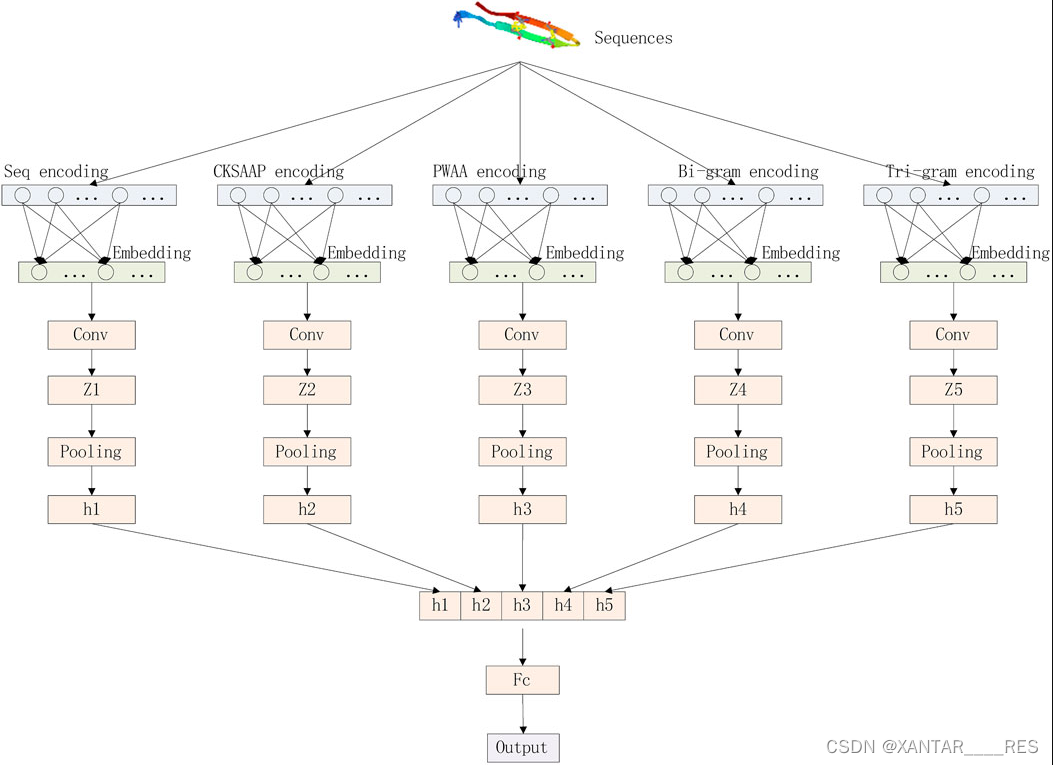
模型结构如上图所示。其主要有encoding层、embedding层和CNN网络组成。首先介绍一下encoding层,这里使用了五种encoding方法来处理序列数据,可总结为如下4种方法:
- Raw sequence encoding。这个比较好理解,它将20种氨基酸编号,然后代入到任意序列中便得到了序列编码。例如,一个蛋白质序列FLPKLFAKITKKNMAHIRC,其编码结果为[5,10,13, 9, 10, 5, 1, 9, 8, 17, 9, 9, 12, 11, 1, 7, 8, 15, 2]。
- Composition of k-space amino acid pairs(CKSAAP)encoding。字面意思解释就是氨基酸对,如果K=0(即氨基酸之间的间隔为0),则总共有(AA, AC, AD, ..., YY)400对;若K=1(即间隔为1),则总共有(A口A, A口C, .., Y口Y)也是400对;若K=2,则为A口口A等等依此往后。然后计算下公式
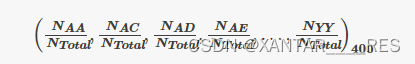 ,Ntotal=L-K-1,L为序列长。
,Ntotal=L-K-1,L为序列长。 - Position weighted amino acid composition(PWAA)encoding。即各个氨基酸在序列中的权重,以序列中心为观测点,计算权重,公式为
 ,Ci表示氨基酸ai的权重,若ai在序列的第j个未知,则Xi,j=1,反之为0。可看出若ai离序列中心越近,则Ci越趋近于0.
,Ci表示氨基酸ai的权重,若ai在序列的第j个未知,则Xi,j=1,反之为0。可看出若ai离序列中心越近,则Ci越趋近于0. - N-gram encoding。这个也好理解,举个例,在N=2时,给定序列为S= (s1, s2, … sn),则被编码为S2=(s1s2,s2s3, … ,s(n-1)sn)。
如模型图所示,5种编码方法对序列进行编码后,输入到embedding层,然后各自在通过一层conv层+Pooling层,最后concate,最终输入到FC层得到最终输出。
总结
文章通过结合CKSAAP、PWAA、N-gram和raw sequence encoding和一个深度学习方法来预测AMPs。可以看出,不同的encoding方法都有各自的优点和各自的缺点,本文通过结合它们来互相弥补达到更好的预测效果。本文的方法也存在一定缺陷,它只能够识别AMPs,不能分析AMPs的具体的作用特性。















 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









