







1.简述GPS载波相位测量的基本原理?
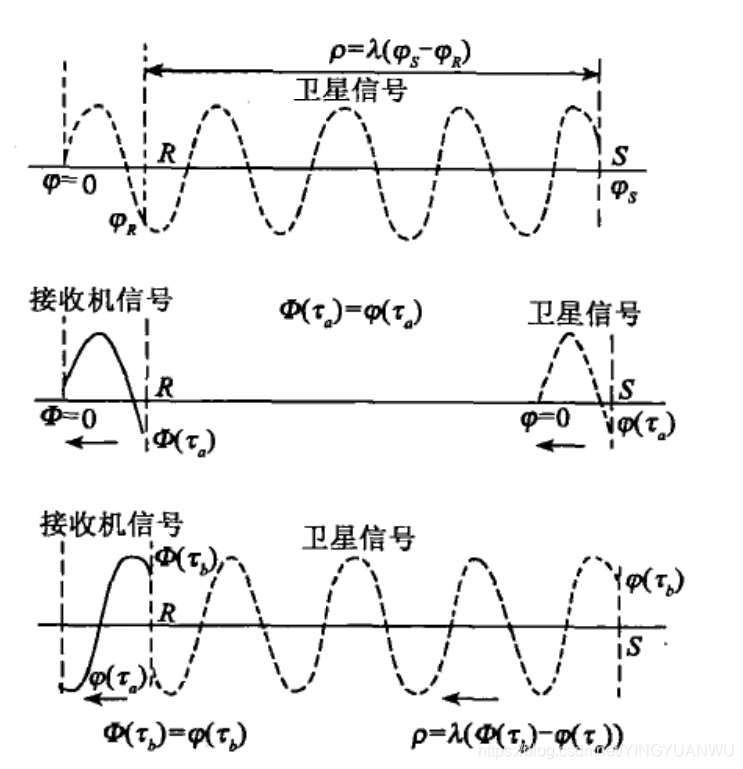
载波相位测量的观测量是GPS接收机所接收的卫星载波信号与接收机本振参考信号的相位差。
以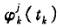 表示k接收机在接收机钟面时刻
表示k接收机在接收机钟面时刻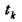 时所接收到的j卫星载波信号的相位值,
时所接收到的j卫星载波信号的相位值,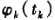 表示k接收机在钟面时刻
表示k接收机在钟面时刻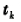 时所产生的本地参考信号的相位值,则k接收机在接收机钟面时刻
时所产生的本地参考信号的相位值,则k接收机在接收机钟面时刻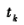 时观测j卫星所取得的相位观测量可写为
时观测j卫星所取得的相位观测量可写为
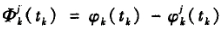
通常的相位或相位差测量只是测出一周以内的相位值。实际测量中,如果对整周进行计数,则自某一初始取样时刻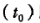 以后就可以取得连续的相位测量值。
以后就可以取得连续的相位测量值。
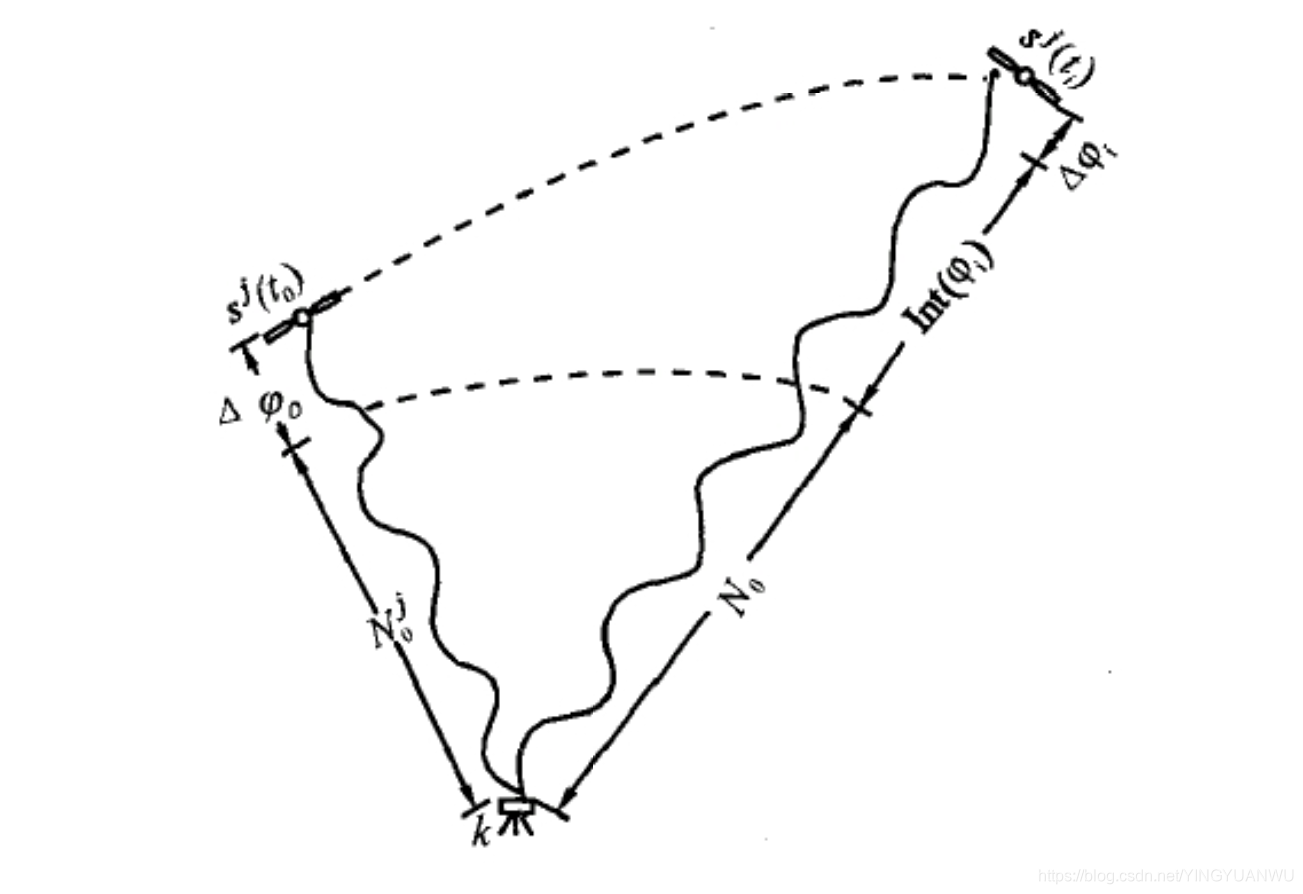
如下图,在初始t。时测得小于一周的相位差为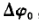 ,其整周数为
,其整周数为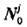 ,此时包含整周数的相位观测值应为
,此时包含整周数的相位观测值应为
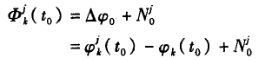
接收机继续跟踪卫星信号,不断测定小于一周的相位差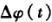 ,并利用整波计数器记录从t。到
,并利用整波计数器记录从t。到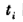 时间内的整周数变化量Int(φ),只要卫星
时间内的整周数变化量Int(φ),只要卫星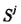 从t。到ti;之间卫星信号没有中断,则初始时刻整周模糊度
从t。到ti;之间卫星信号没有中断,则初始时刻整周模糊度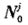 。就为一常数,这样,任一时刻1:卫星
。就为一常数,这样,任一时刻1:卫星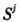 到k接收机的相位差为
到k接收机的相位差为
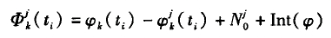
上式说明,从第一次开始,在以后的观测中,其观测量包括了相位差的小数部分和累计的整周数。
2.在高精度GPS测量工作中,为什么需要采用载波相位测量方法进行三维定位?
伪距测量是以测距码作为量测信号的。采用码相关法时,其测量精度一般为码元宽度的百分之一。由于测距码的码元宽度较大,因而测量精度不高。对精码而言约为±0.3m,对C/A码而言,则为±3m左右,只能满足卫星导航和低精度定位的要求。载波的波长要短得多,λ1=19.0cm,λ2=24.4cm,λ5=25.5cm。因而如果把载波当作测距信号来使用(如电磁波测距中的调制信号那样),对载波进行相位测量,就能达到很高的精度。早期测量型接收机的载波相位测量精度一般为2~3mm,目前测量型接收机的载波相位测量的精度为0.2-0. 3mm,其测距精度比测码伪距的精度要高2~3个数量级。
但载波是–种没有任何标记的余弦波,而用接收机中的鉴相器来量测载波相位时能测定的只是不足一周的部分,因而会产生整周数不确定的问题。此外,整周计数部分还可能产生跳变的问题,故在进行数据处理前,还需进行整周跳变的探测和修复工作,使得载波相位测量的数据处理工作变得较为复杂、麻烦,这是为获得高精度定位结果必须付出的代价。
3.载波相位测量中,确定整周未知数主要有哪些方法?
1.伪距法
2.将整周未知数当做平差中的待定参数一经典方法
(1)整数解
(2)实数解
3.多普勒法(三差法)
4.快速确定整周未知数法
采用这种方法进行短基线定位时,利用双频接收机只须观测一分钟便能成功地确定整周未知数。
这种方法的基本思路是,利用初始平差的解向量(接收机点的坐标及整周未知数的实数解)及其精度信息(单位权中误差和方差协方差阵),以数理统计理论的参数估计和统计假设检验为基础,确定在某一置信区间整周未知数可能的整数解的组合,然后依次将整周未知数的每一组合作为已知值,重复地进行平差计算。其中使估值的验后方差或方差和为最小的一组整周未知数,即为整周未知数的最佳估值。
这一快速解算整周未知数的方法,实践表明,在基线长小于15km时,根据数分钟的双频观测结果,便可精确地确定整周未知数的最佳估值,使相对定位的精度达到厘米级。
5.静态法:把整周未知数作为待定参数,在平差计算中与其他未知数一起出。
6.动态法:当移动载体处于静止状态时,通过与地面参考站一起”初始化"确定整个周期的未知数量,然后移动载体开始移动和定位














 5043
5043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









