







本次介绍一篇有关快速目标检测的文章《YOLO9000: Better, Faster, Stronger》。该方法记作YOLOv2,相比v1除了在性能上有所提升之外,更是在速度上表现惊人。
项目主页:http://pjreddie.com/darknet/yolo/
———————— Introduction ————————
通用的目标检测不但要够快够准,还要能够检测多类的目标。但实际情况是,目标检测数据集包含的类别数都太少,远远小于图像分类数据集所包含的类别数(比如ImageNet)。
于是,本文提出了一种联合训练的方法,可以同时利用检测数据集和分类数据集来训练目标检测器。具体思路是,利用目标检测数据集来学习目标的准确定位,用分类数据集来增加检测的目标类别数以及检测器的鲁棒性。
通过采用上述策略,本文利用COCO目标检测数据集和ImageNet图像分类数据集训练得到了YOLO9000,可以实时地检测超过9000类的目标。
———————— Better ————————
YOLOv1同Fast RCNN相比存在定位不准以及召回率不如Region Proposal方法等问题。因此,V2的主要目标就是在保持分类准确率的同时提高召回率和定位准确度。
为了做到又快又好,所以文章在简化的网络上采用了很多策略来提高性能,具体用的技术如下表:
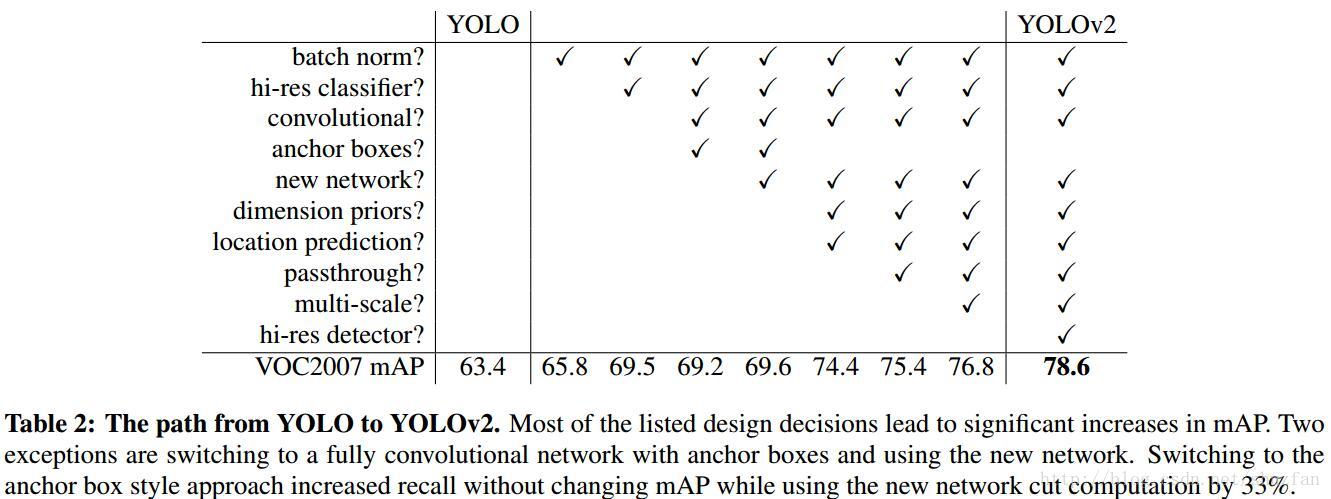
(1) Batch Normalization
BN可以加速收敛,同时BN也可以替代Dropout等正则化手段来防止网络过拟合。
(2) High Resolution Classifier
YOLOv1是在ImageNet预训练了一个输入为224x224大小的模型,当想要检测小目标时需要把图像resize到448x448,同时网络也要相应地进行调整。
为了适应较大的分辨率,YOLOv2以448x448的分辨率在ImageNet上预训练了10个epoch,然后将该预训练模型在检测数据上finetune,最终得到了 4% mAP的提升。
(3) Convolutional With Anchor Boxes
YOLOv1直接通过全连接层来预测bounding box的坐标,与Fast-RCNN相比有两个缺点:
一是只能预测98个框,数量太少,而Fast-RCNN在conv-map上每一个位置都可以预测9个框;二是预测坐标不如预测坐标相对偏移量有效,Fast-RCNN预测的是偏移量和置信度。
因此,YOLOv2移除了全连接层,并将网络输入由448调整为416,使得最后输出的feature map大小为13x13(416/32)。之所以要调整输入为416,是为了使得最后的输出size是一个奇数,这样就可以保证feature map只有一个中心。由于目标(特别是大目标)往往位于图像中心,因此一个正中心来预测位置要比4个要好。
通过在卷积层使用anchor boxes,网络可以预测超过1000个窗口,虽然这导致了准确率降低了0.3mAP,但是召回率却足足提高了7%。
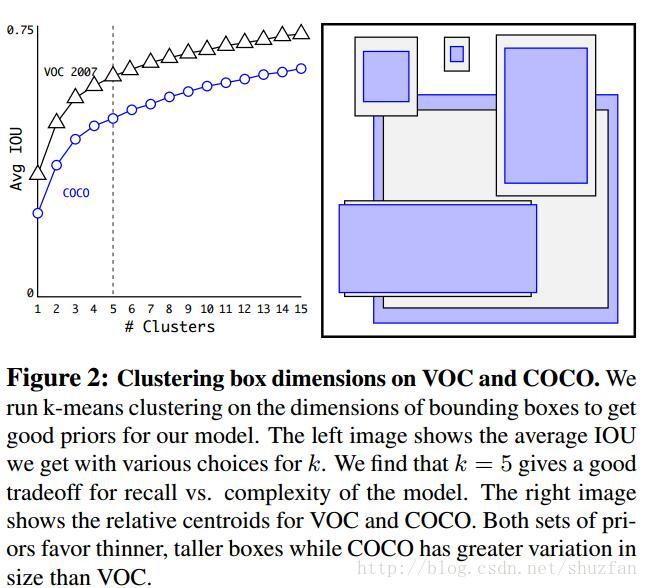
(4) Dimension Clusters
Fast-RCNN中使用3种scales和3中aspect ratios(1:1,1:2,2:1)在每个位置产生了9个anchor boxes。作者认为这种手动选取的anchor不够好,虽然网络最终可以学出来,但如果我们可以给出更好的anchor,那么网络肯定更加容易训练而且效果更好。
作者通过K-Means聚类的方式在训练集中聚出好的anchor模板。需要注意的是,在使用K-Means中如果使用传统的欧式距离度量,那么大的框肯定会产生更大的误差,因此作者更换为基于IOU的度量方式:
d(box,centroid)=1−IOU(box,centroid) 。
下表表明,基于K-Means的anchor box选取比手动选取效果好:
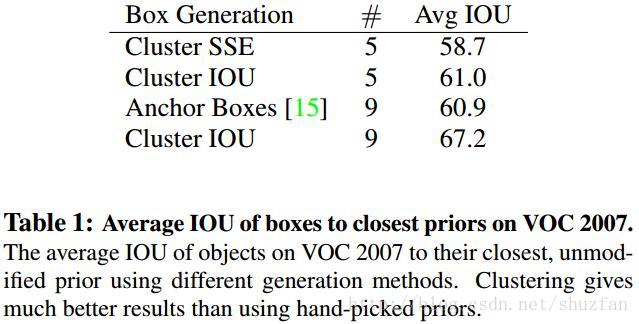
通过权衡速度与性能,作者最终选则聚5类时得到的anchor boxes。
(5) Direct Location Prediction
作者在训练中发现模型不稳定,特别是训练早期。这主要是由anchor box回归引起的,因为预测的是偏移量,这可能导致前期预测得到的框偏移到图像任何位置。
因此,作者采用了一种较强约束的定位方法,参见下图:
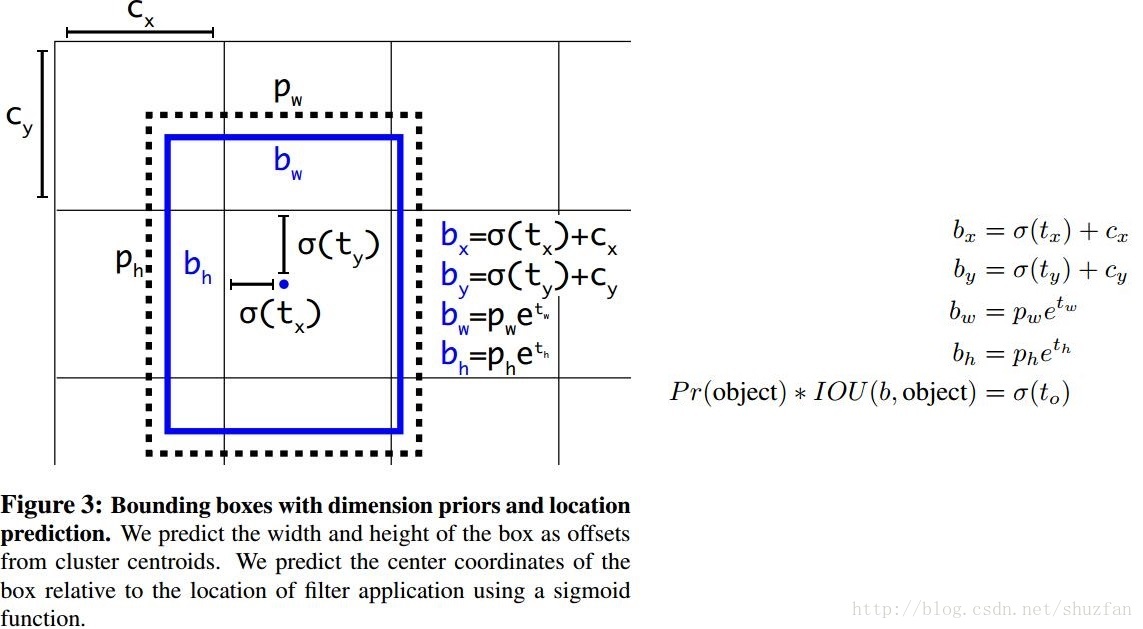
如上图,每个cell会预测5个bounding box,每个bounding box预测 tx,ty,tw,th,to 这5个参数。其中 tx,ty 经过sigmoid约束到 [01] ,因此预测出来的bounding box的中心点 bx,by 一定位于以 cx,cy 为左顶点的cell内。(其中, pw,ph 为anchor box的宽高)
(6) Fine-Grained Features
Faster F-CNN、SSD通过使用不同尺寸的feature map来取得不同范围的分辨率, YOLOv2则通过添加一个passthrough layer来取得上一层26x26的特征,并将该特征同最后输出特征相结合,以此来提高对小目标的检测能力。具体的做法是将相邻的特征堆积到不同channel中,从而将 26×26×512 的feature map变为 13×13×2048 的feature map。
(7) Multi-Scale Training
由于网络只有卷积和pooling层,因此实际上可以接受任意尺寸的输入,作者也希望YOLOv2对各种尺度的图片都足够鲁棒。
因此,训练过程中每迭代10个batch,都会随机的调整一下输入尺度,具体尺度列表为 320,352,…,608 。
当输入图片尺寸比较小的时候检测速度比较快,当输入图片尺寸比较大的时候则精度较高,所以YOLOv2可以在速度和精度上进行权衡。
———————— Faster ————————
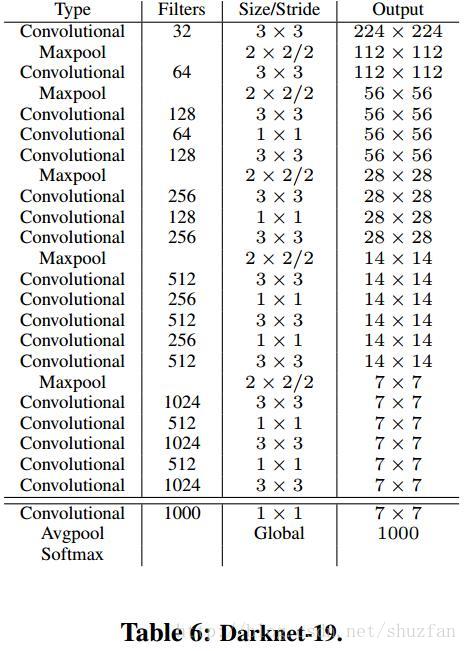
(1) DarkNet-19
为了提高性能同时加快速度,作者设计了一个带有19个卷积核5个max-pooling的网络,命名为Darknet-19。设计该网络时主要参考了VGG使用大量3x3卷积,参考NIN使用1x1卷积和avg-pooling,使用BN等。具体网络如下图:
(2) Training for classification
先在Imagenet(1000分类)上以224x224输入训练160 epochs,然后再更改输入为448x448继续finetune 10 epochs。(训练的具体设置参见原文)
(3) Training for detection
修改(2)预训练的网络的最后几层,然后在检测数据集上finetune。(具体怎么修改还是要参看原文和相关代码)。 以VOC的20类目标检测为例,最后的输出应该是 13×13×125 , 13×13 是feature map尺寸; 125=5×(20+5) 表示每个位置预测5个框,每个框有20个分类概率和5个boundingbox参数。
———————— Stronger ————————
前面提到过,作者同时使用检测数据集和分类数据集来训练多目标检测器。具体做法是,将两个数据集混合,训练时如果遇到来自检测集的图片则计算完整的Loss,如果遇到来自分类集的图片则只计算分类的Loss。
上面的想法实现起来会有一点问题,因为通常使用的softmax假定类间独立,而Imagenet(分类集)包含了100多种狗,COCO(检测集)就只有狗这一类。为了解决这个无法融合的问题,作者使用了multi-label模型,即假定一张图片可以有多个label,并且不要求label间独立。
(1) Hierarchical Classification
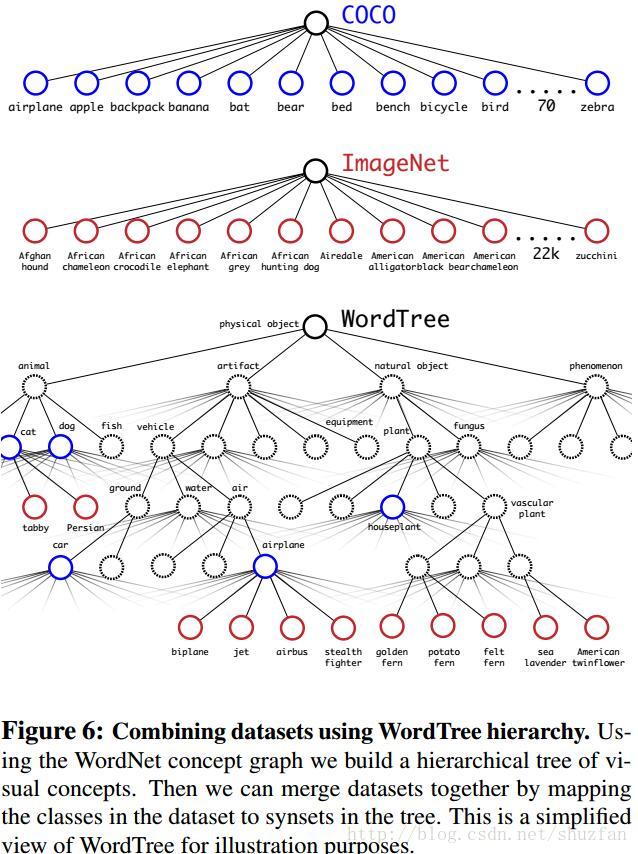
Imagenet中的类别是从WordNet(描述对象关系的一个语言集合)中选取的。WordNet是一种比较庞大的直线图结构,作者使用分层树的结构来对其进行简化。
具体地,遍历Imagenet的label,然后在WordNet中寻找该label到根节点(指向一个物理对象)的路径,如果路径只有一条,那么就将该路径直接加入到分层树结构中。然后处理剩余的具有多条路径的label,并将最短路径加入。
最终可以得到下图所示的分类树:
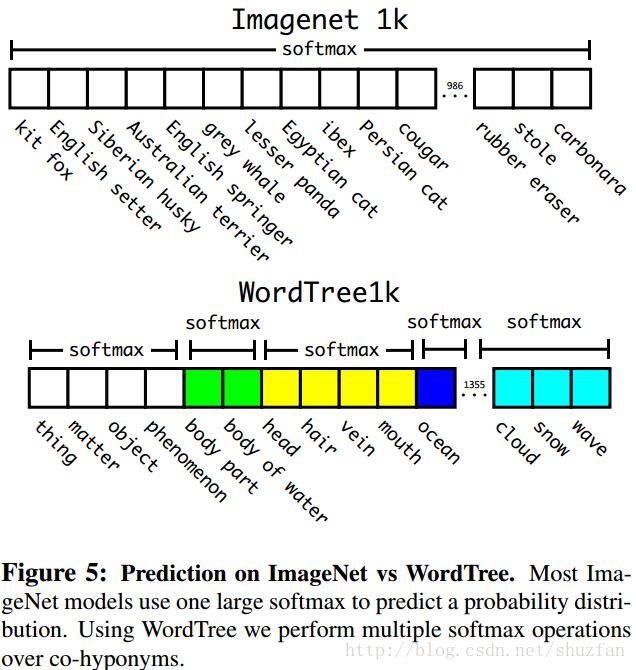
至于分类时的概率计算,大家应该可以很容易看出需要采用条件概率,即某个节点的概率值应当等于该节点到根节点的所有条件概率之积。而且,softmax操作也同时应该采用分组操作,如下图:
(2) Dataset Combination With WordTree
通过WordTree可以将不同的数据集合并使用。
(3) Joint Classification and Detection
最终制作了一个9418分类的WordTree,并且通过重采样保证Imagenet和COCO的数据比例为4:1。
对于检测数据集中的图片计算完整的Loss并反方向传播,对于分类数据集图片,则只计算分类的loss,同时假设IOU最少为 .3,最后根据这些假设进行反向传播。
———————— Conclusion ————————
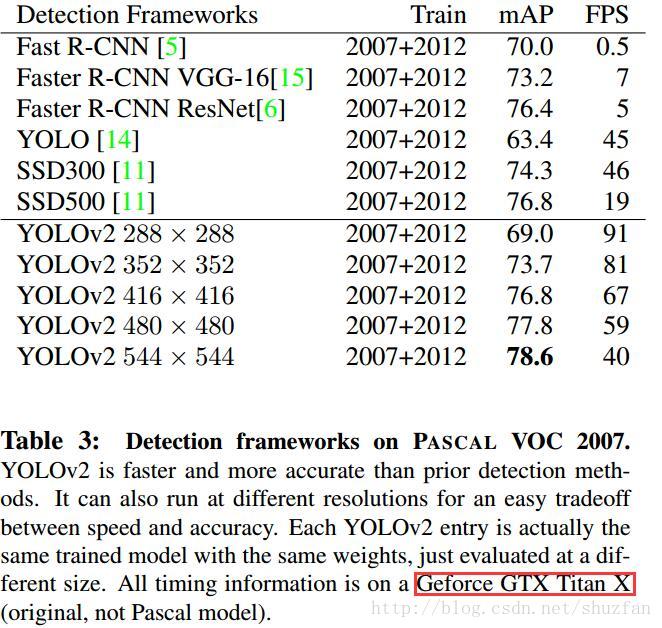
没什么好总结的,最后放一张速度对比图吧。















 2613
2613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









