







注意力机制
注意力机制是一种在深度学习中广泛使用的技术,尤其在自然语言处理(NLP)和计算机视觉领域中。它的核心思想是模拟人类的注意力过程,即在处理大量信息时,关注最相关或最重要的部分。
在深度学习模型中,注意力机制可以帮助模型在处理序列数据(如文本或时间序列)时更有效地分配计算资源。它可以识别出输入数据中的关键部分,并侧重于这些部分来做出更准确的预测或生成更合理的输出。
工作原理
-
打分机制(Scoring Mechanism):这是注意力机制的第一步。模型计算输入序列中每个元素对当前任务的重要性。例如,在翻译任务中,模型会评估源语言中每个单词对生成目标语言中下一个单词的重要性。
-
权重分配(Weight Assignment):基于打分机制得出的分数,模型分配权重给输入序列的不同部分。这些权重确定了每部分在最终输出中的影响程度。
-
加权和(Weighted Sum):模型将输入序列的加权版本整合起来,形成一个单一的、加权的表示,这个表示捕获了对当前任务最重要的信息。
-
输出:最后,这个加权的表示被用来做出预测或生成输出。
应用
在自然语言处理中的应用:
在自然语言处理中,注意力机制通常应用于序列到序列(sequence-to-sequence)的任务,如机器翻译。
-
编码器-解码器框架: 注意力机制可以用于提高编码器对输入序列的关注度,同时允许解码器在生成输出序列时对输入的不同部分进行不同程度的关注。
-
自注意力(Self-Attention): 在自注意力机制中,模型可以对序列中的不同位置赋予不同的权重,以便更好地捕捉序列内部的依赖关系。
编码器-解码器架构
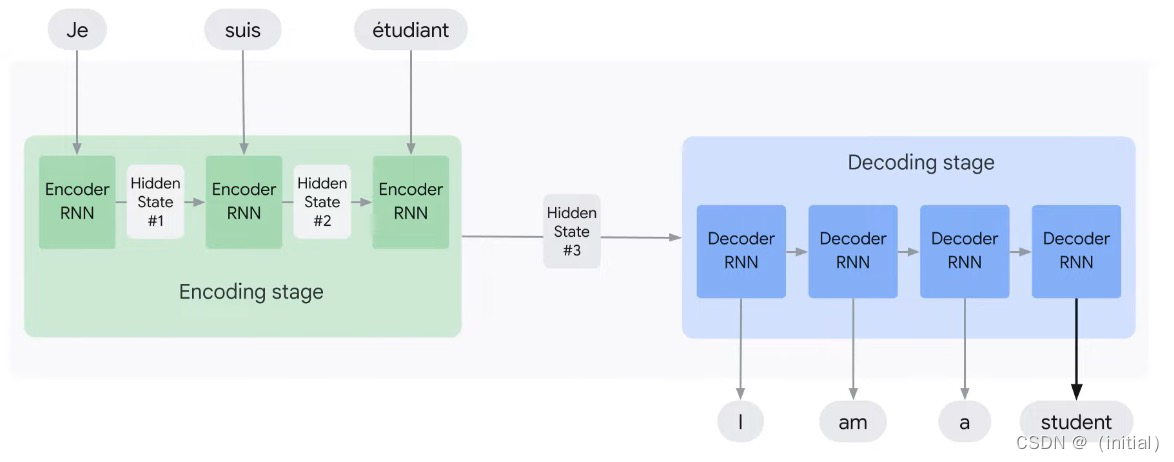

这张图片展示了带有注意力机制的编码器-解码器架构的一个视觉概述。在这个架构中,编码器部分将输入语言(如法语)的句子“Je suis étudiant”转换为一系列隐藏状态,每个隐藏状态对应于输入句子中的一个单词。然后,解码器部分使用这些隐藏状态来逐个生成目标语言(如英语)的句子“I am a student”。
在没有注意力机制的传统编码器-解码器模型中,解码器仅依赖于编码器的最终隐藏状态来生成翻译。这可能导致信息丢失,尤其是在处理长句子时。
引入注意力机制后,解码器在生成每个单词时都会考虑编码器所有隐藏状态的加权组合,这个权重由注意力网络计算。注意力机制允许解码器“关注”输入句子中与当前生成的单词最相关的部分。
从图中可以看到,编码阶段后,每个编码器RNN的输出(隐藏状态)都直接连接到注意力网络。在解码阶段,每个解码器RNN都接收来自注意力网络的加权上下文向量,这个向量结合了所有相关的编码器隐藏状态。注意力网络会动态调整这些权重,使得解码器在生成每个单词时都“关注”输入中不同的部分。
总的来说,这张图描绘了通过注意力机制增强的编码器-解码器模型,这种架构在机器翻译和其他序列到序列任务中非常有效,能够改善模型对长距离依赖关系的处理能力,并提高翻译质量。
软注意力与硬注意力:
-
软注意力(Soft Attention): 通过对所有输入进行加权求和,权重为实数,是一个概率分布,总和为1。Soft Attention允许模型对所有输入进行柔性的关注。
-
硬注意力(Hard Attention): 选择输入中最重要的一部分,其他部分被忽略。通常使用采样或者最大值操作来选择。
注意力机制是一种影响深远的技术,它在深度学习,尤其是在自然语言处理(NLP)中有着广泛的应用。以下是注意力机制的一些主要特点和优势:
特点
-
上下文感知:
- 注意力机制能够在生成每个输出时考虑整个输入序列的信息,而不是仅依赖于固定的上下文状态。
-
选择性关注:
- 类似于人类的注意力,它可以选择性地集中在输入数据的最重要部分,忽略不相关的信息。
-
动态权重:
- 它为输入序列的每个部分动态分配权重,这些权重表明了当前任务对不同输入部分的依赖程度。
-
可解释性:
- 通过观察模型的注意力分布,我们可以获得模型决策过程的一些直观理解。
-
序列对齐:
- 在机器翻译等任务中,注意力机制可以帮助模型学习输入和输出序列之间的对齐方式。
优势
-
性能提升:
- 在许多任务中,注意力机制提高了模型的性能,尤其是在长序列或需要复杂关系理解的任务中,如机器翻译和文本摘要。
-
处理长序列:
- 注意力机制特别适合处理长序列数据,因为它允许模型在不丢失信息的情况下处理远距离的依赖关系。
-
灵活性:
- 它可以与各种模型架构配合使用,如循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)和Transformer。
-
并行计算:
- 在Transformer模型中,利用自注意力(self-attention)机制可以实现更高效的并行计算。
-
减少信息损失:
- 传统的Seq2Seq模型通常面临信息瓶颈问题,而注意力机制通过直接访问输入序列的每个部分来减少信息损失。
-
多任务和多模态应用:
- 注意力机制在多任务学习和多模态任务(如图像标题生成)中也表现出了它的灵活性和有效性。
综上所述,注意力机制通过提供一种直观的方式来聚焦模型的计算资源,有效地解决了深度学习模型中的一些关键挑战,尤其是在处理序列数据时。它不仅提高了模型的性能,还增加了模型行为的可解释性。
带有注意力机制的编码器-解码器

图片展示了带有注意力机制的编码器-解码器(Encoder-Decoder)架构,这是机器翻译中常用的模型。在该模型中,编码器将输入序列转换为一系列隐藏状态,解码器则使用这些隐藏状态来逐步生成输出序列。注意力机制允许解码器在生成每个输出时,聚焦于输入序列中最相关的部分。这里,我们将根据图片中的信息推导出模型的数学表达式和工作原理。
编码阶段
-
编码:
-
输入序列 ( x = (x_1, …, x_T) ) 由 ( T ) 个元素组成。
-
每一步 ( i ),编码器更新其隐藏状态 ( h_i ):
h i = f ( x i , h i − 1 ) h_i = f(x_i, h_{i-1}) hi=f(xi,hi−1)
-
-
( f ) 是编码器RNN的非线性转换函数。
解码阶段
-
上下文向量 ( c ):
-
传统的编码器-解码器模型使用最后的隐藏状态 ( h_T ) 作为上下文向量 ( c )。
-
在带有注意力的模型中,上下文向量 ( c_j ) 对于每个解码步骤 ( j ) 都是不同的,它是输入序列隐藏状态的加权和:
c j = ∑ i = 1 T α i j h i c_j = \sum_{i=1}^{T} \alpha_{ij} h_i cj=i=1∑Tαijhi
-
-
注意力权重 ( \alpha_{ij} ):
-
注意力权重 ( \alpha_{ij} ) 是通过一个对齐函数 ( a ) 计算得出的,这个函数比较了查询表示(解码器的当前隐藏状态 ( s_{j-1} ))与键表示(编码器的隐藏状态 ( h_i )):
α i j = exp ( e i j ) ∑ k = 1 T exp ( e k j ) \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{T} \exp(e_{kj})} αij=∑k=1Texp(ekj)exp(eij)e i j = a ( s j − 1 , h i ) e_{ij} = a(s_{j-1}, h_i) eij=a(sj−1,hi)
-
( e_{ij} ) 是一个能量分数,通常通过点积、加性或其他兼容的函数来计算。
-
-
解码和生成输出:
-
解码器的每一步 ( j ),基于前一步的输出 ( y_{j-1} ),前一步的隐藏状态 ( s_{j-1} ) 和当前的上下文向量 ( c_j ) 来更新其状态 ( s_j ):
s j = f ( s j − 1 , y j − 1 , c j ) s_j = f(s_{j-1}, y_{j-1}, c_j) sj=f(sj−1,yj−1,cj) -
然后基于 ( s_j ) 和 ( c_j ) 生成下一个输出 ( y_j ):
y j = g ( y j − 1 , s j , c j ) y_j = g(y_{j-1}, s_j, c_j) yj=g(yj−1,sj,cj) -
( g ) 是输出层的非线性函数。
-
图片中的表格也比较了传统的编码器-解码器架构和带有注意力模型的架构。在注意力模型中,生成的上下文向量 ( c_j ) 允许模型在每一步解码时都聚焦于输入序列的最相关部分,而不是像传统模型那样只使用最后的隐藏状态。这种机制显著提高了机器翻译的质量,因为它可以捕捉长距离依赖,并更好地处理不同长度的输入序列。
如何实现注意力机制
实现注意力机制通常涉及以下几个关键步骤:
-
定义注意力分数函数:首先,需要定义一个函数来计算查询(query)、键(key)和值(value)之间的注意力分数。这些分数表示输入数据中的每个元素对于当前处理的元素(例如,翻译任务中的当前单词)的重要性。常见的分数函数包括点积注意力和加性/双线性注意力。
-
计算注意力分数:使用上述函数计算查询(例如,解码器的当前隐藏状态)与所有键(例如,编码器的所有隐藏状态)之间的注意力分数。
-
应用softmax函数:对这些分数应用softmax函数,以获得标准化的权重,这些权重的总和为1。这一步骤确保了模型关注输入数据的特定部分。
-
计算加权和:用这些softmax权重对值进行加权求和。这样,模型会生成一个加权的表示,重点关注对当前任务最重要的输入部分。
-
结合上下文:将注意力加权和与查询结合起来(例如,通过拼接或加法操作),用于后续的处理或作为最终的输出。
机器翻译
当然可以。在机器翻译中,尤其是使用带有注意力机制的序列到序列(Seq2Seq)模型时,整个过程包括编码、注意力计算和解码阶段。我们可以通过一系列公式来推导这个过程。
 model with attention mechanism in machine translation. The diagram shows the encoding phase .png)](https://img-blog.csdnimg.cn/direct/5a32e93200fb408aae303a3be76a9e8c.png)
编码阶段
假设输入序列是 ( X = {x_1, x_2, …, x_n} ),其中 ( x_i ) 是序列中的单词。
-
词嵌入:
-
每个输入单词 ( x_i ) 被转换为嵌入向量 ( e(x_i) )。
-
e ( x i ) ∈ R d e(x_i) \in \mathbb{R}^d \ e(xi)∈Rd
,其中 ( d ) 是嵌入维度。
-
-
通过编码器 RNN:
-
编码器是一个RNN,每一步接收一个嵌入向量并更新其隐藏状态。
-
h i = RNN ( e ( x i ) , h i − 1 ) h_i = \text{RNN}(e(x_i), h_{i-1}) hi=RNN(e(xi),hi−1)
-
其中 ( h_i ) 是第 ( i ) 步的隐藏状态。
-
-
编码器输出:
- 编码器的每个隐藏状态 ( h_i ) 作为键 ( K ) 和值 ( V ):
- K = V = { h 1 , h 2 , . . . , h n } K = V = \{h_1, h_2, ..., h_n\} K=V={h1,h2,...,hn}
解码阶段(带注意力机制)
假设目标序列是 ( Y = {y_1, y_2, …, y_m} ),我们需要逐步生成这个序列。
-
初始化解码器:
- 初始隐藏状态 ( s_0 ) 和开始符号 ( y_0 = \text{} )。
-
逐步解码:
- 在每一步 ( t ),解码器基于上一个单词的嵌入和前一隐藏状态来更新其状态:
- s t = RNN ( e ( y t − 1 ) , s t − 1 ) s_t = \text{RNN}(e(y_{t-1}), s_{t-1}) st=RNN(e(yt−1),st−1)
-
计算注意力分数:
-
对于每个解码步骤 ( t ),计算一个注意力分数 ( \alpha_{tj} ),表示输入序列中每个单词对当前步骤的重要性。
-
α t j = exp ( score ( s t , h j ) ) ∑ k = 1 n exp ( score ( s t , h k ) ) \alpha_{tj} = \frac{\exp(\text{score}(s_t, h_j))}{\sum_{k=1}^{n} \exp(\text{score}(s_t, h_k))} αtj=∑k=1nexp(score(st,hk))exp(score(st,hj))
-
其中,score可以是点积、加性或其他函数。
-
-
生成上下文向量:
- 上下文向量 ( c_t ) 是加权的隐藏状态总和,权重由注意力分数确定。
- c t = ∑ j = 1 n α t j h j c_t = \sum_{j=1}^{n} \alpha_{tj} h_j ct=j=1∑nαtjhj
-
预测下一个单词:
- 结合上下文向量 ( c_t ) 和当前隐藏状态 ( s_t ) 来生成下一个单词的概率分布。
- P ( y t ∣ y t − 1 , . . . , y 0 , X ) = softmax ( output_layer ( s t , c t ) ) P(y_t | y_{t-1}, ..., y_0, X) = \text{softmax}(\text{output\_layer}(s_t, c_t)) P(yt∣yt−1,...,y0,X)=softmax(output_layer(st,ct))
-
选择最可能的单词:
- 选择具有最高概率的单词作为 ( y_t )。
输出
- 这个过程重复进行,直到生成结束符号 ( \text{} ) 或达到最大长度,最终输出序列 ( Y = {y_1, y_2, …, y_m} )。
这个推导过程展示了如何从一个源语言序列生成一个目标语言序列,并且强调了注意力机制在解码过程中的关键作用,即帮助模型确定在生成每个目标单词时应该“关注”输入序列的哪些部分。
示例:基于点积的注意力机制
以下是用Python和PyTorch实现点积注意力机制的一个简单例子。这里假设我们已经有了编码器和解码器的隐藏状态。
import torch
import torch.nn.functional as F
def dot_product_attention(query, key, value):
# 计算注意力分数
scores = torch.matmul(query, key.transpose(-2, -1))
# 应用softmax获取权重
weights = F.softmax(scores, dim=-1)
# 计算加权和
output = torch.matmul(weights, value)
return output, weights
# 示例数据
query = torch.randn(1, 64) # 解码器的隐藏状态
key = torch.randn(10, 64) # 编码器的所有隐藏状态
value = torch.randn(10, 64) # 与键相同
# 计算注意力
output, weights = dot_product_attention(query, key, value)
这只是一个基础的实现,实际应用中可能会有更复杂的结构和步骤,比如多头注意力(Multi-Head Attention),它在Transformer模型中被广泛使用。多头注意力可以让模型同时从不同的表示子空间学习信息。
















 9793
9793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











