










 本文探讨了在多人共用服务器环境下,如何有效管理和释放被占用的GPU资源。通过使用nvidia-smi查看GPU占用情况,结合ps和vi/proc/<pid>/environ命令,精确定位并释放不必要的GPU占用,特别适用于深度学习和机器学习场景。
本文探讨了在多人共用服务器环境下,如何有效管理和释放被占用的GPU资源。通过使用nvidia-smi查看GPU占用情况,结合ps和vi/proc/<pid>/environ命令,精确定位并释放不必要的GPU占用,特别适用于深度学习和机器学习场景。
有时多人都在一段时间内同时使用公司共用的服务器上的GPU训练,有的网络的代码写得不好,虽然是按需获取GPU内存但停止训练了却仍然占用GPU没放,有的则采取的是预分配机制,一开始运行加载训练好了的模型时就占用大量内存(比如9-10G),没有进行识别推理也占用内存不放,多人共用的环境如果有人用完不及时停掉相关程序,很多GPU就被占了但空闲在那里,但又不好随便乱杀进程来释放,首先得确认一下,占用GPU的都是哪些程序,是否确实可以停掉,在不掌握谁在运行什么训练或识别程序的情况下,可以通过查看进程信息来确认。
首先,当然得借助平时必用的nvidia-smi来查看占用GPU的进程:
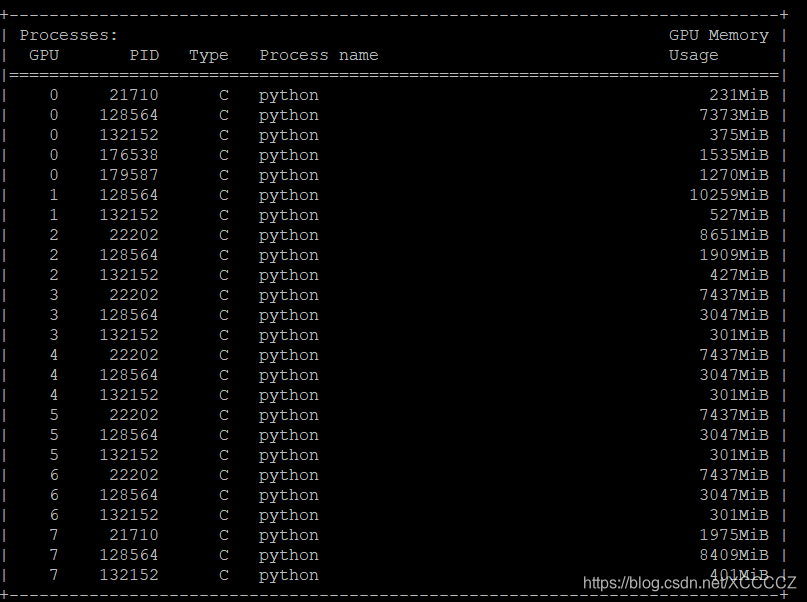
查看需要释放的GPU上的进程,首先使用最简单的 ps -ef|grep <pid>,例如,0号GPU中pid 128564这个进程占用了7.3G的内存,那首先就看它:
ps -ef|grep 128564
如果启动进程的命令行信息含有程序代码文件那就到这里就可以看出来是哪个程序了,但上面的命令输出结果让人失望,它的命令行只有个简单的python,python显然只是个执行程序,后面被执行的.py文件则没有,看了等于没看:

那就看进程文件里的environ,它里面记录了很多环境信息,看完基本可以猜出来是哪个程序启动后的进程:
sudo vi /proc/128564/environ
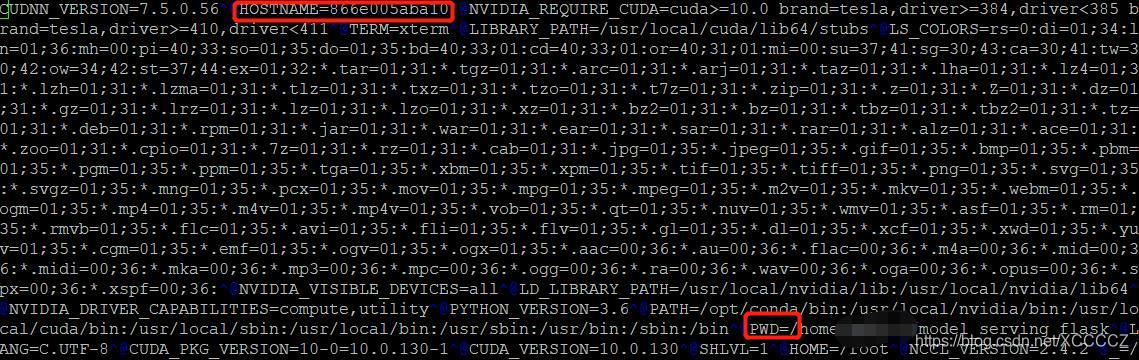
根据里面的PWD可以直接判定程序是在哪里,如果没有这项(一般是有这个值的),根据PATH与LD_LIBRARY_PATH以及CUDA和CUDNN等设置可以辅助综合判定是那个程序,另外如果程序是在docker容器内运行的话,里面还有个HOSTNAME,根据这个值,和docker ps命令输出的值比较可以知道这个程序进程是在哪个容器里运行,范围一下就缩小了,如果是docker容器里运行的进程,并且这个容器里的进程都不需要运行了,那么直接docker stop <container id>即可释放这些进程占用的GPU,对于物理机上运行的进程当然只有执行kill命令了。


















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











