






项目介绍:DBSCAN聚类算法
本项目使用Python中的scikit-learn库实现了DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法。DBSCAN是一种基于密度的聚类算法,能够有效地识别具有不同密度的聚类和离群点。
数据集生成
首先,我们使用sklearn.datasets中的make_moons函数生成了一个包含1000个样本的二维数据集。该数据集具有月牙形状,并添加了一些噪声。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05, random_state=42)
plt.plot(X[:, 0], X[:, 1], 'b.')
plt.show()
以上代码生成了一个散点图展示了生成的数据集。

DBSCAN聚类算法实现
接下来,我们使用sklearn.cluster中的DBSCAN类来实现DBSCAN算法。
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)
以上代码创建了一个DBSCAN对象,并使用fit方法对数据进行聚类。通过设置eps参数控制邻域的距离阈值,以确定邻域内的样本是否属于同一个簇。同时,通过设置min_samples参数指定邻域中最小样本数,用于判断核心样本。
这样,我们就可以使用DBSCAN算法对数据进行聚类了。
聚类结果分析
DBSCAN算法对每个样本进行标记,形成聚类结果。我们可以使用以下代码打印前10个样本的聚类标签和核心样本的索引。
print(dbscan.labels_[:10])
print(dbscan.core_sample_indices_[:10])
print(np.unique(dbscan.labels_))
dbscan.labels_存储了每个样本的聚类标签,dbscan.core_sample_indices_存储了核心样本的索引。np.unique(dbscan.labels_)返回聚类结果中的唯一标签。
这些属性提供了对DBSCAN聚类结果的重要信息。dbscan.labels_可以用于查看每个样本所属的聚类标签,负值表示噪声样本,而非负值表示有效聚类。dbscan.core_sample_indices_提供了核心样本的索引,这些样本在聚类结果中起到重要作用。
可视化聚类结果
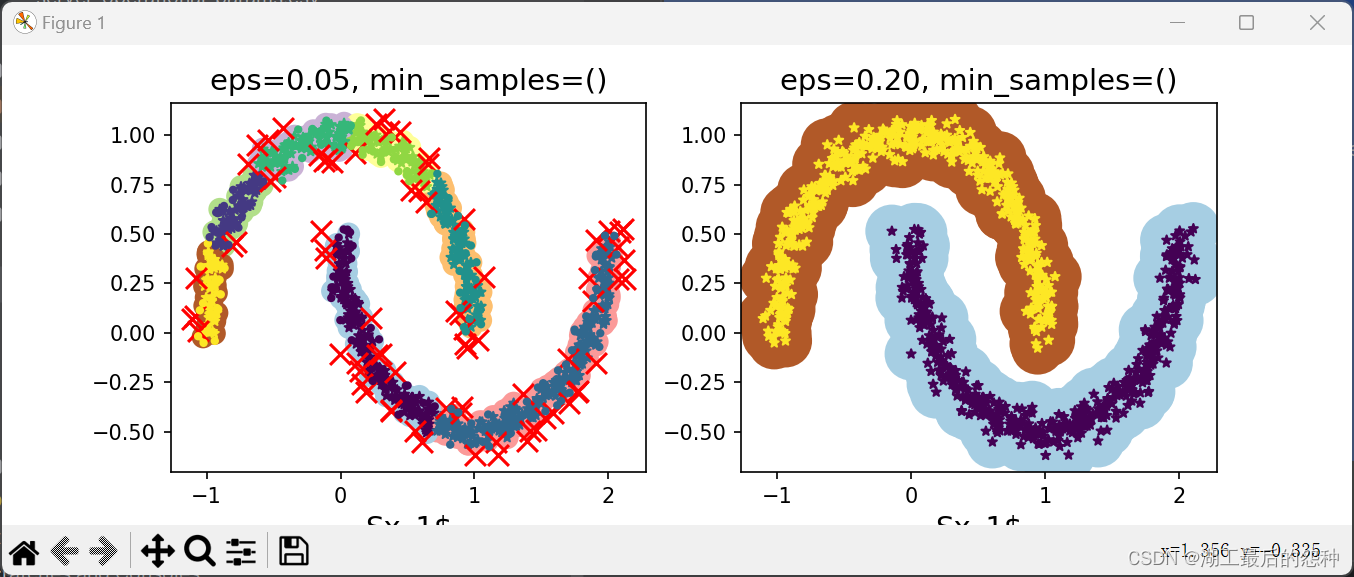
我们编写了一个辅助函数plot_dbscan来可视化DBSCAN算法的聚类结果。它将核心样本、离群点和非核心样本用不同的符号和颜色绘制在散点图上。
def plot_dbscan(dbscan, X, size, show_xlabels=True, show_ylabels=True):
core_mask = np.zeros_like(dbscan.labels_, dtype=bool)
core_mask[dbscan.core_sample_indices_] = True
anomalies_mask = dbscan.labels_ == -1
non_core_mask = ~(core_mask | anomalies_mask)
cores = dbscan.components_
anomalies = X[anomalies_mask]
non_cores = X[non_core_mask]
plt.scatter(cores[:, 0], cores[:, 1], c=dbscan.labels_[core_mask], marker='o', s=size, cmap="Paired")
plt.scatter(cores[:, 0], cores[:, 1], marker='*', s=20, c=dbscan.labels_[core_mask])
plt.scatter(anomalies[:, 0], anomalies[:, 1], c="r", marker="x", s=100)
plt.scatter(non_cores[:, 0], non_cores[:, 1], c=dbscan.labels_[non_core_mask], marker=".")
if show_xlabels:
plt.xlabel("X1", fontsize=14)
else:
plt.tick_params(labelbottom='off')
if show_ylabels:
plt.ylabel("X2", fontsize=14, rotation=0)
else:
plt.tick_params(labelleft='off')
plt.title("DBSCAN Clustering Result", fontsize=14)
plt.figure(figsize=(9, 3.2))
plt.subplot(121)
plot_dbscan(dbscan, X, size=100)
plt.subplot(122)
plot_dbscan(dbscan2, X, size=600, show_ylabels=False)
plt.show()
运行
plt.figure(figsize=(9, 3.2))
plt.subplot(121)
plot_dbscan(dbscan, X, size=100)
plt.subplot(122)
plot_dbscan(dbscan2, X, size=600, show_ylabels=False)
plt.show()
全部代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05, random_state=42)
plt.plot(X[:, 0], X[:, 1], 'b.')
plt.show()
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)
print(dbscan.labels_[:10])
print(dbscan.core_sample_indices_[:10])
print(np.unique(dbscan.labels_))
dbscan2 = DBSCAN(eps=0.2, min_samples=5)
dbscan2.fit(X)
print(dbscan2.labels_[:10])
print(dbscan2.core_sample_indices_[:10])
print(np.unique(dbscan2.labels_))
def plot_dbscan(dbscan, X, size, show_xlabels=True, show_ylabels=True):
core_mask = np.zeros_like(dbscan. labels_, dtype=bool)
core_mask[dbscan. core_sample_indices_] = True
anomalies_mask = dbscan. labels_== -1
non_core_mask = ~(core_mask | anomalies_mask)
cores = dbscan.components_
anomalies = X[anomalies_mask]
non_cores = X[non_core_mask]
plt. scatter(cores[:, 0], cores[:, 1],c=dbscan. labels_[core_mask], marker='o', s=size, cmap="Paired")
plt. scatter(cores[:, 0], cores[:, 1], marker='*', s=20, c=dbscan. labels_[core_mask])
plt. scatter(anomalies[:, 0], anomalies[:, 1],c="r", marker="x", s=100)
plt. scatter(non_cores[:, 0], non_cores[:, 1], c=dbscan. labels_[non_core_mask], marker=".")
if show_xlabels:
plt.xlabel("Sx_1$", fontsize=14)
else:
plt.tick_params(labelbottom=' off')
if show_ylabels:
plt.xlabel("Sx_1$", fontsize=14, rotation=0)
else:
plt.tick_params(labelleft=' off')
plt.title("eps={:.2f}, min_samples=()".format(dbscan.eps, dbscan.min_samples), fontsize=14)
plt.figure(figsize=(9, 3.2))
plt.subplot(121)
plot_dbscan(dbscan, X, size=100)
plt.subplot(122)
plot_dbscan(dbscan2, X, size=600, show_ylabels=False)
plt.show()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









