







##引言
近年来,深度学习模型在众多领域展现出卓越的性能,但随之而来的模型体积和计算成本的急剧增加,严重阻碍了其在资源受限环境中的部署。模型剪枝 (Model Pruning) 作为一种关键的模型压缩技术应运而生,旨在通过识别并移除模型中冗余或不重要的参数和结构,在维持模型性能的同时,显著降低模型的参数量、减少计算资源消耗并加速推理过程。模型剪枝不仅能够提升模型在移动设备、嵌入式系统等边缘端的部署效率,还能降低云端推理服务的成本。根据剪枝的粒度,模型剪枝算法主要分为非结构化剪枝 (Unstructured Pruning) 和结构化剪枝 (Structured Pruning),本文将深入探讨这两种主流剪枝方法的核心原理、关键技术和应用场景。
非结构化剪枝
原理:
非结构化剪枝的核心在于对模型中的单个权重进行精细化地稀疏化,即将模型中大量冗余的、对最终预测贡献较小的权重置为零。其核心步骤包括权重重要性评估、根据预设的剪枝率进行稀疏化以及后续的微调以恢复性能。
主要方法:
1. Magnitude Pruning (幅值剪枝):
作为最直观且广泛应用的非结构化剪枝方法[1],幅值剪枝直接根据权重的绝对值大小来判断其重要性。绝对值越小的权重被认为对模型的输出影响越小,因此更有可能被安全地移除。通常会设定一个全局或分层的剪枝率,然后将模型中绝对值最小的相应比例的权重置为零。
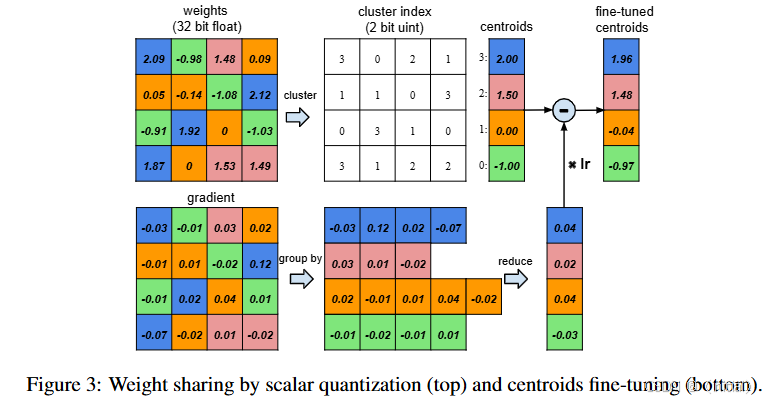
算法简述:
- 遍历模型中的所有可训练权重。
- 计算每个权重的绝对值。
- 根据预设的全局或分层剪枝率,确定需要剪除的权重数量。
- 将绝对值最小的权重置为零。
数学公式:
设神经网络的权重矩阵为
W
W
W,剪枝率为
p
p
p,则:
T
=
percentile
(
∣
W
∣
,
p
)
T = \text{percentile}(|W|, p)
T=percentile(∣W∣,p)
W
′
=
W
⊙
(
∣
W
∣
>
T
)
W' = W \odot (|W| > T)
W′=W⊙(∣W∣>T)
其中
⊙
\odot
⊙ 表示逐元素相乘,
T
T
T 为剪枝阈值。
代码示例(PyTorch 实现):
import torch
import torch.nn.utils.prune as prune
model = torch.nn.Linear(10, 5) # 线性层
prune.l1_unstructured(model, name="weight", amount=0.2) # 剪枝 20% 权重
实践考量: 虽然简单有效,但高度稀疏的权重矩阵在通用计算设备上可能无法直接带来显著的加速效果,因为需要特殊的稀疏矩阵运算库和硬件支持才能充分发挥其优势。
2. L1/L2 Norm Pruning (L1/L2 范数剪枝):
除了直接基于数值大小,还可以利用权重的范数来衡量其重要性。L1 范数 ( ∑ ∣ w ∣ \sum |w| ∑∣w∣) 倾向于产生更加稀疏的解,而 L2 范数 ( ∑ w 2 \sqrt{\sum w^2} ∑w2) 则更倾向于减小权重的整体幅度。在非结构化剪枝中,通常是对单个权重计算其 L1 或 L2 范数 (对于单个权重,两者本质上都是绝对值)。
算法简述:
对于每个权重,计算其 L1 或 L2 范数。
根据剪枝率,移除范数最小的权重。
3. Random Pruning (随机剪枝):
随机剪枝作为一种重要的基线方法,通过随机地将一部分权重置为零,用于评估其他基于重要性评估的剪枝方法的有效性。如果某种剪枝方法的效果明显优于随机剪枝,则可以认为该方法是有效的。
实践与工具:
主流深度学习框架如 PyTorch 和 TensorFlow 都提供了支持非结构化剪枝的工具和接口。例如,PyTorch 的 torch.nn.utils.prune 模块以及 TensorFlow Model Optimization Toolkit 提供了方便的 API 来实现不同类型的非结构化剪枝。
结构化剪枝
原理:
结构化剪枝着眼于移除模型中整个结构化的单元,如卷积神经网络的滤波器、通道或甚至整个层。这种方法能够直接减少模型的计算复杂度和参数量,并且产生的模型结构更加规则,更容易在各种硬件平台上实现加速。
主要方法:
1. 基于 Filter Norm 的剪枝:
该方法通过计算每个卷积滤波器 (filter) 的范数来衡量其重要性[2]。通常使用 L1 范数或 L2 范数,范数越小的滤波器被认为对模型的贡献越小,因此可以被安全地移除。
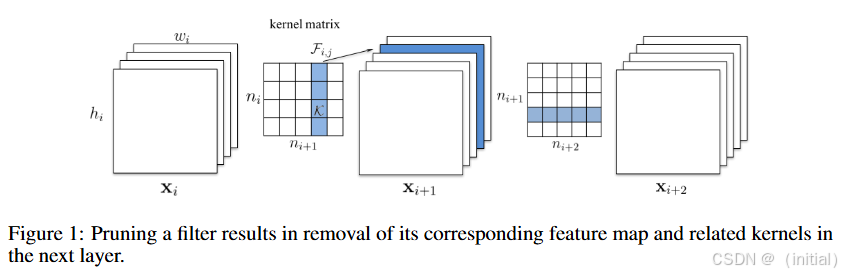
算法简述:
-
- 对于模型中的每个卷积层 l l l,假设其包含 n l n_l nl 个滤波器 { F l , 1 , F l , 2 , . . . , F l , n l } \{F_{l,1}, F_{l,2}, ..., F_{l,n_l}\} {Fl,1,Fl,2,...,Fl,nl}。
- 选择一个范数 (例如 L1 范数)。对于第 i i i 个滤波器 F l , i F_{l,i} Fl,i,其 L1 范数为 N ( F l , i ) = ∑ j , k , m ∣ F l , i ( j , k , m ) ∣ N(F_{l,i}) = \sum_{j,k,m} |F_{l,i}(j,k,m)| N(Fl,i)=∑j,k,m∣Fl,i(j,k,m)∣,其中 j , k , m j, k, m j,k,m 遍历滤波器中的所有权重。
- 根据预设的剪枝率 α \alpha α,确定需要移除的滤波器数量 k = ⌊ α × n l ⌋ k = \lfloor \alpha \times n_l \rfloor k=⌊α×nl⌋。
- 选择范数最小的 k k k 个滤波器进行移除。
- 移除滤波器后,需要同步移除其对应的输出特征图,并调整下一层卷积层的输入通道数,以保持模型结构的兼容性。
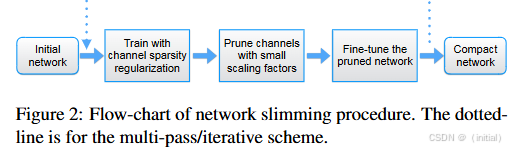
2. 基于 Slimming 的剪枝 (Network Slimming):
Network Slimming[3] 是一种优雅的结构化剪枝方法,它在训练过程中利用 Batch Normalization (BN) 层的 Scale 因子 (通常用
γ
\gamma
γ 表示) 来指示通道的重要性。通过在训练目标函数中加入对 Scale 因子的 L1 正则化惩罚项,可以使得一部分 Scale 因子在训练结束后接近于零。这些接近于零的 Scale 因子对应的通道以及相关的卷积核可以被安全地剪除。
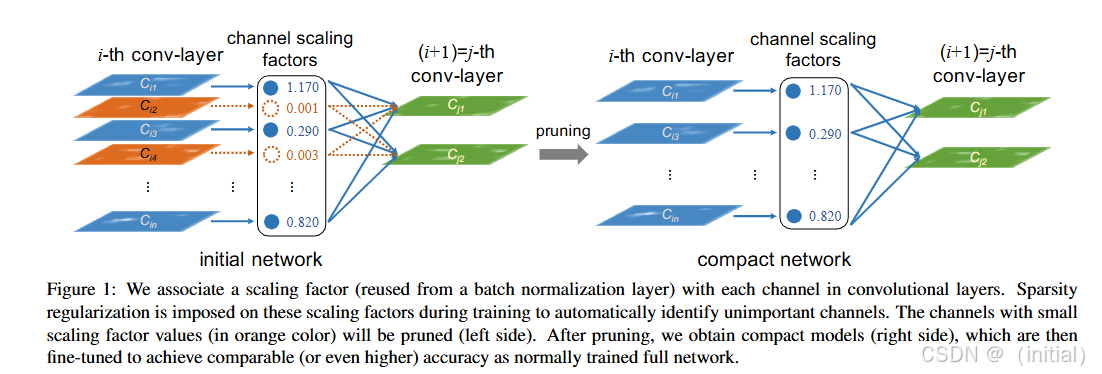
算法简述:
- 在训练神经网络时,对每个 Batch Normalization 层的 Scale 因子施加 L1 正则化。
- 训练完成后,识别出 Scale 因子绝对值较小的通道。
- 将这些不重要的通道以及它们在对应的卷积层中的卷积核剪除。
算法推导 (更深入的解释):
L1 正则化鼓励模型参数的稀疏性。在 Network Slimming 中,通过对 BN 层的 Scale 因子施加 L1 惩罚,模型在训练时会学习哪些通道对于减小损失是重要的。不重要的通道对应的 Scale 因子会趋向于零,表明这些通道的输出对后续的计算贡献很小,因此可以被安全地剪除,从而实现模型结构的瘦身。
3. 自动剪枝算法 (AutoPruner):
为了克服手动设计剪枝策略的困难,研究人员提出了自动剪枝算法。这些算法通常利用强化学习[4]或神经架构搜索 (NAS) 等技术来自动地搜索最优的剪枝策略,以在给定的约束条件 (如模型大小、计算复杂度) 下最大化模型的性能。
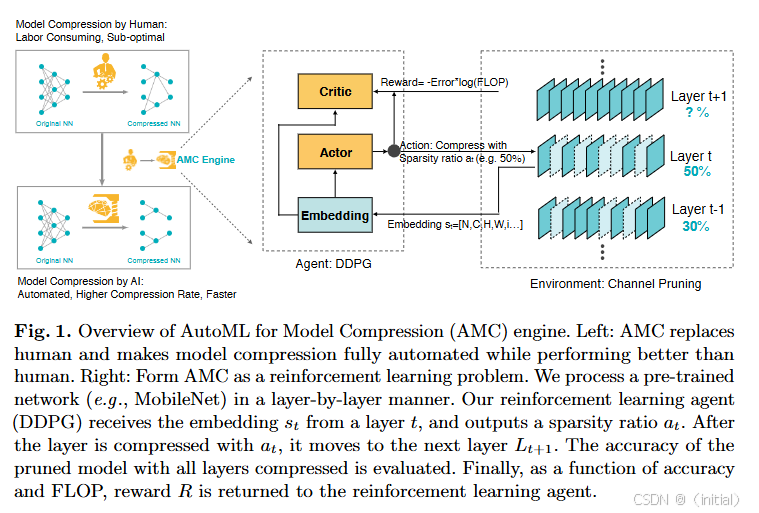
算法简述 (基于强化学习):
- 定义一个搜索空间,包含所有可能的剪枝决策 (例如,每个层可以剪除的滤波器或通道的比例)。
- 训练一个强化学习 Agent,该 Agent 通过与环境 (即待剪枝的模型) 交互来学习最优的剪枝策略。Agent 的状态通常包括当前模型的性能指标和结构信息。
- Reward 函数通常结合了剪枝后模型的性能 (例如精度) 和模型大小 (例如参数量或 FLOPs) 的考量,目标是找到一个在两者之间取得最佳平衡的剪枝策略。
- 通过不断迭代学习,Agent 能够找到一个有效的剪枝
策略。
自动剪枝算法 (基于神经架构搜索 - NAS):
在使用 NAS 进行剪枝时,通常会将剪枝率或要剪除的结构类型视为搜索空间的一部分。搜索算法 (如进化算法、基于梯度的搜索等) 会探索不同的剪枝配置,并在验证集上评估它们的性能 (通常是精度和模型大小的权衡)。通过迭代搜索,NAS 可以找到在满足特定资源约束下性能最优的剪枝模型结构。
剪枝后的模型微调与性能恢复
模型剪枝通常会导致一定的精度损失。为了弥补这种损失,通常需要在剪枝后对模型进行微调 (Fine-tuning)[5]。微调是指在剪枝后的稀疏模型上使用原始的训练数据或一个小的验证集继续进行训练。研究表明,合理的微调策略 (例如,使用较小的学习率、更长的训练轮数) 可以有效地恢复模型的性能。此外,迭代剪枝-微调是一种常用的优化策略,即多次进行剪枝和微调,逐步提高模型的稀疏率,同时保持较高的精度。值得注意的是,不同的模型架构对剪枝的敏感度不同,微调策略也需要根据具体的模型进行调整。Lottery Ticket Hypothesis[5] 进一步指出,在随机初始化的稠密网络中存在一些“中奖彩票”子网络,即使被随机初始化,也能在独立训练时达到与原始网络相当甚至更好的性能,这为剪枝后的微调提供了理论支撑。
剪枝算法选择与应用场景分析
选择合适的剪枝算法需要综合考虑目标模型的特性、硬件平台的限制以及对模型性能和大小的要求。常用的模型性能评估指标包括精度 (Accuracy)、推理速度 (Latency)、模型大小 (Number of Parameters/FLOPs) 等。
- 模型架构: 不同的模型架构可能更适合不同的剪枝方法。例如,对于计算量主要集中在卷积层的 CNNs,结构化剪枝 (如 Filter Norm pruning 或 Network Slimming) 通常能带来更直接的加速效果。而对于一些包含大量全连接层的模型,非结构化剪枝可能更有效。Transformer 模型由于其独特的自注意力机制,也有专门针对其结构的剪枝方法。
- 硬件平台: 不同的硬件平台对模型的稀疏性和结构化程度有不同的适应性。例如,一些专门的神经网络加速器对稀疏运算进行了优化,可以更好地支持非结构化剪枝。而对于通用的 CPU 和 GPU,结构化剪枝通常能带来更稳定的性能提升。在移动端和嵌入式设备上,模型的小尺寸和低功耗是关键需求,因此通常会采用高比例的结构化剪枝。
- 性能要求: 对模型精度要求较高的场景可能需要更保守的剪枝策略和更精细的微调。反之,对于一些对精度要求不高的场景,可以采用更激进的剪枝策略以获得更高的压缩率。
- 开发和部署的便利性: 结构化剪枝由于其产生的模型结构更加规整,在部署和推理优化方面通常比非结构化剪枝更加方便。
结论与展望
模型剪枝作为一种重要的模型压缩技术,在优化深度学习模型的效率方面发挥着至关重要的作用。非结构化剪枝和结构化剪枝各有其优势和适用场景。随着研究的不断发展,未来的模型剪枝技术将更加智能化和自动化,例如通过神经架构搜索和元学习等方法自动发现最优的剪枝策略,使得剪枝过程更加高效和易于使用。同时,硬件感知剪枝也将成为一个重要的研究方向,旨在根据目标硬件的特性进行定制化的剪枝,以实现最佳的性能和效率。此外,探索更细粒度的结构化剪枝 (例如 group-wise pruning) 以及将剪枝与其他压缩技术 (如量化和知识蒸馏) 相结合也将是未来的重要趋势。模型剪枝技术的进步将进一步推动深度学习模型在更广泛的领域得到应用。
内容同步在我的微信公众号: 智语Bot
参考文献
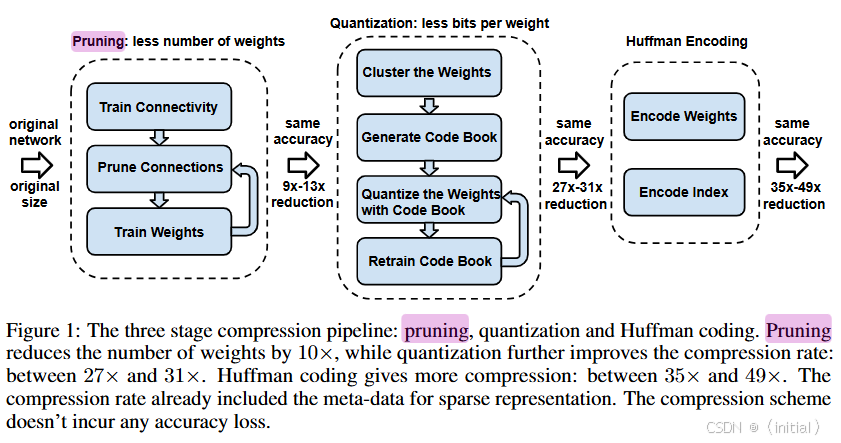
[1] Han, S., Mao, H., & Dally, W. J. (2015). Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
[2] Li, H., Kadiric, A., Benini, L., & Cavallaro, L. (2017). Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710.
[3] Liu, Z., Li, J., Shen, Z., Huang, G., Wang, S., & Wei, Y. (2017). Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE international conference on computer vision (pp. 2736-2744).
[4] He, Y., Lin, J., Wang, Z., Liu, H., Li, H., & Zhou, B. (2018). Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European conference on computer vision (ECCV) (pp. 784-800).
[5] Frankle, J., & Carbin, M. (2019). The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635.
。



















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











